





论文地址:RikiNet: Reading Wikipedia Pages for Natural Question Answering
FullWiki 问答一直是开放领域问答的难点。像我们前面介绍的,如何在 5M 的文档中找到答案,文档检索器十分关键。当然,对于本文的 NQ 数据集,由 Google 搜索引擎自动帮我们约束了答案文档范围,仅仅需要在5个文档中找到答案。这篇文章采用了拆分段落的方式,将文本拆成固定大小,并通过滑动窗口的方式获取新段落。通过预训练模型和双向注意力机制,最终实现相关段落的获取。这个方法可以进一步探索。
0. Abstract
本文提出的 RikiNet 模型,包含一个动态段落双向注意力阅读器和一个多级级联答案预测器,获取短答案跨度、长答案段落和答案类型。
1. Introduction
本文的数据集是 Natural Question, NQ。这个数据集是 FullWiki 类型的数据集,也就是不提供相关段落而需要去 Wikipedia 中自己找(其实是 Google 搜索引擎给出的前5个文档,因此其实答案范围比自己检索 5M 的文档小了很多)。NQ 要求的答案包括短答案跨度 SA 和长答案段落 LA。
2. Preliminaries
NQ 数据集的要求:给定问题和相关维基百科页面(Google 搜索前5的文档),返回一个包含答案的段落作为长答案 LA,同时返回答案跨度作为短答案 SA。数据集里面有 1% 的答案是是否类型,因此 LA 和 SA 都应该是 NULL,也就是无法获取相关段落和跨度。
本文采用滑动窗口方法,将原数据集 (q, p),分别代表问题和段落集合,改成了包含6个内容的向量:(q, d, c, s, e, t),分别代表长度为 n 的问题单词切片、长度为 m 的段落跨度、滑动窗口段落序号、短答案跨度的开始和结束索引、五种答案类型(包含 NULL 没有答案、SHORT 短答案、Long 长答案、Yes 肯定答案、No 否定答案)。
RikiNet 将 (q, p) 转换为 (q, d),预测 (c, s, e, t),最后将答案进行合并,得到最后的 LA 和 SA 以及置信度得分。
3. Methodology
RikiNet 由两部分组成:动态段落双向注意力阅读器和多级级联答案预测器。
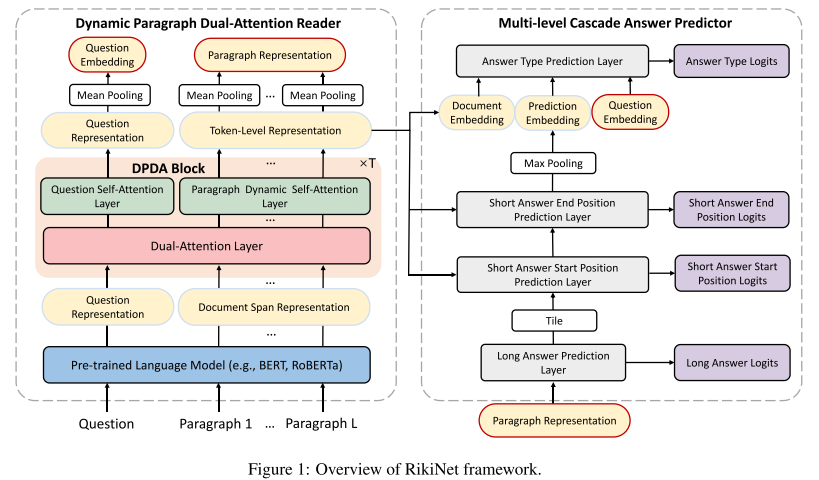
- 图1:模型结构。左侧动态段落双向注意力模块首先将问题和段落集合作为输入,调整为长度为 n 的问题单词切片和长度为 m 的段落跨度后,输入预训练模型,获取问题表示和文档跨度表示,随后将表示向量输入由双向注意力层和问题自注意力层和段落动态自注意力层构成的多个动态段落双向注意力块 DPDA,将生成的表示向量进行平均池化处理,最后作为问题嵌入向量和段落表示向量。右侧多级级联答案预测器模块将段落表示向量作为输入,首先进行 LA 预测,随后将长答案预测表示 HL 和动态段落双向注意力模块生成的令牌级表示作为输入来预测 SA 跨度。最后,将文档嵌入、SA 预测嵌入和问题嵌入作为输入,预测最终的答案类型。
3.1 动态段落双向注意力阅读器
输入为 [CLS] 长度为 n 的问题单词切片 [SEP] 长度为 m 的段落跨度 [SEP]。
动态段落双向注意力块 DPDA Block 包含三种结构。双向注意力层、问题自注意力层和段落动态自注意力层。
双向注意力层:
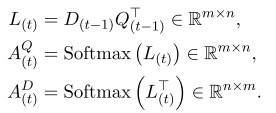
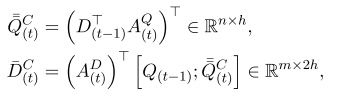
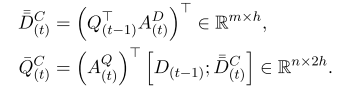
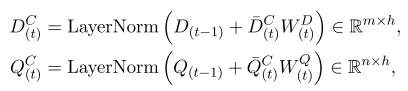
问题自注意力层:
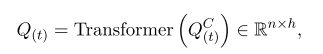
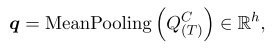
段落动态自注意力层:
-


-
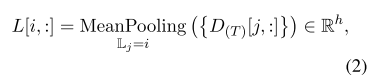
-
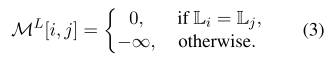
-
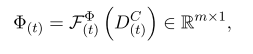
-
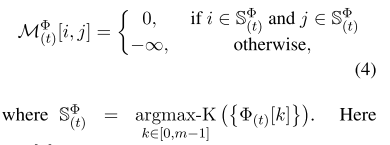
-
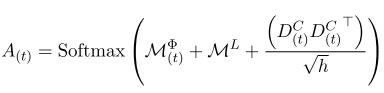
-
公式1:段落标记表示初始化。
-
公式2:段落表示。
-
公式3:段落注意力掩模,用于确定相关段落的训练。
-
公式4:段落动态注意力掩模。上面的公式为重要性评分函数。
-
最下方公式:注意力权重。
3.2 多级级联答案预测器
由于长答案总是包含短答案,因此设计级联答案预测器,先预测 LA,再预测 SA,最后预测 答案类型 AT。
-
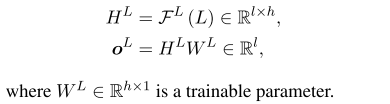
-
公式:长答案预测。
-

-
公式:短答案预测。
-

-
公式:答案类型预测。
-
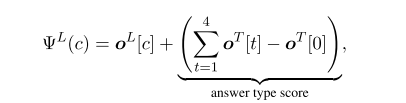
-
公式:长答案置信度得分。
-

-
公式:短答案置信度得分。
4. Experiments
数据集:
-
数据集采用 Google 提供的 Natural Question, NQ 数据集。
-

实施详情:
- 滑动窗口尺寸 512, 步幅 192,从而每个维基百科页面平均能划分出 22 个段落。
- 由于大部分跨度不包含答案,导致正例和负例比例失衡,所以采用了一个方法:sub-sample negative instances。这个方法也是另一篇 ACL 2019 的论文 提出的方法。下次将会分享这篇文章。
实验结果:
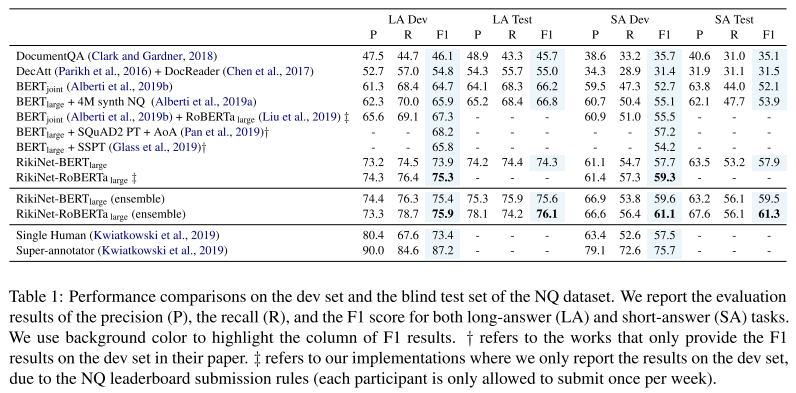
- 表1:实验结果。提升很大。
- 表2:DPDA 消融实验。动态段落双向注意力块最重要。
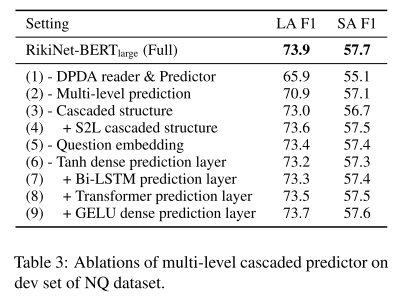
- 表3:多级级联答案预测消融实验。

5. Related Works
FullWiki 数据集比较好的模型:
- DrQA
- DocReader
- BERTjoint
6. Conclusion
可以看到,NQ 数据集是 Google 提供的,相关文章和实验也很多,因此后面可以持续关注这个数据集。
Comments | NOTHING