





东南大学知识图谱课程准备的事件抽取论文分析。
What the role is vs. What plays the role: Semi-supervised Event Argument Extraction via Dual Question Answering —— 论文阅读笔记

0. 摘要
事件参与者提取是事件抽取的一项基本任务。本文重点解决在缺乏资源的情况下进行事件参与者提取。本文提出的 DualQA 模型,将事件参与者提取任务建模为问答,构建两种问答语句:”目标起了什么作用“ 和 ”目标的角色是什么“,分别构建两种模型,并相互提升效果,最后将两种模型进行结合,实现低资源场景下的事件参与者提取。
1. 引言
事件抽取 EE 通常被划分为两阶段任务,包括事件检测 ED 和事件参与者提取 EAE。当前主要挑战在于事件参与者提取。事件参与者提取的目标是提取事件相关参与者,并根据事件模式预测它们的角色。即事件参与者识别 EAR 和事件角色识别 ERR。
当前方法主要采用贴标签方法,将角色作为标签,进行监督学习。这种情况下模型无法理解标签的语义信息,降低了效果。另一方面,事件抽取数据较少,影响了训练效果。
本文提出的框架 DualQA,是一种基于问答的半监督事件参与者提取方法。该框架中,利用问答,构建两种模型来实现 EAR 和 ERR,实现对角色语义的理解。两种模型能够互相验证,共同增强。两种模型共享同一个问题理解模块,从而实现共享参与者。通过上述方式,实现低资源场景下的半监督事件参与者提取学习,并降低误差传播。
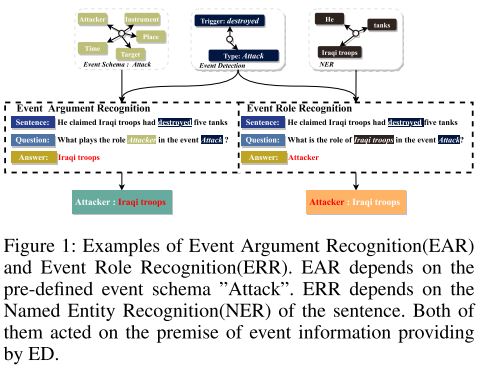
- 图1:EAR 和 EER 示意图。EAR 取决于事件的模式“攻击”,ERR 取决于命名实体识别。两个子任务都是以 ED 提供的信息作为基础。
- 样例:EAR 过程,给定角色“攻击者”,生成问题“谁在攻击事件中扮演攻击者的角色?”,获取参与者“伊拉克军队”。EER 过程,给定参与者“伊拉克军队”,生成问题“伊拉克军队在攻击实践中的角色是什么?”,获取角色“攻击者”。
2. 方法
2.1 双重模型设计
模型包括 EAR 模型和 ERR 模型。

- 图:输入。包括事件提及、事件触发信息、事件类型。这三个内容被结合为了上下文信息 C。可以看到,EAR 和 ERR 都是要求条件概率,且共享同一个上下文信息,在这个基础上互为逆向任务。
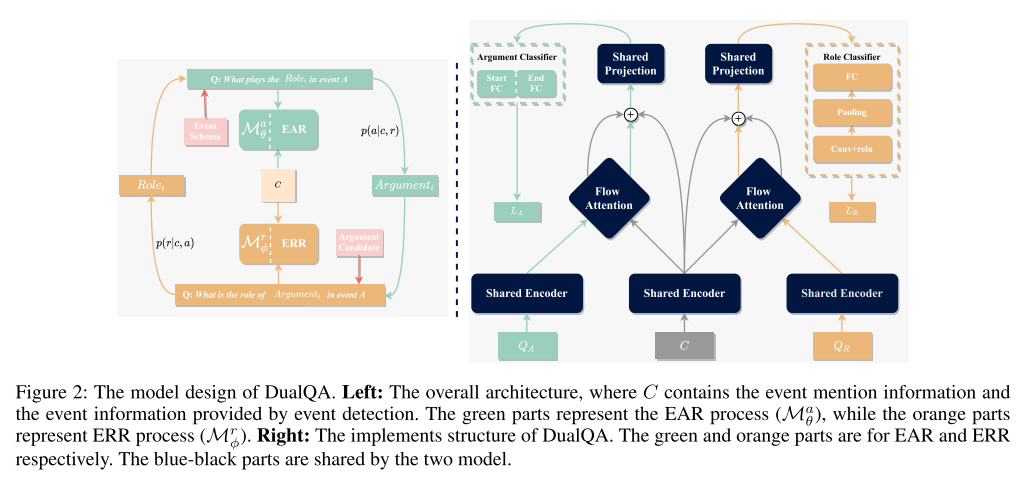
- 图2:模型架构。
- 左侧为整体架构。中间的 C 提供了事件提及信息和事件检测的事实信息。绿色是 EAR,橙色是 ERR。
- 右侧为执行过程。绿色是 EAR,橙色是 ERR,中间是共享模块。
2.2 问题生成

- 图:生成两种问题。"What plays the role xr in xts?" 和 "What is the role of xa in xts?"
2.3 实例编码
编码是基于 BERT 的。
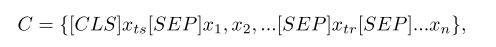
- 公式:上下文信息。
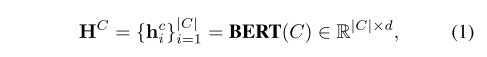
- 公式1:事件上下文到隐藏层表示。
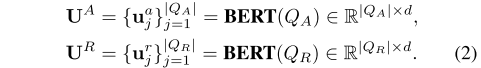
- 公式2:EAR 和 ERR 的问题文本编码,采用同一种编码器,以实现参数共享。
2.4 流注意力模块
流注意力模块主要用于结合问题和上下文,并在上下文中为每个单词生成一组查询感知特征向量。流注意力包含两个方向,C2Q 和 Q2C。
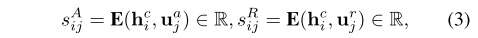
- 公式3:上下文单词和问题单词的相似度计算方式。
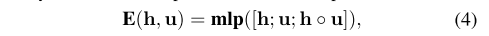
- 公式4:输入向量相似度模块计算方法,采用了多层感知机。
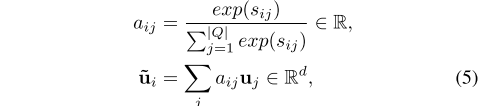
- 公式5:C2Q 注意力计算。
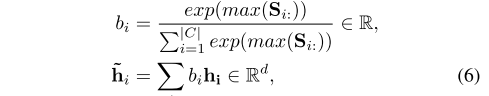
- 公式6:Q2C 注意力计算。

- 公式7:查询表示向量计算方法。用了多层感知机。
2.5 参与者分类器
将查询表示向量输入到参与者分类器中,获取参与者开始和结束跨度。
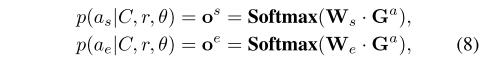
- 公式8:预测参与者的跨度是开始还是结束。
2.6 角色分类器
将查询表示向量输入到角色分类器中,获取角色概率分布。
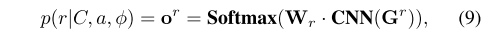
- 公式9:预测角色类型,采用简单的
2.7 半监督双重学习策略
半监督双重学习策略包含两步:
- 训练模型。
- 使用模型标记数据。
两步循环进行,直到数据耗尽或模型收敛为止。
2.8 联合训练
联合训练过程中,EAR 和 ERR 模型同时进行训练。联合训练目标函数。

EAR 模型目标函数。
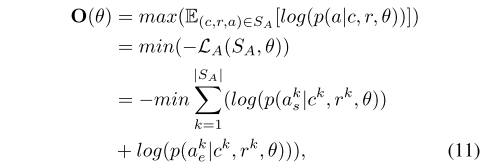
ERR 模型目标函数。
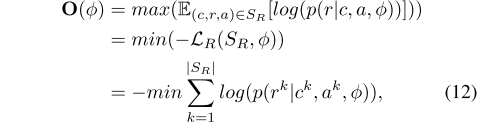
2.9 标记数据
联合训练后,会得到具有一定能力的 EAR 和 ERR 模型。接下来要用两个模型进行未标记语料的标记数据。
标记数据过程,首先用 ERR 根据 C 生成一个 a,根据 C 和 a,使用 EAR模型 获取角色 r,随后再将 C 和 r 作为参与者,用 ERR 模型获取参与者 a,并比较 a 来进行检查,判断是否是可信的标记。递归循环,直到数据耗尽或模型收敛。

3. 实验
数据集:
- ACE 2005:广泛评价事件抽取系统。
- FewFC:中文金融领域事件抽取。
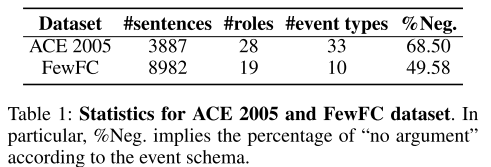
- 表1:数据集。
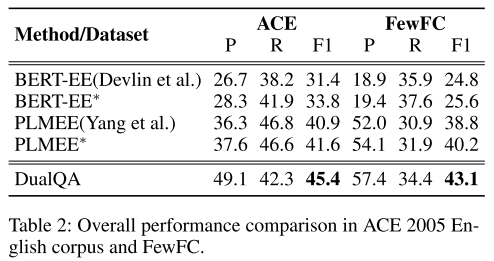
- 表2:总体性能表现。
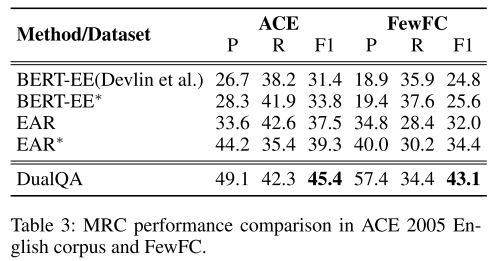
- 表3:机器阅读理解表现。
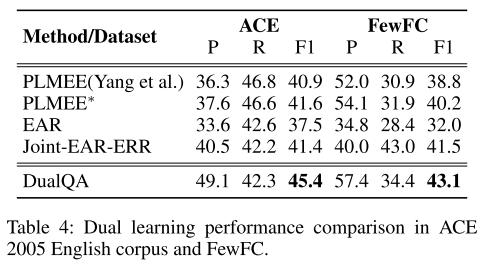
- 表4:双重学习效果表现。
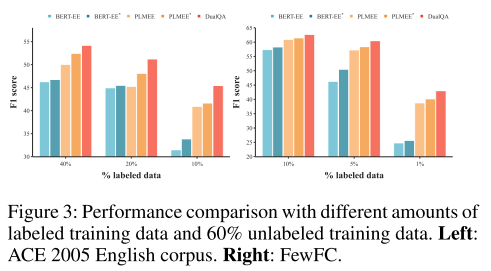
- 图3:全部标记数据和 60% 未标记数据的事件参与者抽取效果。60% 未标记数据效果更好,体现了双重学习的重要性。
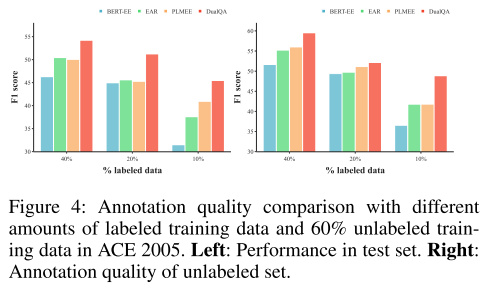
- 图4:全部标记数据和 60% 未标记数据的标记质量。60% 未标记数据效果更好,体现了双重学习的重要性。
4. 相关工作
机器阅读理解将传统的自然语言处理任务转换为问答任务,能起到很好地效果。
双重学习,可以利用原始任务和双重任务的二重性,使两种模型互相提高彼此的能力。
5. 结论
本文采用的方法包括:
- 将传统的自然语言处理任务转换为问答任务。
- 双重学习。
效果很好。
Span-Based Event Coreference Resolution —— 论文阅读笔记
0. 摘要
本文研究了基于跨度的事件链接解析模型。主要关注三点内容:
- 实体链接模型可以扩展到事件链接模型。
- 跨任务一致性约束可以指导基于跨度的事件链接模型的学习。
- 自动计算的实体链接信息对于基于跨度的事件指代模型解析十分有帮助。
1. 引言
事件链接比实体链接更具有挑战性。
标准信息抽取管道模型步骤:
- 通过实体提取组件,获取实体,并确定对应的本体。
- 通过事件提取组件,识别事件的触发词、短语,并确定参与者。
- 使用实体和事件模型,确认事件链接。

- 图:事件链接样例。只有 ev1 和 ev5 指代的同一个事件,其他的发生在不同事件。
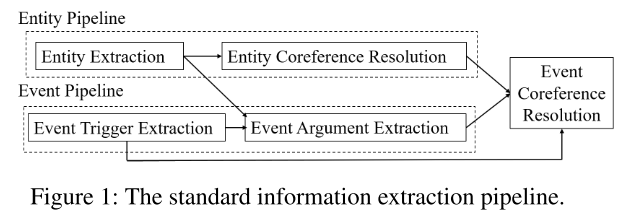
- 图1:标准信息抽取管道模型。
2. 相关工作
2.1 事件链接模型和特征
模型可以分为管道模型和联合模型。
特征包括四类:词汇特征、语义特征、参与者特征和话语特征(话语特征样例:两个事件的句子和令牌距离)。
本文采用的是联合抽取模型,特征用的是预训练嵌入。
2.2 应用于事件链接的跨任务约束
事件链接包含多种任务,包括:触发词检测、参与者检测、事件链接等。对多种任务可以采用跨任务约束,例如:触发词检测和事件链接所对应的事件必须是同一类型的。可以通过结构化 CRF 等方法实现联合模型的跨任务约束。
2.3 通过实体链接信息进行事件链接
此前研究表明,实体链接有助于事件链接。
3. 基线模型
基线模型是一个联合模型。同时学习两个任务:触发词检测和事件链接。
3.1 模型结构
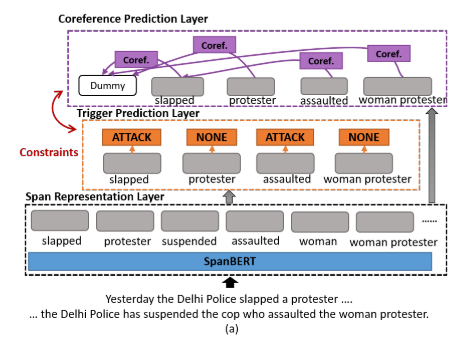
- 图a:模型结构。
3.1.1 跨度表示层
首先将文章拆分,随后基于 SpanBERT-large 进行上下文编码,将跨度表示 g 设置为:hstart, hend, hhead, fi,分别代表开始和结束跨度的隐藏层表示,基于注意力的头向量,跨度宽度特征嵌入。根据跨度表示,获取跨度得分。
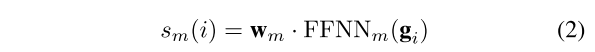
- 公式2:跨度得分计算公式。FFNN 是一个前馈神经网络。
3.1.2 触发词预测层
通过前馈神经网络,求得触发词得分。
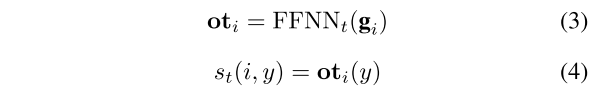
3.1.3 链接预测层
求得链接得分。
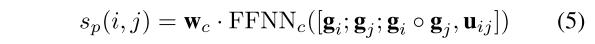
3.2 训练过程
损失包括事件链接损失和触发词检测损失。
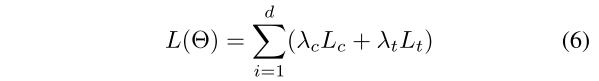
- 公式6:整体损失。
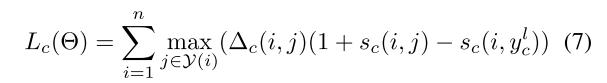
- 公式7:事件链接损失。
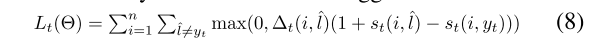
- 公式8:触发词检测损失。
4. 合并一致性约束
触发词检测包含三种错误:没有检测到触发词、错误标记触发词、触发词类型识别错误。
在基线模型的基础上,加入了触发词检测和事件链接的一致性约束,包括:
- 如果两个事件跨度没有相同的事件类型,则不能构建事件链接。
- 如果跨度的事件类型为 none,则前提必须为虚拟前提。
由于训练过程有噪声,因此不能将它作为硬约束,而要作为一个附加项,也就是软约束。将约束损失编码为两个约束被违反的次数,将约束损失乘以超参数,实现一致性约束。
5. 利用实体链接信息
5.1 管道模型
加入实体链接的基线模型,将实体链接模型作为额外输入,输入到事件链接模型中。实体链接模型也有三层,跨度表示层,实体提及预测层和实体链接层。那么,怎么将实体链接和事件链接联系起来?很简单,添加一个硬约束:如果两个事件链接相应的参与者之间没有实体链接,那么它们不能建立事件链接。通过这一方法修剪链接。
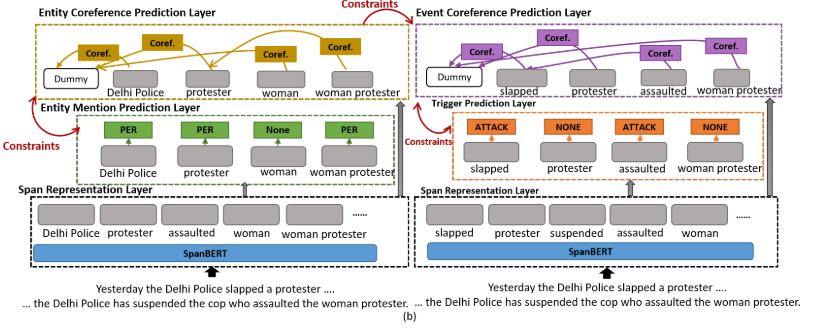
- 图b:管道模型。
5.2 联合模型
管道模型的实体链接和事件链接的交互不够紧密。因此采用联合模型加强联系。联合模型最主要是将最开始的跨度表示层是共同学习的,由两个任务共享:实体链接和事件链接。另一个区别在于损失函数采用联合损失函数。
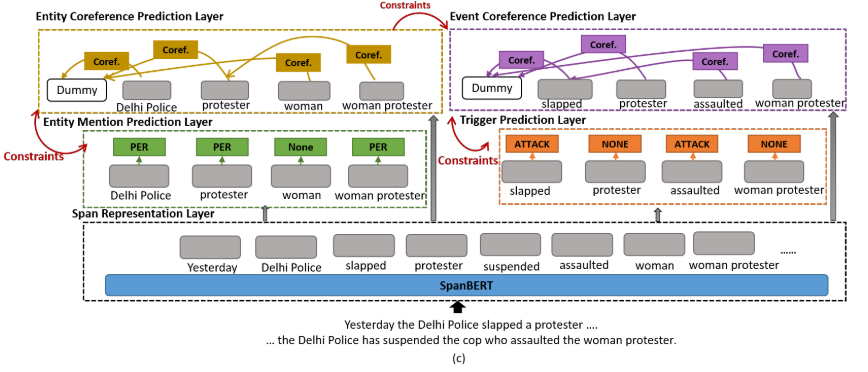
- 图c:联合模型。
6. 实验结果
数据集:
- TAC KBP :LDC2015E29, E68, E73, E94。
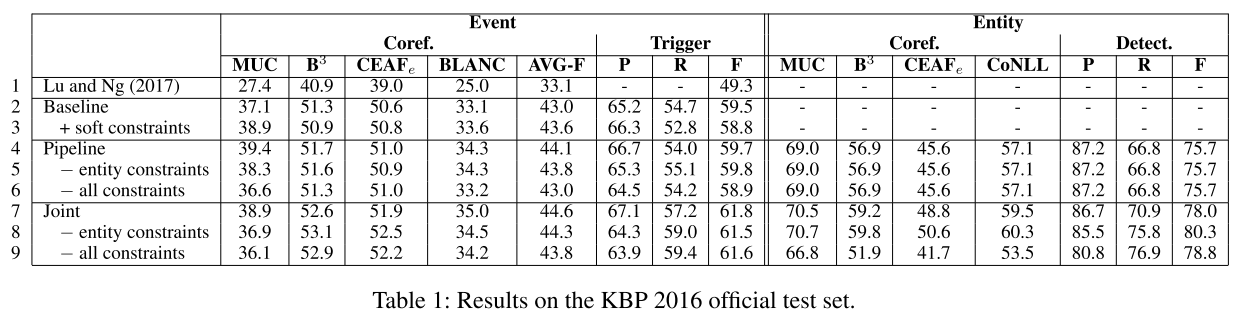
- 表1:KBP2016 数据集结果。
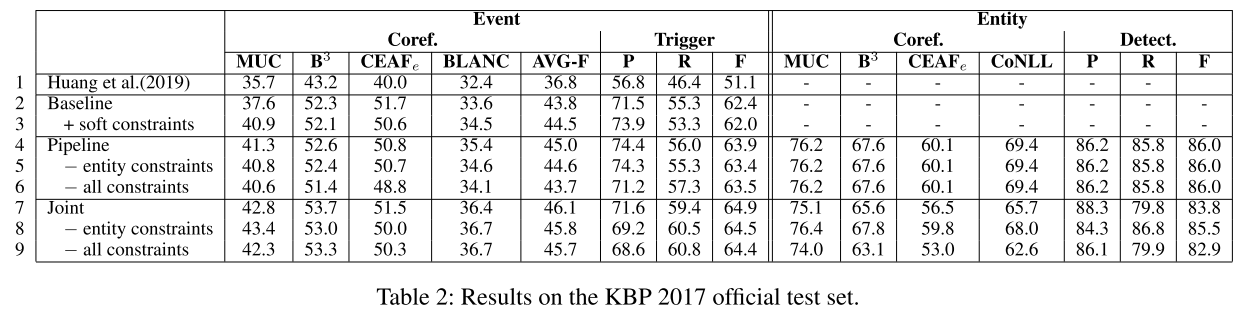
- 表2:KBP2017 数据集结果。
7. 误差分析

- 表3:误差分析。主要错误在于,将两个没有事件链接的参与者链接到了一起。
8. 结论
本文采用的方法包括:
- 联合学习模型。将实体链接和事件链接联系了起来。
- 合并一致性约束。将触发词检测和事件链接两个子任务联系了起来。
- 跨度表示。将跨度应用在事件抽取中,是第一个基于跨度的事件抽取模型。
GATE: Graph Attention Transformer Encoder for Cross-lingual Relation and Event Extraction —— 论文阅读笔记
0. 摘要
本文关注跨语言的句子级关系和事件抽取,长距离依赖建模。本文提出的 GATE 框架,采用图卷积神经网络 GCNs 来学习语言无关的句子,并采用自注意力机制来学习具有不同句法距离的单词间的依赖关系。本文在 ACE05 数据集上采用英语、中文和阿拉伯语检验跨语言效果,结果很好。其实没有采用特别新的想法。
1. 引言
本文建议,将依赖结构嵌入上下文表示。所谓依赖结构就是用句子结构取代传统的序列结构。好处包括:
- 两个词的句法距离远远小于序列距离。
A fire in a Bangladeshi garment factory has left at least 37 people dead and 100 hospitalized,其中fire和hospitalized的句法距离为 4,序列距离为 15。 - 依赖结构可以避免不同语言的语序不同带来的问题。
解决方法是采用 GCNs,但 GCNs 模拟长距离依赖时效果不佳,因此还需要使用自注意力机制来捕获长距离依赖关系。通过将两者结合,能够较好实现跨语言抽取。
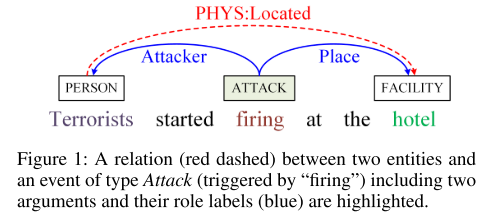
- 图1:实体关系(红线)和事件(蓝线)示意图。
2. 任务描述
关系抽取和事件提取。
零射跨语言转换:在一种或多种源语言模型上训练关系提取和事件抽取模型,然后在目标语言部署模型。包括四步:
- 将句子转换为通用的依赖解析器的树状结构。
- 将单词嵌入到跨语言表示空间中。
- 通过单词表示,基于 GATE 框架利用句法深度和距离信息对输入句子进行编码。
- 分类器根据编码预测关系和事件。
3. 方法
3.1 Transformer 编码器
本文采用 Transformer 注意力编码器和 GCNs 结合,以实现长距离依赖的捕获。


- 公式1,2:Transformer 注意力计算公式。
3.2 GAT 编码器
通过掩模算法,计算单词之间的句法距离矩阵。
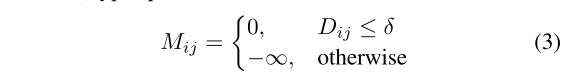
- 公式3:根据句法距离矩阵获取最短距离。
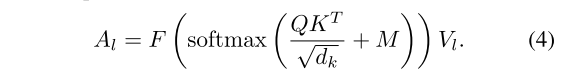
- 公式4:加入句法距离的注意力。
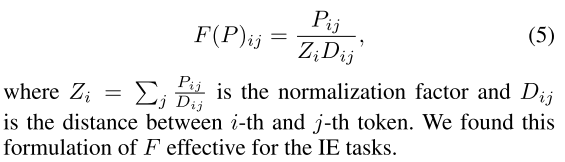
- 公式5:加入句法距离的注意力矩阵。
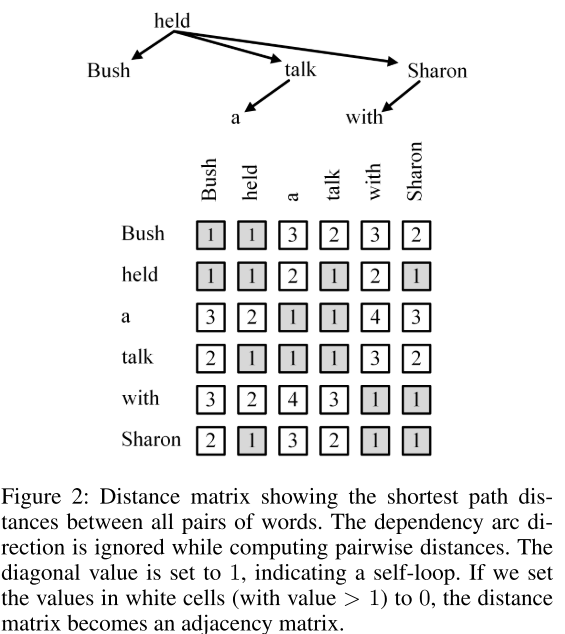
- 图2:句法距离矩阵
3.3 关系抽取器
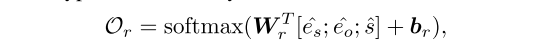
- 公式:分类器。
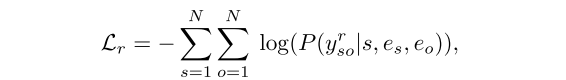
- 公式:由于是分类问题,采用交叉熵损失。
3.4 事件提取器

4. 实验
数据集:ACE 2005。采用英语、中文、阿拉伯语三个语料库。
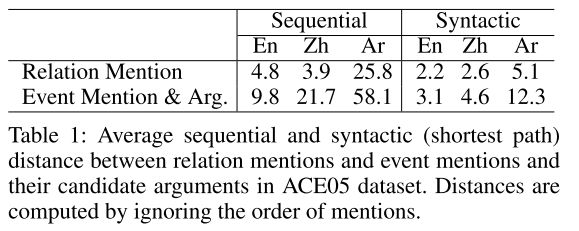
- 表1:数据集。

- 表2:单源语言模型转换实验结果。
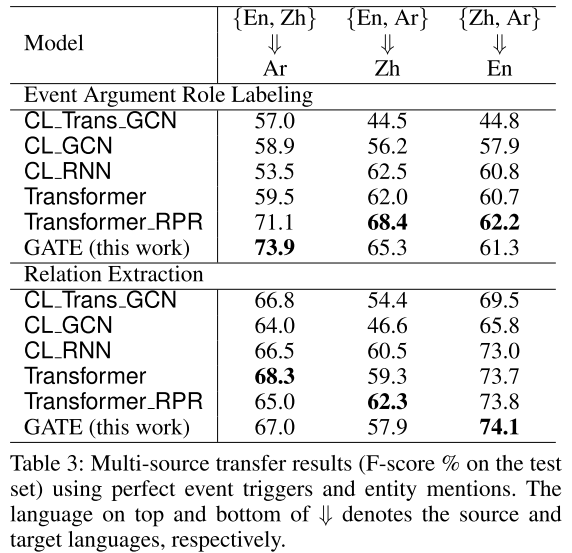
- 表3:多源语言模型转换实验结果。
5. 结果分析
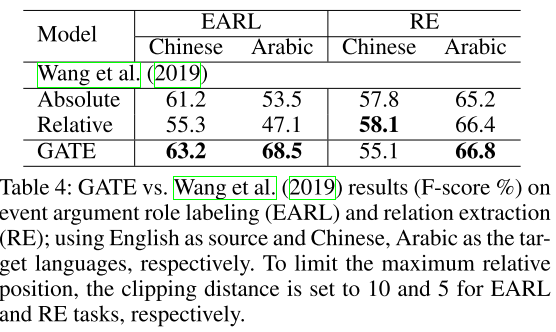
- 表4:模型对比。
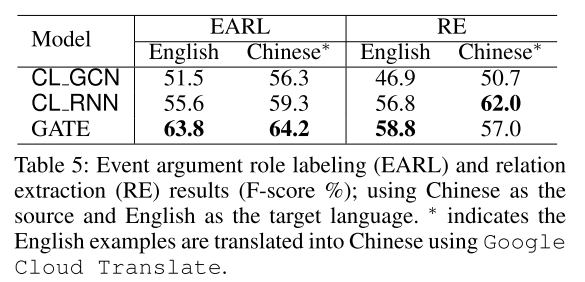
- 表5:单源语言模型转换影响因素分析。

- 图3:句子结构差异。

- 表6:单源语言模型转换影响因素分析。
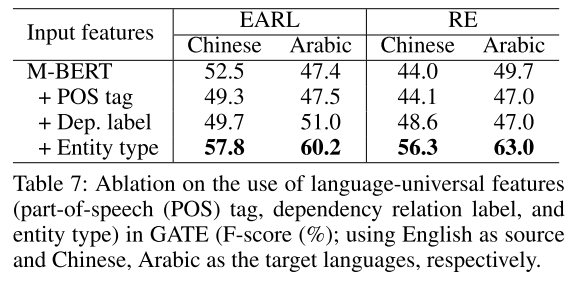
- 表7:消融实验结果。实体类型对模型贡献最大。
6. 相关工作
跨语言转换进行关系和事件抽取。
7. 结论
跨语言转换进行关系和事件抽取研究较多,GCNs 是很适合的模型,但难以模拟长距离依赖。本文采用的 GCNs 和 Transformers 结合的方式提高了效果。
Towards Open Domain Event Trigger Identification using Adversarial Domain Adaptation —— 论文阅读笔记
0. 摘要
本文目标在于解决跨领域事件抽取问题,采用 ADA 框架,提升跨领域训练效果。在英文文献和新闻数据集上体现了跨领域事件抽取效果的提高。对数据进行精细处理后效果进一步提高。
1. 引言
事件存在领域的特点,例如医疗事件和金融事件是完全不同的,因此领域数据不能推广到其他领域。两种事件提取器:监督学习事件提取器和句法规则事件提取器,前者不能推广到其他领域,后者会错误将名词和动词组合成事件(过度预测事件)。
本文主要考虑如何将宝贵的领域注释数据集推广到其他领域,改进泛化效果,同时不过度预测事件。对此,本文采用了 对抗领域适应 ADA 框架,该框架采用对抗训练进行表示学习,表示结果有助于触发词预测,而对领域样例预测没有帮助。该框架不需要标记的领域数据,是无监督学习模型。ADA 能使监督学习模型对领域外数据进行更稳健的预测,提升预测效果。
2. 处理开放领域事件触发器标识
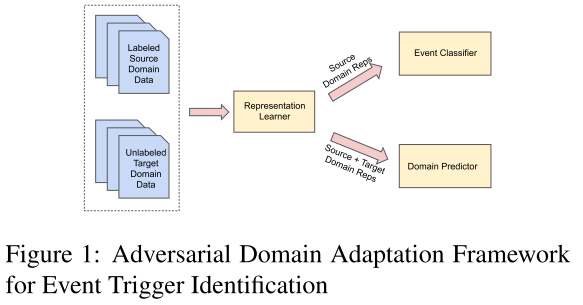
- 图1:模型框架。左侧是标记数据和未标记数据,中间是表示学习模型 R,右上是事件分类器 E,右下是领域预测器 D。
2.1 对抗领域适应
ADA 框架包括三部分:
- 表示学习模型 R。
- 事件分类器 E。
- 领域预测器 D。
由于要采用 ADA 模型进行表示学习,表示结果有助于触发词预测,而对领域样例预测没有帮助,因此目标领域的数据不需要标记。
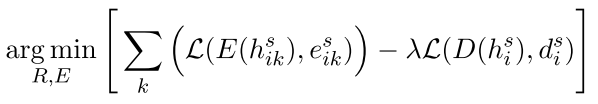
- 公式:第一阶段,表示学习模型 R 和领域预测器 D 损失函数。
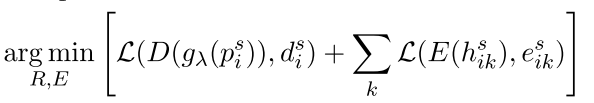
- 公式:第二阶段,表示学习模型 R 和事件分类器 E 损失函数。
2.2 表示学习模型
采用了 LSTM, BiLSTM, POS 和 BERT 模型。
3. 实验
数据集:
- LitBank:学术数据集。
- TimeBank:新闻数据集。
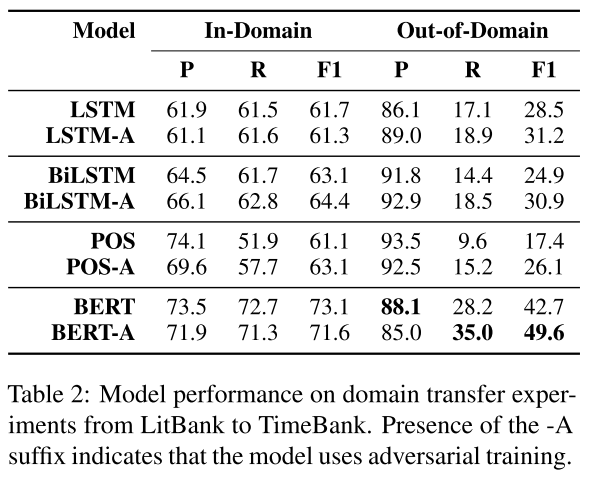
- 表2:LitBank 到 TimeBank 模型性能。-A 表示使用了 ADA 框架。
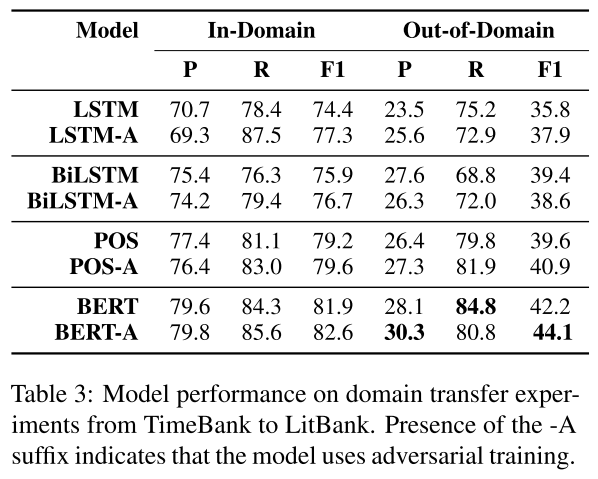
- 表3:TimeBank 到 LitBank 模型性能。
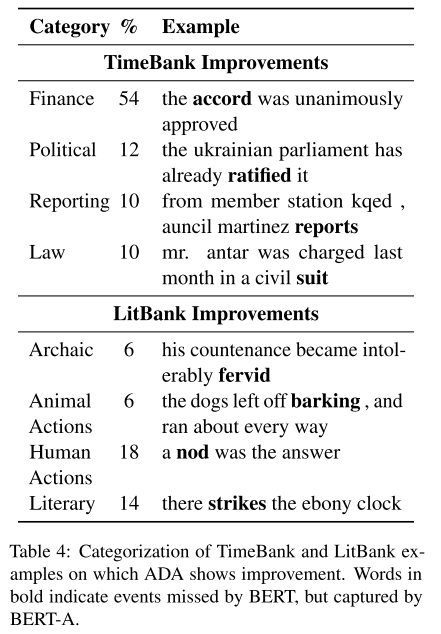
- 表4:ADA 改善的 TimeBank 和 LitBank 实例。
4. 纳入最小标记数据
研究少量标记目标领域数据对模型性能是否有改善效果。
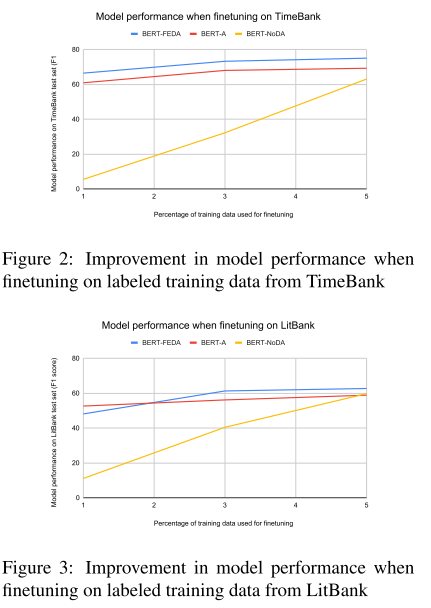
- 图2, 3:少量标记目标领域数据对两个数据集的改善效果。可以看到,提供少量标注就可以显著提高模型效果。这说明 ADA 降低了模型对数据量的需要。
5. 结论
对抗领域适应 ADA 框架使得监督模型对领域外数据表现更加稳健。无监督学习有助于在缺少监督数据时提高跨领域事件抽取效果。
Discourse as a Function of Event: Profiling Discourse Structure in News Articles around the Main Event —— 论文阅读笔记
0. 摘要
本文主要研究文章语言结构对事件抽取的影响。构建了一个包含 802 个新闻文章的数据集,并通过实验验证了语言结构对事件链接的影响,进一步利用语言结构使模型取得了更好的效果。
1. 引言
文章(新闻文章)不仅包含了主要事件,还有许多上下文信息,包括事实,背景,陈述,预测,评价等等。本文构建了一个新任务和新数据集,用于分析新闻话语结构和主要事件的关系。数据集包含 NYN, 新华社和路透社的 802 篇新闻,将句子分为 8 类,通过训练话语分类标注器进行标注。最后,分析了内容结构和核心事件的关系,并将这部分内容与事件链接相结合,分析了不同内容上事件链接的效果。最后实验结果体现新闻话语分析能够提高事件链接效果。
2. 相关工作
新闻话语分析此前主要是理论研究,少数实践并没有使用很好的话语分类标注器。
3. 话语剖析要素

- 表1:八种细粒度内容类型的实例。包括:主要内容包括:主要事件 M1、结果 M2,上下文内容包括:背景事件 C1、当前上下文 C2,附加支持内容包括:历史事件 D1、轶事事件 D2、评价 D3、预期 D4。
本文还将句子划分为两大类:人类表述的内容 speech 和其他内容 not speech。对每个句子都分配一个二进制标签,标记是否为人类表述的内容 speech。所有 speech 都标记为内容类型 C。轶事内容 C2 用来标记无法验证的内容。主要事件 M1 包含事件的前导语句。
4. 数据集创建和统计
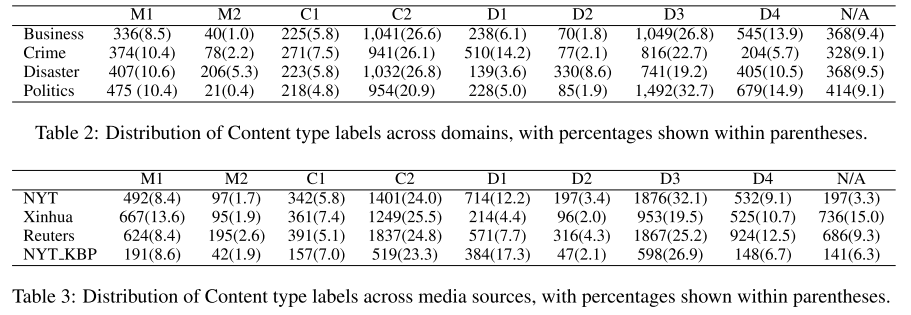
- 表2, 3:内容和媒体的句子分类统计情况。
5. 话语剖析的文献级神经网络模型
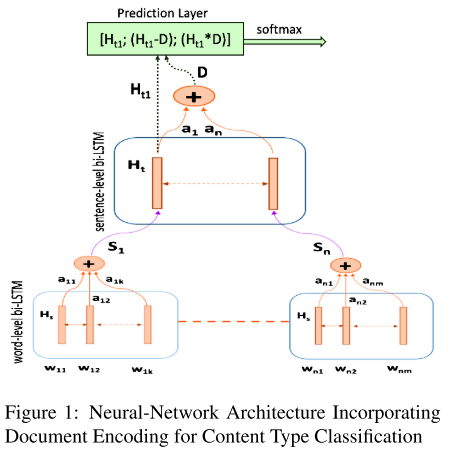
- 图1:模型架构。最下方是单词级的 BiLSTM 层,学习单词表示,将结果进行聚合生成句子表示。中间是句子级的 BiLSTM 层,学习文章表示,生成文章表示。BiLSTM 层都结合了注意力机制。最后预测层利用句子表示预测句子内容类型,预测层还结合了 CRF 模型,模拟话语标签之间的依赖性。
6. 分析
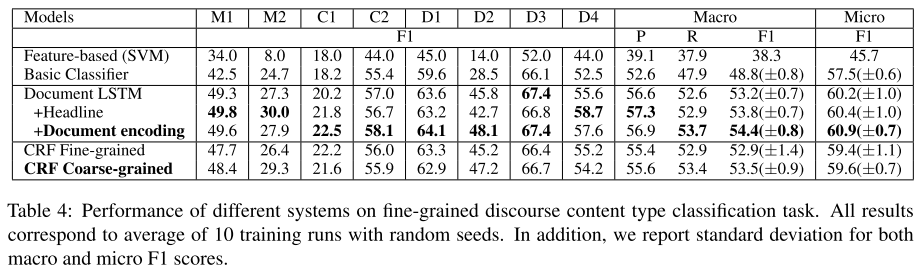
- 表4:不同系统在细粒度话语内容类型分类任务上的表现。
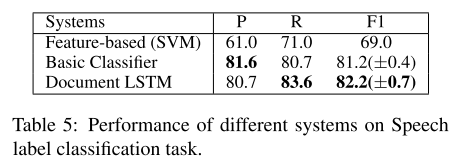
- 表5:不同模型在 speech 标签分类任务表现。
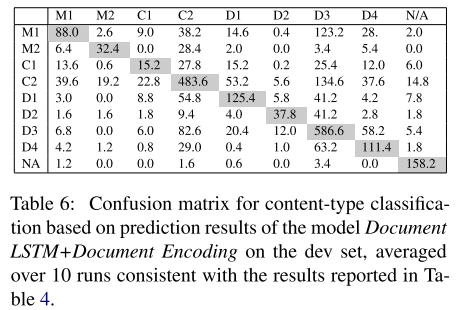
- 表6:分类混淆矩阵。
7. 利用内容结构提高事件链接效果

- 表7:每种类型中出现事件的百分比。

- 表8:每种类型中含标题的事件出现的百分比。

- 表9:类型内事件的百分比。类型内事件就是在某一类型开始,也在同样的类型结束。
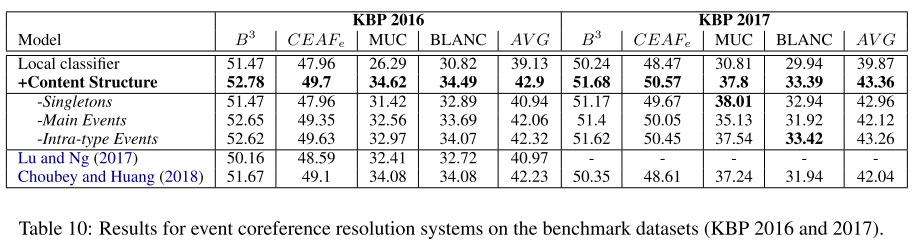
- 表10:事件链接实验结果。
8. 结论
本文构建了一个新闻话语类型语料库,并通过实验证明分析语句类型有助于事件链接等工作开展。
A Two-Step Approach for Implicit Event Argument Detection —— 论文阅读笔记
0. 摘要
本文主要关注隐式事件参与者检测任务,也就是跨句子的参与者检测,这涉及到大量候选参与者的选择问题。本文将问题分解为两个子问题,参与者头词检测和参与者头跨度检测,并分别进行处理。最终在 RAMS 数据集上取得了更好的效果。
1. 引言
大部分数据集是分析单句事件抽取的,如 ACE2005 和 RichERE。而文档级事件抽取就涉及到隐式事件参与者检测,如何确定大量候选参与者中谁是真正参与了事件。
本文将问题分解为两个子问题,事件参与者检测和事件跨度检测,并分别进行处理。这样能够显著减少候选参与者数量,降低时间复杂度。
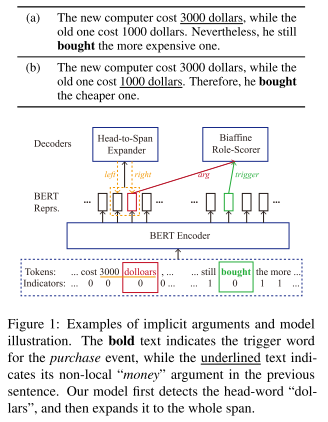
- 图1:隐式参与者样例和模型。不同上下文,选择不同的候选参与者作为事件参与者。
2. 模型
2.1 基于 BERT 的编码器
首先用基于 BERT 的编码器进行编码。输入包括一个谓词(或一个跨度)、触发的事件和多句上下文(本文采用的 RAMS 数据集,因此句子窗口大小为 5)。对每个词的标签设置为:触发词为 0,触发词句子的词为 1,其他句子的词为 0^1。
2.2 事件参与者检测模块
该模块对每个候选参与者词进行概率打分,判断是否为事件参与者(head word)。
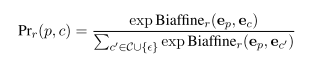
- 公式:事件参与者打分函数。采用了 BERT 模型。
2.3 事件跨度检测模块
该模块将事件参与者扩展到跨度。对每个事件参与者 h,生成一个左右跨度,并计算边界词作为跨度边界的概率得分。
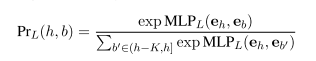
- 公式:事件跨度打分函数。采用了多层感知机。
3. 实验
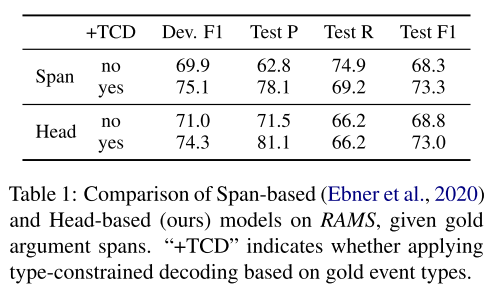
- 表1:基于跨度的和基于参与者的模型比较。本文的模型(Head)效果更好。
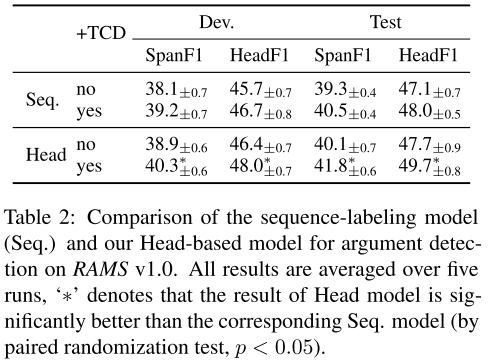
- 表2:序列标记模型和本文模型在 RAMS 上的比较。

- 表3:消融实验。
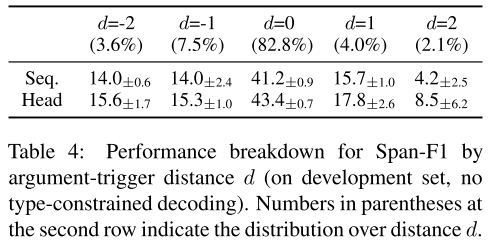
- 表4:触发词与参与者的距离之间性能分析。

- 表5:误差分析。
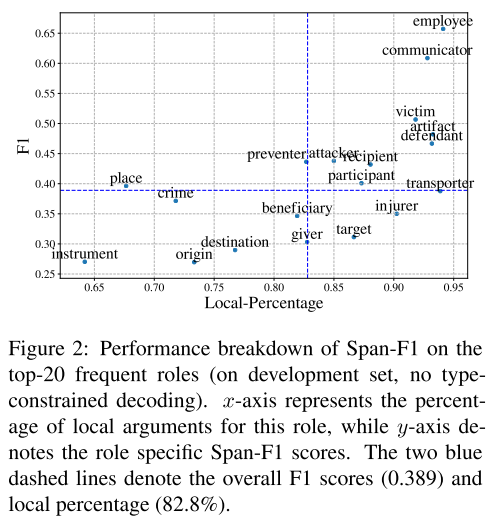
- 图2:常用角色性能分析。
4. 结论
本文提出的两步法模型,能够提高隐式事件参与者检测的效果。
Cross-media Structured Common Space for Multimedia Event Extraction —— 论文阅读笔记
0. 摘要
本文主要关注多模态事件抽取。提出了一个数据集,包含 245 篇多模态新闻报道。同时,提出了 WASE 框架,采取弱监督培训策略,实现不同模态间的对齐。与单模态文本事件抽取模型相比较,本文提出的模型能够取得更好的效果,体现了多模态的有效性。
1. 引言
传统事件抽取主要是单一模态,文本、图像、视频。而经过分析发现,很多事件的参与者仅仅出现在了图片中,而没有出现在文本中,因此采用单模态事件抽取会降低事件抽取的效果。本文构建了一个多模态事件抽取数据集,并构建了一个 WASE 框架,实现弱监督学习,对齐多模态信息,实现多模态事件抽取。

- 图1:多模态事件抽取样例。
2. 任务定义
事件抽取:

- 图:事件抽取。
参与者抽取:

- 图:参与者抽取。
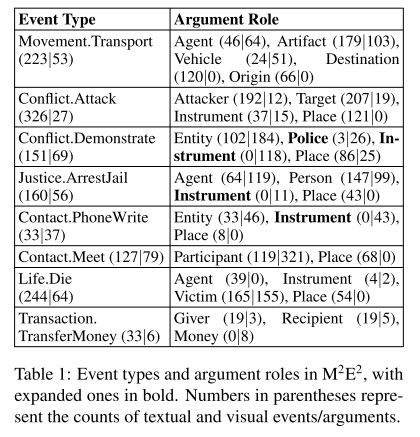
- 表1:M2E2 数据集。左侧是事件类型,右侧是参与者和角色信息。
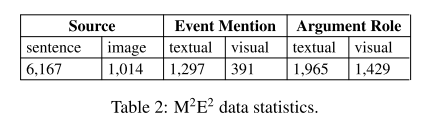
- 表2:M2E2 数据集统计信息。

- 图2:边界框。采用两种边界框,一种框选所有参与者,一种单独框选每个参与者。
3. 方法
3.1 方法概述

- 图3:方法框架。训练部分包括文本事件抽取、图片事件抽取和多模态信息对齐。测试阶段直接从多模态新闻中抽取事件。
3.2 文本事件抽取
单词嵌入选择 GloVe 嵌入,POS 嵌入,实体类型嵌入和位置嵌入的串联,之后将嵌入输入 BiLSTM 层进行表示学习,随后将向量输入 GCNs 层进行编码,最后获取每个实体的标记嵌入的平均值作为实体表示,将实体表示输入分类器,获取事件类型概率和事件参与者概率。
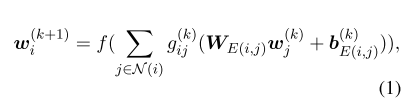
- 公式1:文本信息编码。
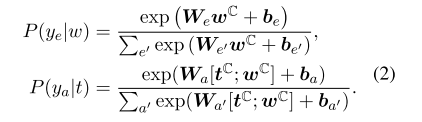
- 公式2:获取事件类型概率和事件参与者概率。
3.3 图像事件抽取
将图像转换为 AMR 图获取结构化表示,用情境图标记每个图像,其中中心节点为动词,其他节点包含参与者。利用 VGG-16 CNN 和多层感知机预测动词和名词,结合注意力机制,最后进行分类。
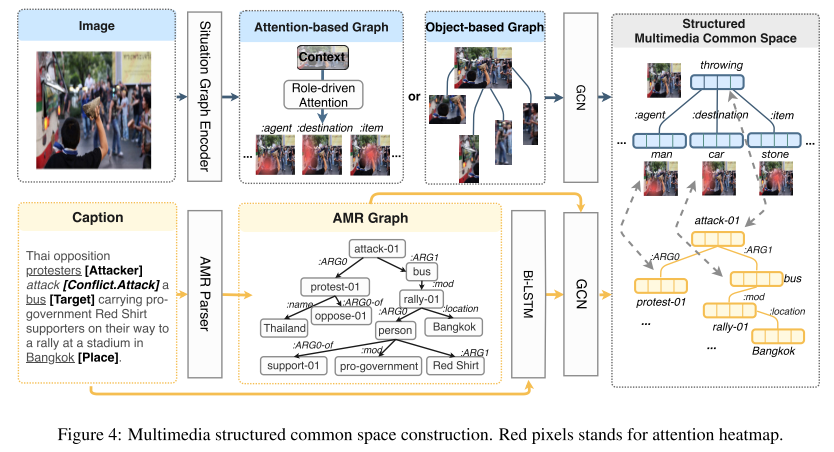
- 图4:多模态空间构建。
3.4 多模态联合培训
学习将每个图像的节点嵌入到对应标题节点附近(表示学习)。由于没有监督数据,因此采用弱监督学习,学习单词-图像、图像-单词的对齐。

- 公式:对齐参数。
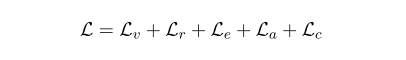
- 公式:损失函数。可以看到考虑的还是很多的。
3.5 多模态联合推理
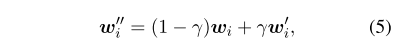
- 公式5:图像和文本信息的加权。
4. 实验
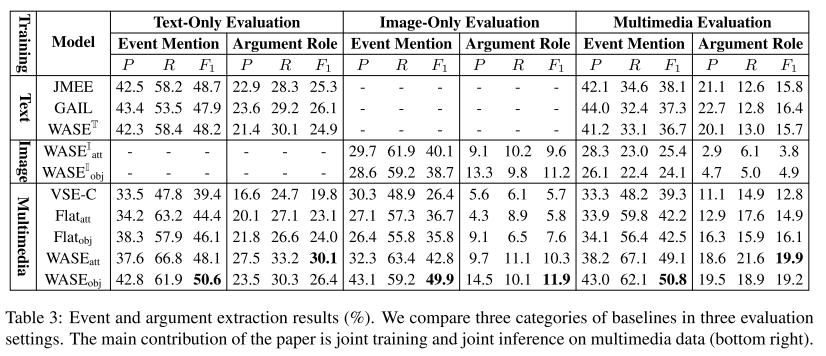
- 表3:事件和参数抽取结果。

- 表4:性能分析。

- 图5:图片有助于文本信息提取,文本信息有助于图片信息提取。

- 图6:多媒体嵌入评价。


- 图7, 8:错误分析。
5. 相关工作
本文开创了多模态事件抽取这一新领域。
6. 结论
本文开创了多模态事件抽取这一新领域。证明了多模态信息有助于事件抽取。
Comments | NOTHING