





近期一直在做实验室的项目,比较忙。最近总算是暂时告一段落了,于是决定把之前的笔记整理整理,发到博客上。
这篇文章是之前学习 PyTorch 记录的内容,主要来自于 Microsoft Learn 上面的 PyTorch 教程。
1. 什么是张量
张量是一种特殊的数据结构,和矩阵很相似。在 PyTorch 中用张量对模型的输入输出和模型参数进行编码。张量类似于 NumPy 的 ndarray,不同之处在于张量可以在 GPU 或其他硬件加速器上运行。
1.1 张量的初始化
张量初始化:
import torch
import numpy as np
# 第一种方法:数组转换
data = [[1, 2], [3, 4]]
data_tensor = torch.tensor(data)
# 第二种方法:从 NumPy 的 ndarray 得到
np_array = np.array(data)
np_array_tensor = torch.tensor(np_array)
# 第三种方法:从 tensor 转换
ones_tensor = torch.ones_like(data_tensor)
rand_tensor = torch.rand_like(data_tensor, dtype = torch.float)
# 第四种方法:从 shape 形状元组转换
shape = (2, 3, )
ones_tensor = torch.ones(shape)
rand_tensor = torch.rand(shape)
zeros_tensor = torch.zeros(shape)1.2 张量的属性
张量的属性:
# 形状:
tensor_shape = tensor.shape
# 数据类型:
tensor_dtype = tensor.dtype
# 设备:
tensor_device = tensor.device1.3 张量的运算
张量的运算:这里记录了 100 多种张量运算方法。张量初始化都是在 CPU 中,需要用 to 方法转移到 GPU 中。
# 转移 tensor
if torch.cuda.is_available():
tensor = tensor.to('cuda')基本运算:
tensor = tensor.ones(4, 4)
tensor_first_row = tensor[0]
tensor_first_column = tensor[:, 0]
tensor_last_column = tensor[..., -1]
# 第一列全部设为 0
tensor[:, 1] = 0
# 以指定维度连接张量
new_tensor = torch.cat([tensor, tensor, tensor], dim = 1)矩阵乘法:
# 第一种方法:@ 运算符
matmul1 = tensor @ tensor.T
# 第二种方法:torch.tensor.matmul 方法
matmul2 = tensor.matmul(tensor.T)
# 第三种方法:torch.matmaul 方法
matmul3 = torch.zeros(tensor)
torch.matmul(tensor, tensor.T, out = matmul3)元素乘法:
# 第一种方法:* 运算符
mul1 = tensor * tensor
# 第二种方法:tensor.torch.mul 运算符
mul2 = tensor.mul(tensor)
# 第三种方法:torch.mul 运算符
mul3 = torch.zeros(tensor)
torch.mul(tensor, tensor, out = mul3)求和和转换为 python 值:
agg = tensor.sum()
# 需要用 item 方法转换为 python 类型
agg_python_item = agg.item()
# agg_python_item 为 12.0. dtype 为 floatNumPy 和 Tensor 的桥接:改变一个将改变另一个
# tensor 到 numpy,直接用 tensor 的 numpy 方法就可以
numpy1 = tensor1.numpy()
# numpy 到 tensor,需要用到 torch 的 from_numpy 方法
tensor2 = torch.from_numpy(numpy2)2. 数据集和数据加载
PyTorch 提供了两个数据原语:torch.utils.data.DataLoader 和 torch.utils.data.Dataset,
2.1 加载数据集
加载数据集:
import torch
from torch.utils.data import Dataset
# 这里用到的是图像数据集,所以要导入 torchvision。文本数据集是 torchtext,语音数据集是 torchaudio
from torchvision import datasets
# ToTensor 将数据转换为 tensor 类型
from torchvision.transforms import ToTensor, Lambda
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root = "data".
train = True,
download = True,
transform = ToTensor()
)
test_data = datasets.FashionMNIST(
root = "data",
train = False,
download = True,
transform = ToTensor()
)迭代和可视化:
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
# 用 Matplotlib 绘图
figure = plt.figure(figsize = (8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
# 随机从数据集中采样,每次采样一个,然后将数据转换为 python 数
sample_idx = torch.randint(len(training_data), size = (1,)).item()
img, label = training_data[sample_idx]
# 在图像中加入该图
figure.add_subplot(rows, cols, i)
# 用 matplotlib.pyplot 设置每个子图绘制的要素
plt.title(labels_map[label])
plt.axis("off")
# 压缩并用灰度图
plt.imshow(img.squeeze(), cmap = "gray")
plt.show()2.2 自定义数据集
自定义数据集需要提供三个功能:__init__, __len__,__getitem__。
import os
import pandas as pd
import torchvision.io as tvio
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = tvio.read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
sample = {"image": image, "label": label}
return sample数据集样例:csv 文件需要是这样的。
tshirt1.jpg, 0
tshirt2.jpg, 0
......
ankleboot999.jpg, 92.3 数据迭代器
数据迭代器:DataLoader 是一个迭代器。训练模型时,希望用 batch 的形式传递样本,通过抽取数据减少拟合,同时通过 python multiprocessing 加快数据处理。DataLoader 可以简单的方式提供这些功能。
from torch.utils.data import DataLoader
# 构建数据迭代器
train_dataloader = DataLoader(training_data, batch_size = 64, shuffle = True)
test_dataloader = DataLoader(testing_data, batch_size = 64, shuffle = True)数据迭代:DataLoader 每次都会得到一批 train_features 和 train_labels。由于设置了 shuffle = True,遍历完所有批次后,数据会被打乱。
train_features, train_labels = next(iter(train_dataloader))
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap = "gray")
plt.show()
3. 数据集转换
数据集转换用于将提供的数据转换成容易训练的形式。
3.1 数据集转换
数据集转换:torchvision.transform 提供了一些类似的转换。以数据集 FashionMNIST 为例,提供的 features 为 PIL 图像,标签为整数。需要将标签转换为归一化张量,标签转换为独热编码张量。对此,可以使用 ToTensor 方法和 Lambda 函数实现。
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root = "data",
train = True,
download = True,
transform = ToTensor(),
target_transform = Lambda(lambda y: torch.zeros(10, dtype = torch.float).scatter_(0, torch.tensor(y), value = 1))
)4. 构建模型层
构建神经网络时,模型由 torch.nn 提供的模型层构成,同时模型应该以 toch.nn.Module 为参数。
4.1 构建神经网络模型
构建神经网络模型:通过子类化定义神经网络 nn.Module,在 __init__ 方法中
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
device = "cuda" if torch.cuda.is_available() else "cpu"
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits4.2 应用模型
应用模型:
# 将模型提交给设备
model = NeuralNetwork().to(device)
print(model)
# 生成特征
x = torch.rand(1, 28, 28, device = device)
# 得到结果
logits = model(x)
# 预测层采用 Softmax
predict = nn.Softmax(dim = 1)(logits)
# 获取预测结果
y = predict.argmax(1)
print(y)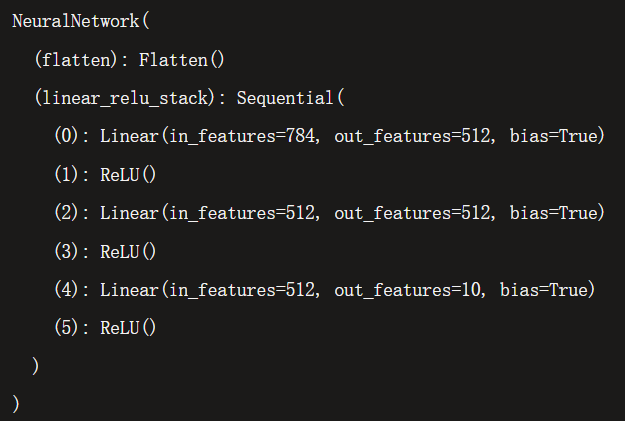
4.3 各层分析
各层分析:为了分析每一层的效果,构建如下实验。
# 构建 3 * 28 * 28 的图像特征(可以用 size 方法查看形状)
input_image = torch.rand(3, 28, 28)
# 展平层,将 3 * 28 * 28 转换为 3 * 784 的连续数组,保持批量维度不变,也就是 3 不变
flatten = nn.Flatten()
flat_image = flatten(input_image)
# 线性层,存储权重和偏置,对输入进行线性变换
layer1 = nn.Linear(in_features = 28 * 28, out_features = 20)
hidden1 = layer1(flat_image)
# 非线性激活,在模型的输入和输出之间构建复杂映射,在线性后引入非线性变换,帮助神经网络学习各种现象。
hidden1 = nn.ReLU()(hidden1)
# 顺序容器,构建一个快速网络
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3, 28, 28)
logits = seq_modules(input_image)
# Softmax 激活函数,将 logits 缩放到 [0, 1],代表模型对每个类别的预测密度。dim 指的是缩放的维度,比如 [2,3,4] 这样的张量,nn.Softmax(dim = 1),就是 3 对应的维度。
softmax = nn.Softmax(dim = 1)
predict = softmax(logits)
y = argmax(predict)
# 打印模型结构
print("Model structure: ", model, "\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")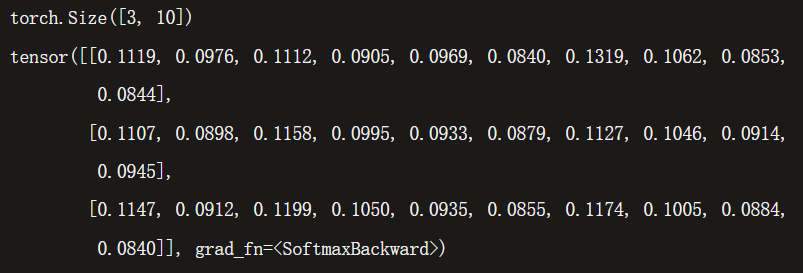
- 图:softmax 的结果
5. 自动微分
训练神经网络时,最常用的算法是反向传播。参数(模型权重)根据损失函数,根据给定参数的梯度进行调整。torch.autograd 是内置微分引擎,支持任何计算图的梯度自动计算。
5.1 自动微分计算
自动微分计算:PyTorch 提供方法自动前向计算函数和反向传播计算导数。grad_fn 属性存储了反向传播函数。
import torch
x = torch.ones(5)
y = torch.zeros(3)
w = torch.randn(5, 3, requires_grad = True)
b = torch.randn(3, requires_grad = True)
z = torch.matmul(x, w) + b
loss = torch.nn.functional.binary_cross_with_logits(z, y)
# z 和 loss 的反向传播函数存储在 z.grad_fn 和 loss.grad_fn 中。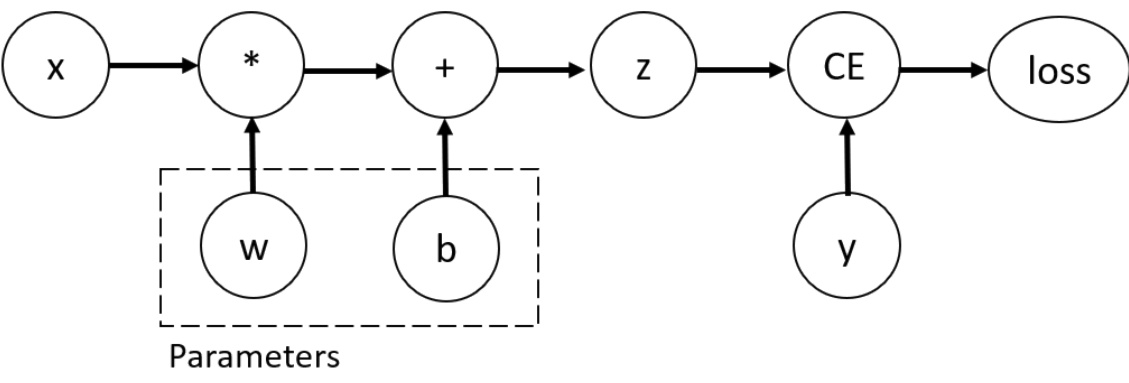
- 图:计算图。其中 w 和 b 是要优化的参数,因此设置了
requires_grad属性。可以在创建时设置requires_grad,也可以随后使用x.requires_grad(True)进行设置。
计算梯度:为了优化神经网络中参数的权重,需要计算损失函数关于参数的导数。为了计算导数,要调用 loss.backward() 方法,然后从 w.grad 和 b.grad 中获取导数。backward 方法一次只能调用一次。
loss.backward()
print(w.grad)
print(b.grad)禁用梯度:如果模型完成了训练,只需要预测,可以设置 torch.no_grad() 包裹代码块实现单纯预测。另一种方法是用 detach() 方法。
z = torch.matmul(x, w) + b
# 第一种方法:torch.no_grad() 包裹
with torch.no_grad():
z = torch.matmul(x, w) + b
# 第二种方法:detach() 方法
z_detach = z.detach()6. 优化模型参数
有了模型和数据,就可以通过优化数据来训练、验证和测试模型了。训练模型在每次迭代(epoch)中对模型进行预测,计算其中误差(loss),然后反向传播计算导数,并优化梯度下降的参数。
之前的代码:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()6.1 设置超参数
设置超参数:超参数是可调节的参数,用于控制模型优化过程。设置如下超参数:迭代数据集的次数(epoch num),模型在每个 epoch 中看到的数据样本数量(batch size),每个批次 batch 和迭代 epoch 中更新模型的程度(learning rate)。较小的学习率会导致学习过慢,较大的会让学习过程中出现不可预测行为。
learning_rate = 1e-3
batch_size = 64
epoch = 56.2 设置优化循环
设置优化循环:设置完超参数就可以进行优化循环来训练和优化模型。优化循环的每一轮是一个 epoch,每个 epoch 包括两步:训练循环和验证测试循环。
添加损失函数:损失函数衡量模型得到的结果和目标值的不相似程度。常见的损失函数包括回归任务的 nn.MSELoss(均方误差),分类任务的 nn.NLLLoss(负对数似然)和 nn.CrossEntropyLoss(交叉熵损失)(交叉熵损失 nn. CrossEntropyLoss 融合了 nn.LogSoftmax 和 nn.NLLLoss)。将模型的输出传递给损失函数,从而标准化并预测误差。
loss_fn = nn.CrossEntropyLoss()添加优化器:优化是在每个训练步骤中调整模型参数,从而降低模型损失的过程。优化算法定义了这一步是如何进行的。所有优化都在 optimizer 对象中。训练过程中,优化包括三步:
- 调用
optimizer.zero_grad()重置模型参数的梯度,默认情况下渐变相加,为了避免重复计算,每次迭代 epoch 时明确归零。 - 调用反向传播预测损失
loss.backwards(),获取并存储梯度。 - 获取梯度后,调用
optimizer.step()通过梯度进行参数调整。
optimizer = torch.optim.SGD(model.parameters, lr = learning_rate)优化循环:
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (x, y) in enumerate(dataloader):
predict = model(x)
# 计算损失
loss = loss_fn(predict, y)
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(x)
print(f"loss: {loss:>7f} [{current:>5d}]/{size:>5d}")测试循环:
def test_loop(dataloader, model, loss_fn):
# 计算 batch_size
size = len(dataloader.dataset)
test_loss, correct = 0, 0
with torch.no_grad():
for x, y in dataloader:
predict = model(x)
# 因为要算数了,所以后面跟个 item()
test_loss += loss_fn(predict, y).item()
# 计算正确预测个数
correct += (predict.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")6.3 开始学习
开始学习:完成模型定义、超参数设置、优化循环设置后,就可以开始学习了。
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), ln = learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t + 1}")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(test_dataloader, model, loss_fn)
print("Done.")7. 保存和加载模型
保存和加载模型。
import torch
import torch.onnx as onnx
import torchvision.models as models7.1 保存和加载模型权重
保存和加载模型权重:可以用 torch.save(model.state_dict(), path) 存储模型权重。model.state_dict() 保存了权重。可以用 torch.load_state_dict(torch.load(path)) 导入模型权重。PyTorch 的模型将学习到的参数存储到了内部字典 state_dict 中,可以通过 model.state_dict() 获取。
# 获取模型
model = models.vgg16(pretrained = True)
# 保存模型权重
torch.save(model.state_dict(), 'data/model_weights.pth')
# 获取没有权重的模型
model = models.vgg16()
# 导入模型权重
model.load_state_dict(torch.load('data/model_weights.pth'))7.2 保存和加载带有形状的模型
保存和加载带有形状的模型:保存模型和读取模型就更简单了。直接 torch.save(model, path) 和 torch.load(path) 就行了。
torch.save(model, 'data/model_weights.pth')
model = torch.load('data/model_weights.pth')8. 完整模型构建
8.1 数据处理
数据处理:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplolt as plt
training_data = datasets.FashionMNIST(
root = 'data',
train = True,
download = True,
transform = ToTensor(),
)
test_data = datasets.FashionMNIST(
root = 'data',
train = False,
download = True,
transform = ToTensor(),
)
batch_size = 64
train_dataloader = DataLoader(training_data, batch_size = batch_size)
test_dataloader = DataLoader(test_data, batch_size = batch_size)8.2 创建模型
创建模型:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU(),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits8.3 优化模型参数
优化模型参数:
loss_fn = nn.CrossEntropyLoss()
learning_rate = 1e-3
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (x, y) in enumerate(dataloader):
x, y = x.to(device), y.to(device)
predict = model(x)
loss = loss_fn(predict, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(x)
print(f'loss: {loss:>7f} [{current:>5d}/{size:>5d}]')
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
model.eval()
test_loss, corrent = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
predict = model(x)
test_loss += loss_fn(predict, y).item()
correct += (predict.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
print(f'Test Error: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n')8.4 训练和测试模型
训练和测试模型:
epochs = 15
for t in range(epochs):
print(f'Epoch {t + 1}\n')
train(training_data, model, loss_fn, optimizer)
test(test_data, model, loss_fn)
print('Done!')8.5 保存和加载模型
保存和加载模型:
torch.save(model.state_dict(), 'data/model.pth')
print('Saved.')
model = NeuralNetwork()
model.load_state_dict(torch.load('data/model.pth'))
torch.save('data/model.pth')
model = torch.load('data/model.pth')
Comments | NOTHING