





Jure 实验室最新的一篇论文,应用了他们实验室的最新技术。
代码:SMORE
0. 摘要
本文提出了 SMORE 框架(Scalable Multi-hOp REasoning),通过它可以在 Freebase 这样的超大型知识图谱上进行多跳推理。
SMORE 框架的核心是双向拒绝抽样,能够实现在线训练数据生成时的复杂性平方根降低(achieves a square root reduction of the complexity of online training data generation)。
此外,SMORE 框架还采用了基于 CPU 的重叠数据采样,基于 GPU 的嵌入计算和内存显存输入输出方法。
SMORE 框架可以通过很少的 GPU 内存需要(2GB 训练 400 维的有 86M 节点数据的 Freebase),速度达到 SOTA 框架的 2.2 倍,同时速度随着 GPU 数量增加线性增长。
同时,SMORE 在常用知识图谱上可以在单 GPU 和多 GPU 上都能取得比较好甚至更好的效果。
1. 方法
1.1 方法概述
文章采用对比学习的方法,训练查询嵌入方法的模型,进行多跳知识推理。
基于嵌入的推理方法:训练一系列神经逻辑运算符(例如否定运算符),然后对输入实体进行计算,获得输出实体,通过这样的过程进行查询。对比学习用于知识推理:构建 (q, A, N) 三元组,包含查询,答案实体和负例实体。优化目标是最小化查询嵌入和答案实体嵌入距离,最大化查询嵌入和负例实体距离。其中,由于大规模知识图谱上的多跳知识推理涉及到大量实体,因此如何构建三元组就是难题。
因此,本文认为对比学习用于知识推理最重要的是如何快速生成大量对比学习样例。
对此,本文提出的方法是双向拒绝抽样。为什么叫这个名字呢?可以看它的方法。
-
A. 查询结构选择:首先选择查询结构模板中的结构。
-
B. 生成查询:随后选择一个实体作为答案实体(根节点),开始根据查询结构生成树状结构。关系(树的边)也是随机选择的,最后到达锚实体(叶子结点)。通过这样的方式,反向构建查询。
-
C. 前向缓存:从锚实体出发,朝着
node cut的位置查找,并缓存查找过程中路过的实体。这里的node cut意思就是能够截取所有锚实体(叶子节点)到答案实体(根节点)的节点组合。如果定义node cut是最小的,也就定义了node cut的最小的节点组合,任何更小的节点组合都不再是node cut,不能拦截所有锚实体和答案实体之间的路径了。也就是说,node cut是从锚实体出发找到答案实体的路径的一环,不能避开。同时,由于查询结构是固定的,对应的node cut的位置也是固定的,所以查询时知道什么时候到达了node cut应该所在的位置。 -
D. 反向验证和拒绝抽样:从答案实体出发,朝着
node cut的位置查找,并缓存查找过程中路过的实体。其中与前向缓存的实体重叠的实体,对应的答案实体就是正例,反之则是负例。 -
E. 基于遍历的抽样:此前的方法,时间复杂度可以看出来是节点出度的平方。相比之下,本文的方法是节点出度的线性。
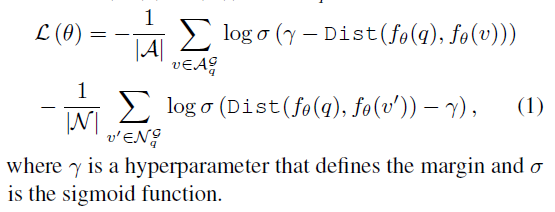
- 图:对比学习损失。
- 图:
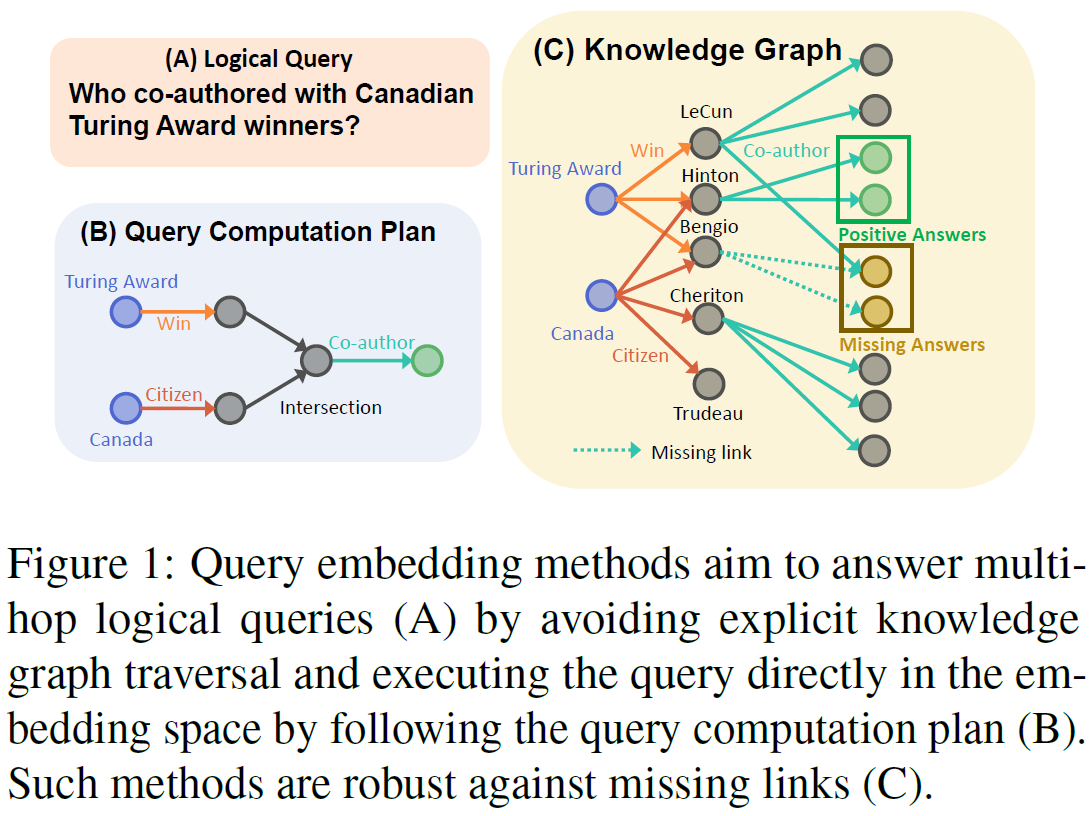
查询嵌入方法的目标是,对于多跳查询问题(子图 A),通过执行嵌入空间的查询计算方案避免盲目的多跳推理移动(子图 B),同时查询嵌入方法还能够比较好地应对知识图谱中的缺失路径问题(子图 C)。
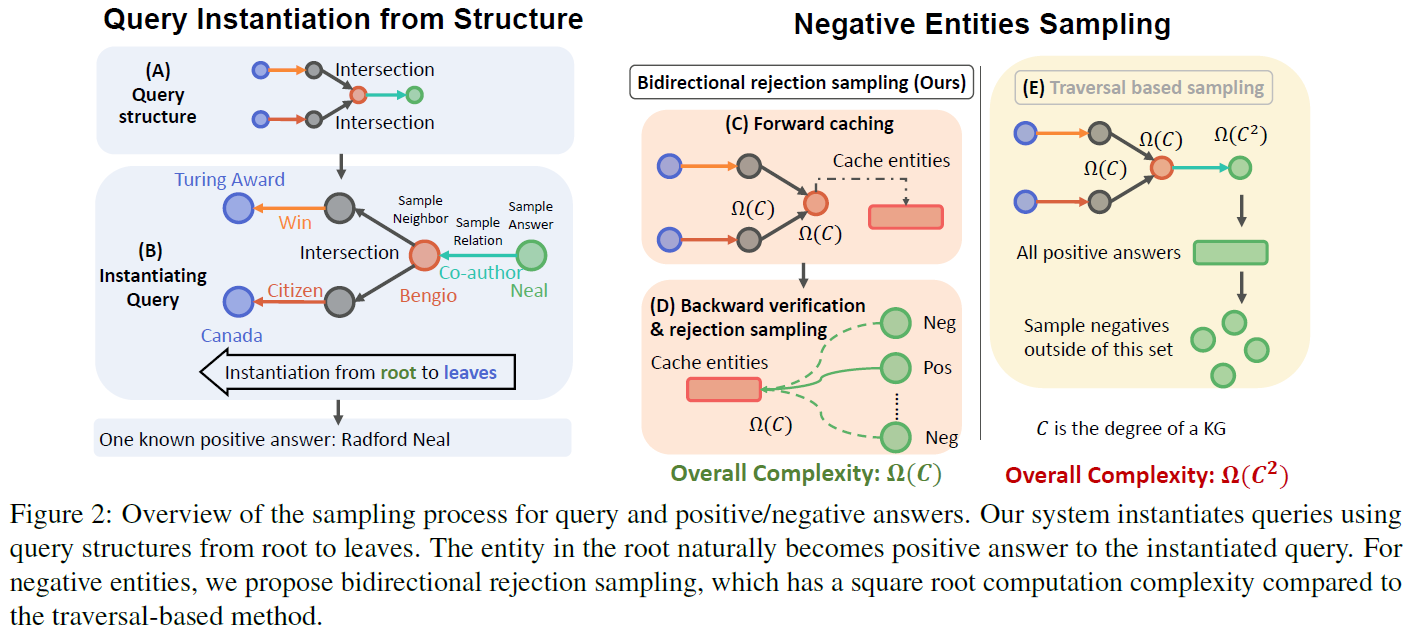
- 图:查询嵌入方法,首先选择查询结构(子图 A),随后根据答案实体,反向生成查询(子图 B)。随后从锚实体出发,朝着
node cut方向查找,将所有到达node cut应该在的位置的实体进行求并集,得到候选实体集合(子图 C)。同时,从答案实体出发,朝着node cut方向查找,如果到达node cut位置的实体也在候选实体集合中,就说明该答案实体是正例,反之则是负例(子图 D)。与 SMORE 框架的线性时间复杂度相比,常规的基于遍历的样例抽取方法的时间复杂度要高得多,达到了平方级,不适合大规模知识图谱(子图 E)。

- 图:不同的查询结构。其中带阴影的是
node cut,用于双向拒绝采样。
1.2 高效数据集构建
查找 node cut 的过程是比较复杂的,本文决定采用动态规划的方法,实现前向查询和反向验证查找 node cut 的过程。
定义了三种函数 u(v), s(v) 和 o(v),分别表示实体 v 到答案实体的路径长度,v 到任何锚实体的最大路径长度,和含有实体 v 的推理路径中的最短路径。可以递归导出三个函数的依赖关系,并在线性时间求解动态规划问题,最后通过 o(v) 获取 node cut。
通过上述计算方法,极大地降低了时间复杂度,使得模型能够在超大型知识图谱(Freebase,规模大概是普通知识图谱的 1500 倍)上获取 node cut,从而快速构建对比学习数据集。

- 图:优化方程,目标是找到让
node cut节点与前向缓存与反向验证的路径总长度的最大值最小。也就是说,node cut节点与路径节点离得越近越好。这里的 cost 就是路径长度。

- 图:三个函数的定义式。

- 图:基于上面的三个函数,通过动态规划,求解 o(v) ,就可以得到
node cut。这个计算过程是线性时间复杂度的。
1.3 高效训练系统
本文采用 GPU 进行矩阵运算,同时 CPU 进行抽样操作,从而提高效率。
大规模知识图谱通常有 512 维以上的百万量级的实体,无法存储在 GPU 中。因此本文设计了一种方法,将实体数据保存在内存,然后将需要导入的数据导入到显存中。
SMORE 采用的异步机制包括:
- 多线程采样器(快速获取训练数据集)。
- 稀疏嵌入读写(从内存读取实体到显存)。
- 密集计算(计算梯度)。
- 异步读写的稀疏优化器(异步读写数据)。
SMORE 的其他优化内容:
- 共享负样本:为了尽量减少内存和显存的数据交换,让每个进入显存的查询集合共享同一批负样本。
- 定制 CUDA 距离计算核:对 CUDA 核进行定制,使得其更适合多跳推理任务的相似度距离计算。
- 计划结构采样:由于不同结构的查询计算难度是不同的,通过随机种子,使得每个采样器都对每个批次的。

- 图:数据传递。
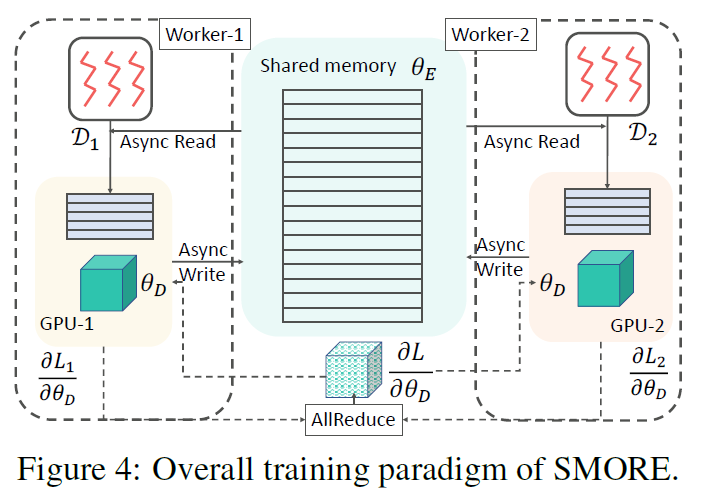
- 图:训练机制。
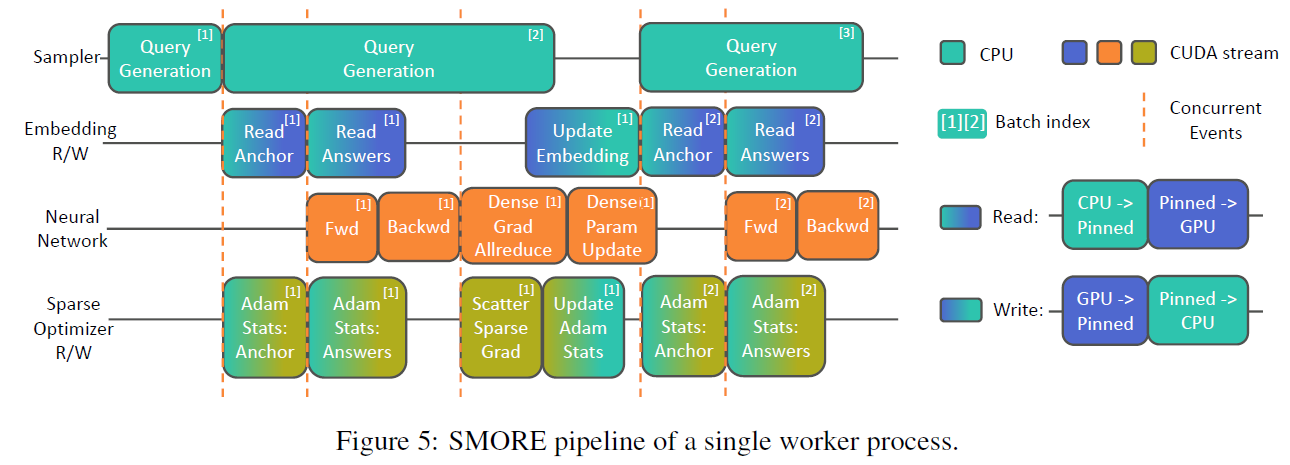
- SMORE 流水线机制。
2. 实验
实验主要包括:
- 不同知识图谱的模型效果对比。
- 常规知识图谱推理效果分析。
- 大规模知识图谱推理效果分析。
- 不同数据集构建方法时间效率和精确度分析。
- 训练方法 GPU 加速度和利用率分析。


- 表:三个采用 SMORE 框架的多跳推理模型和六个单跳推理模型。
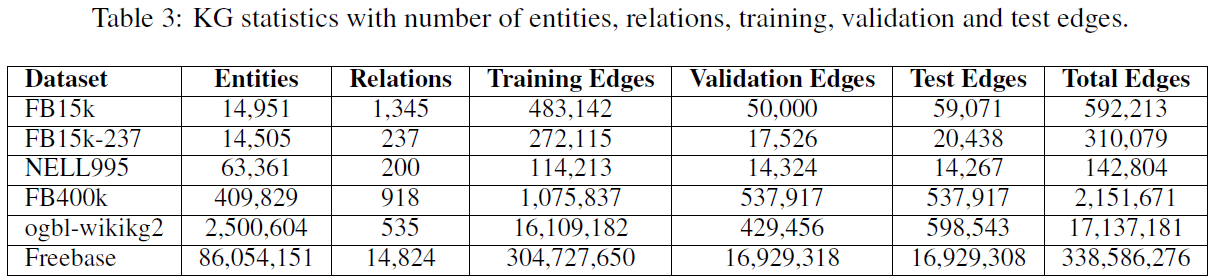
- 表:知识图谱对比。
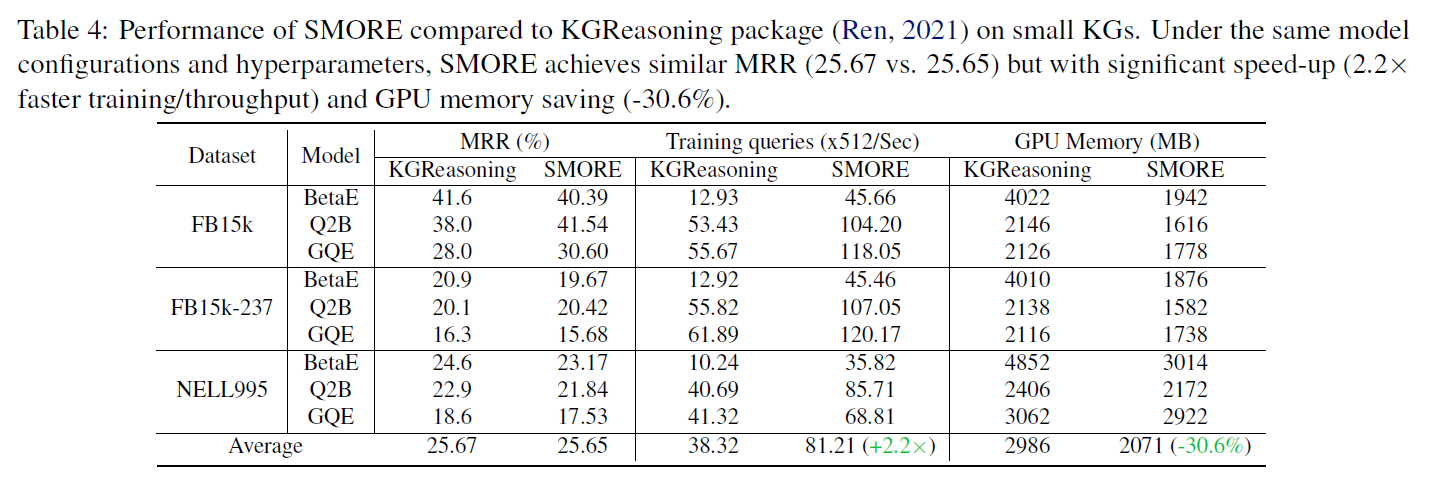
- 表:小知识图谱的表现效果。
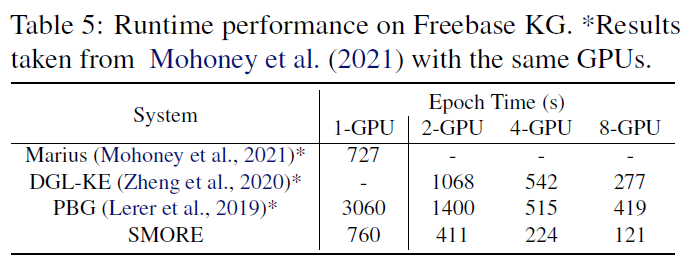
- 表:Freebase 上的推理耗时比较。
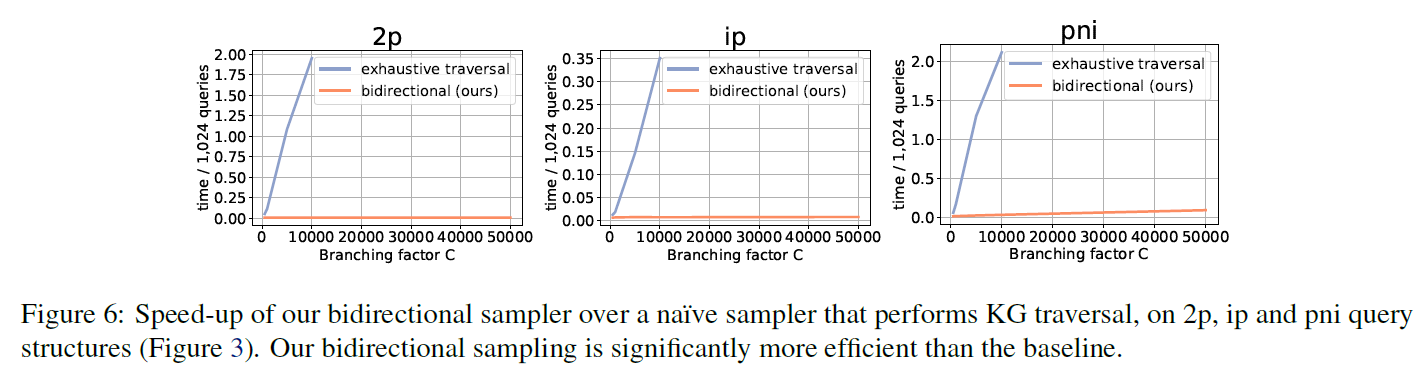
- 图:双向抽样方法和普通抽样方法的加速度比较。不会随着分枝数增加显著提高负样本构建的时间复杂度。
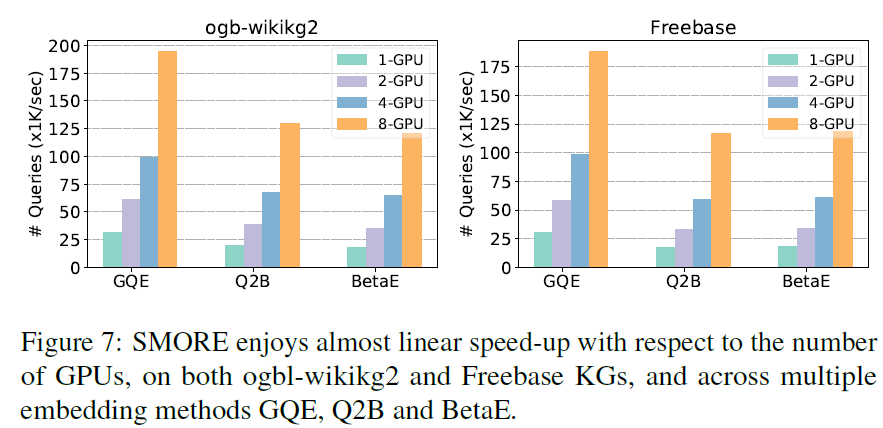
- 图:SMORE 框架的 GPU 加速效果,基本是线性的。
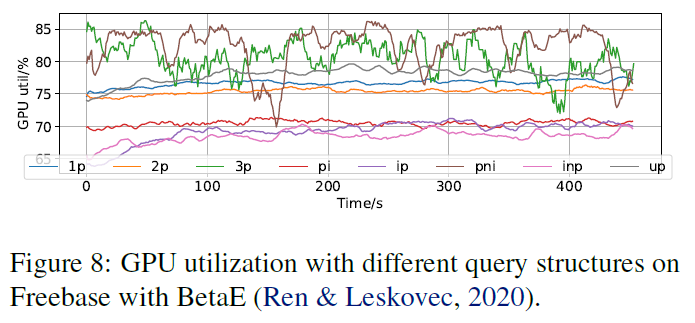
- 图:不同查询结构的 GPU 利用率。
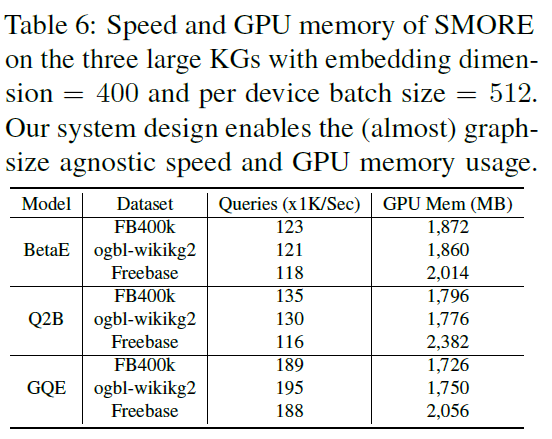
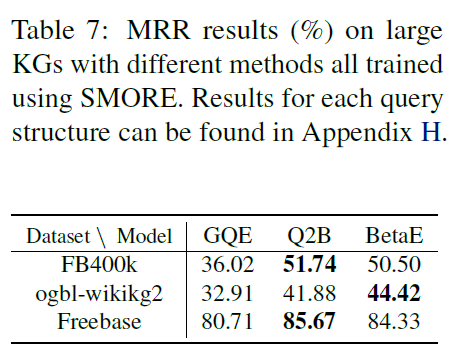
- 表:不同数据集在大规模知识图谱上的效果。
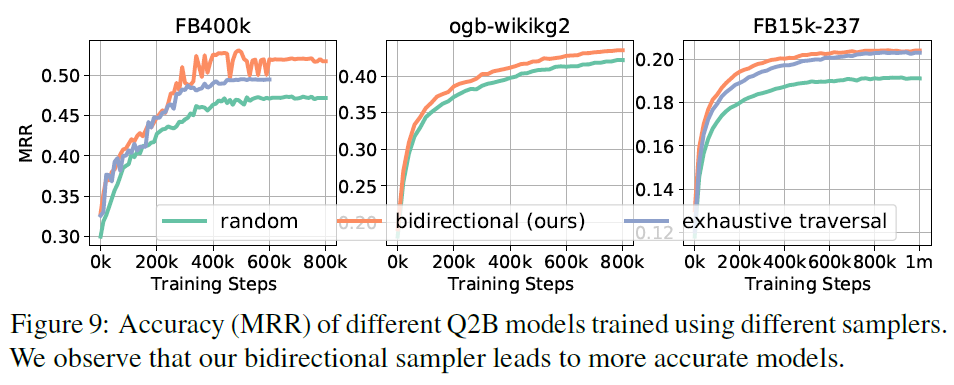
- 图:不同抽样方法的模型精度。可以看到本文的模型精度是最高的。
Comments | NOTHING