





今天分享的内容,严格来说并不属于论文,而应该是一个教程。文章是 ACL 2020 的论文,但仅仅属于一个引文,主要的内容在文章中给出了 GitHub 链接。教程的内容非常详细,包含了 ODQA 的历史、数据集、常用模型分类以及 KBQA 相关的内容,非常值得阅读。
0. Open-Domain Question Answering
开放领域问答是 NLP, IR 长期研究的问题。传统 QA 系统一般被构建为流水线系统 Pipeline,由不同组件组成,如问题处理、文档/段落检索和答案处理。随着神经阅读理解的发展,研究者结合传统信息抽取技术和神经阅读理解模型,甚至直接采用端到端训练的方式,实现了新的 ODQA 系统。
整个教程首先简要介绍了 ODQA 的背景,讨论基本内容和核心技术挑战。
随后讨论 ODQA 现代数据集,以及常见评价指标和基准。
随后研究前沿模型,包括三种类型:
- 两阶段检索器-读取器模型:检索器组件通常是传统稀疏向量空间方法实现,如 TF-IDF, BM25,阅读器是神经阅读理解模型。该领域新进展包括:多段落训练,段落排序和远程监督数据去噪。
- 密集检索器-端到端训练模型:包含两类,第一类采用非机器学习模型进行检索,第二类采用密集表示替代传统信息抽取方法,并对两个组件进行联合训练。实现方法包括:新型预训练方法、精心设计的学习算法和密集和稀疏表示的混合方法。
- 无检索器模型:一种新趋势,仅依赖大规模预训练模型作为隐式数据库,不依赖其他数据。预训练模型直接用于零激发方式回答问题,或利用问答对进行微调。
随后,讨论 KBQA 相关方法。研究包括:如何利用结构化数据知道现有检索器或阅读器,以及如何融合知识信息和文本信息异构来源的信息。
最后,讨论研究进展以及当前主要挑战和局限。
1. Introduction
1.1 教授信息

- 作者:Danqi And Scott。
1.2 什么是 ODQA,以及趋势
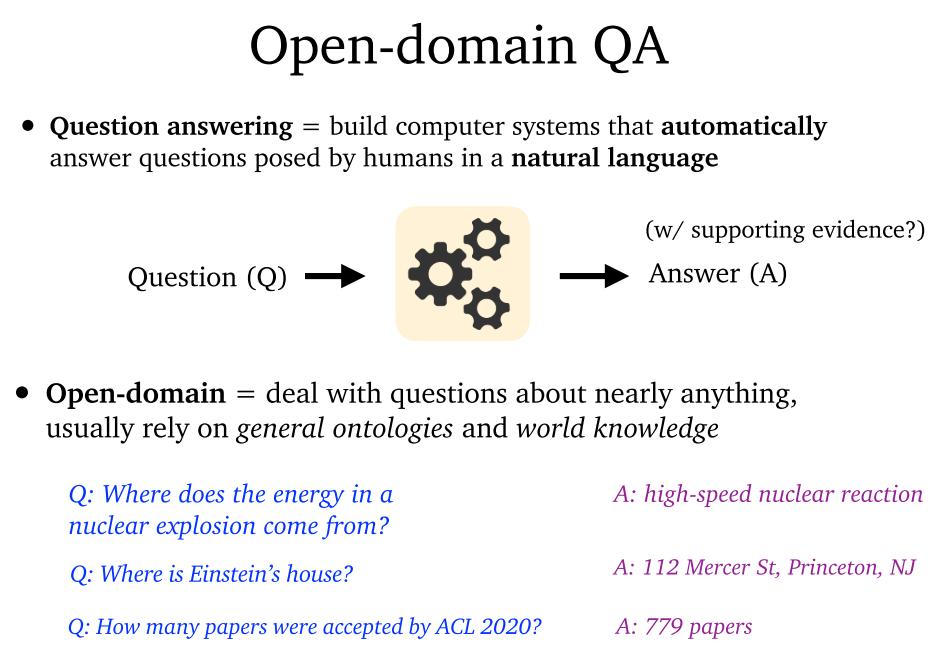
- 问答系统:构建自动回答人类自然语言问题的计算机系统。
- 开放领域:处理包括各种普遍本体和世界知识在内的任何问题。
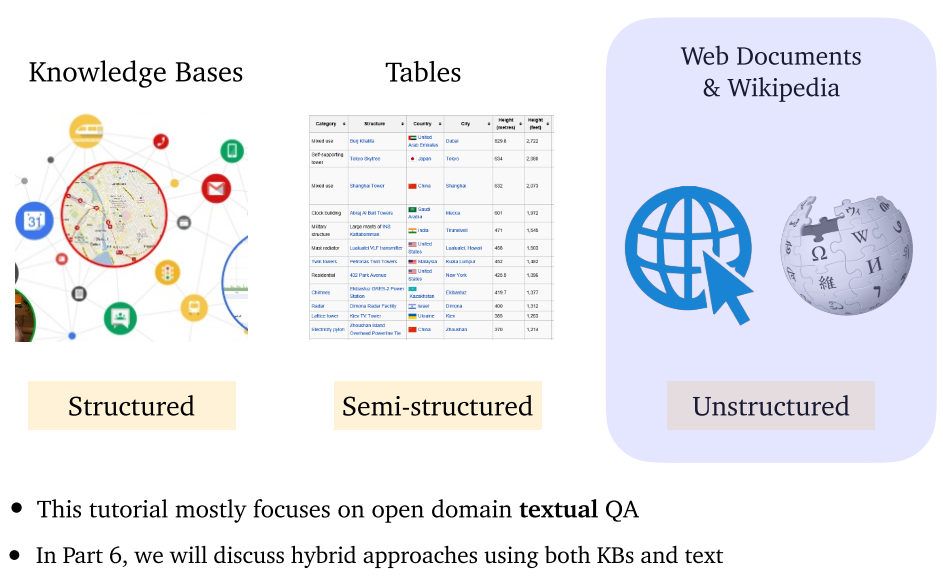
- 内容包括:结构知识(KB,知识库),半结构知识(表),非结构知识(网络文档、维基百科)。本教程主要为
文本 QA,第六章讨论 KBQA。
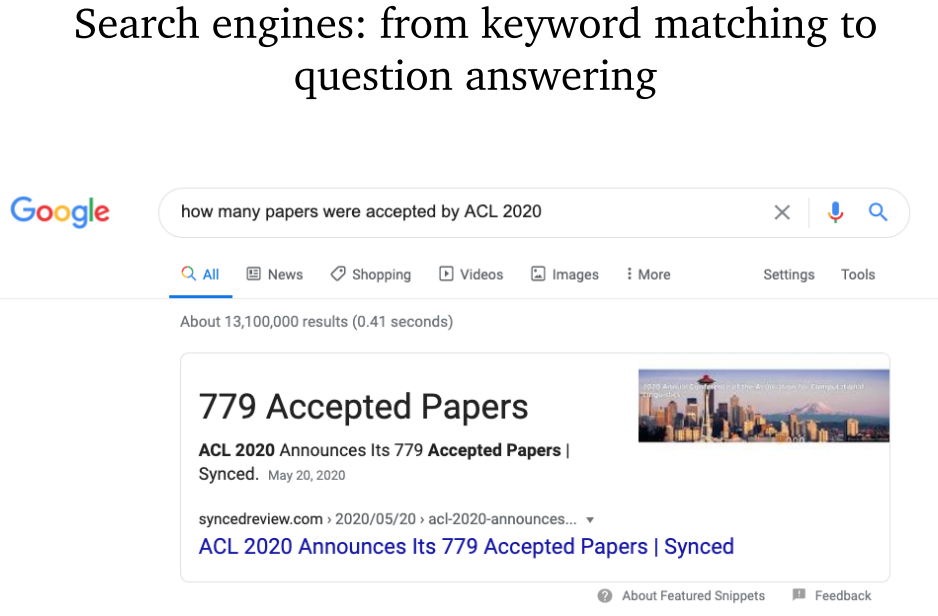
- 搜索引擎:由关键字匹配到问答系统。
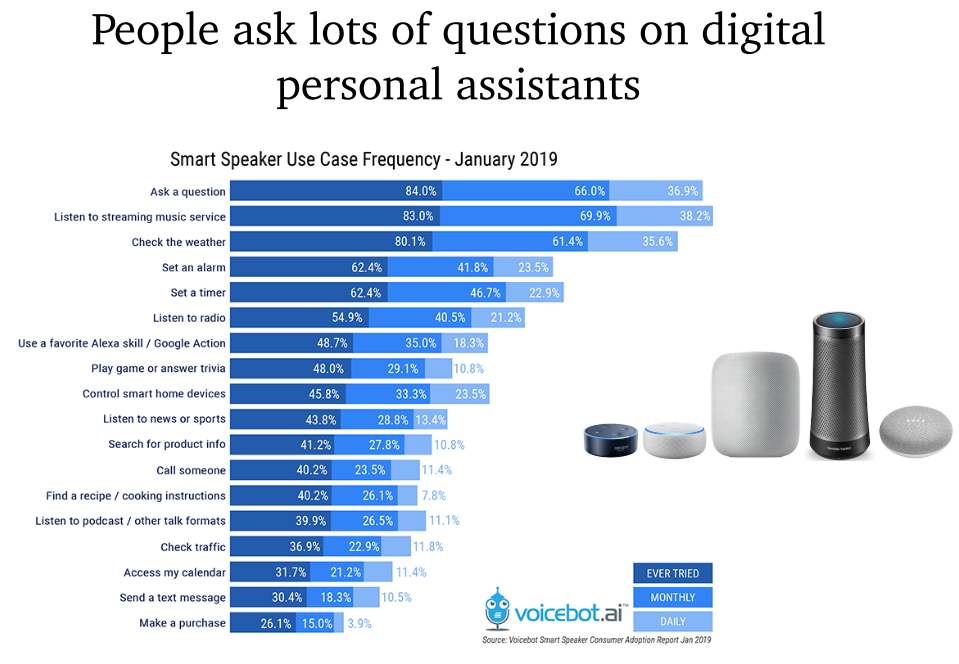


- 本教程主要介绍 2017-2020 的 ODQA 进展。
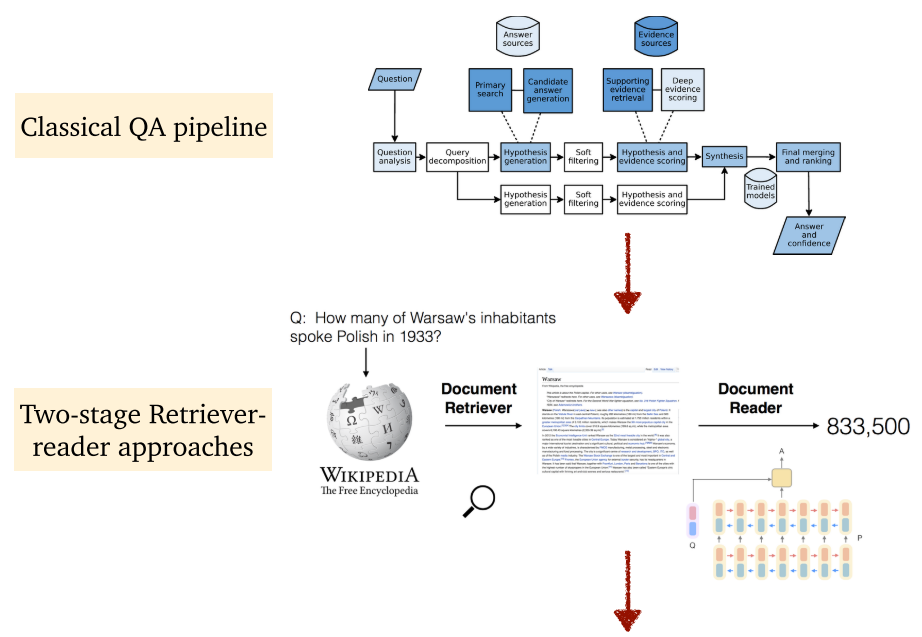
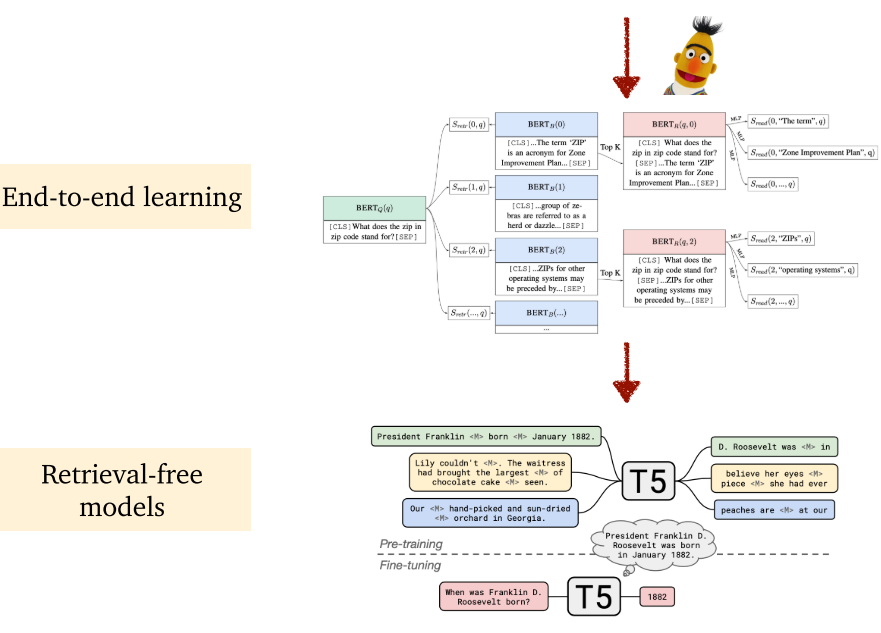
1.3 内容大纲
- 两位老师的分工,教程做的还是很可爱的。
2. History
2.1 早期 QA 系统


- 早期的问答系统研究:1965 年。




早期 QA 系统局限性:
- 问答领域范围比较小。基本都是特定的、英语的、容易把控的领域。
- 非数据驱动。基本都是规则型,同时也缺少严格的评价指标。
2.2 管道问答系统

- TREC:由信息抽取社区开始研究新的问答系统,目标是从相关文档获取带有支持的答案。
- 同时提供了 newswire 语料库和测试集,由人工进行评判正误。
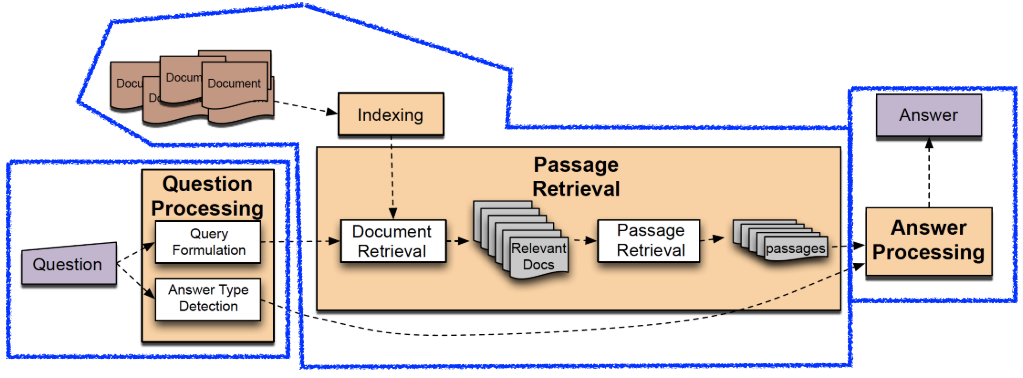
- 管道问答系统:从 TREC 开始流行。
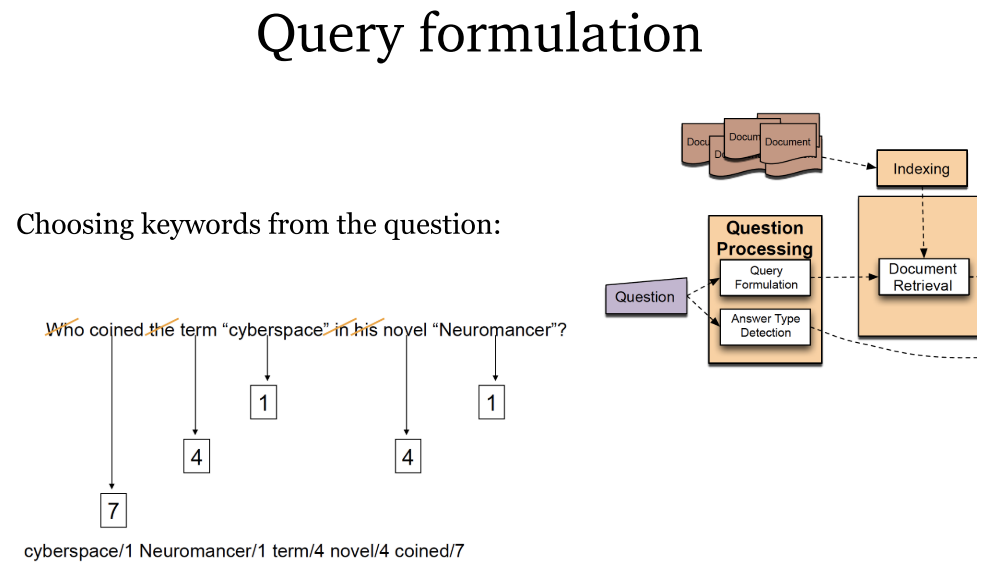


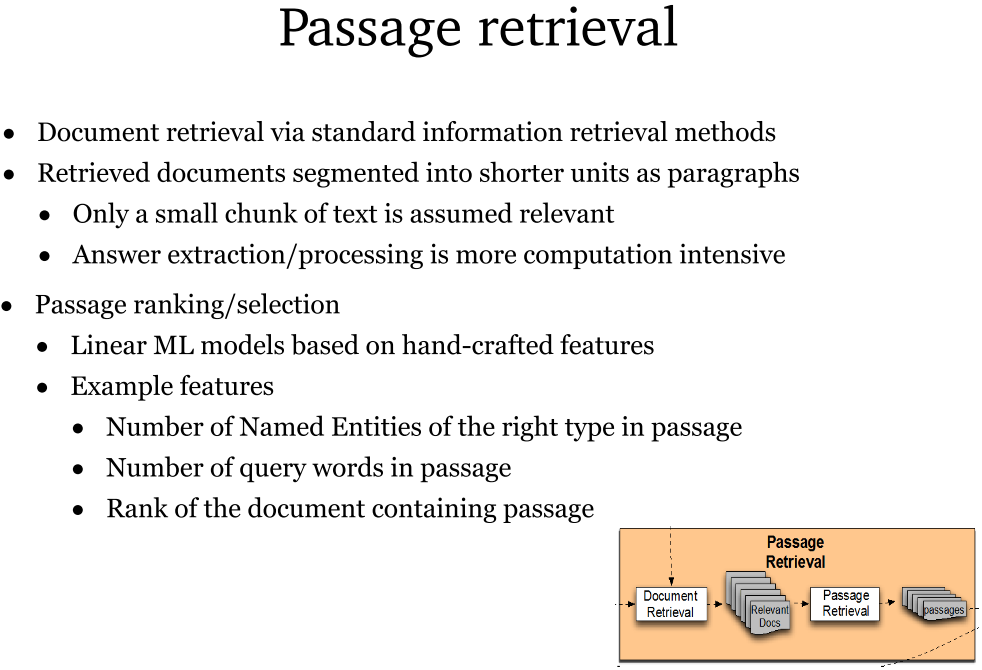
- 段落检索:通过标准信息检索方式进行文档检索,将文档划分为段落,从中提取相关答案。
- 段落排序及选择:采用基于手工特征的线性机器学习模型。特征可以是正确命名实体数量、查询词数量、含段落的文档排名等。
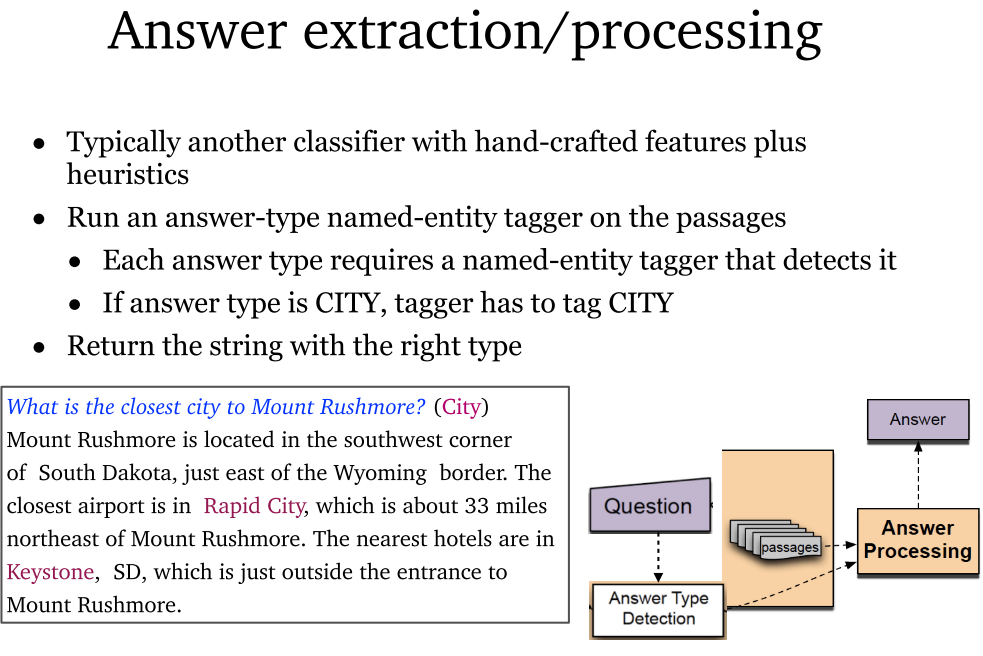
- 答案提取及处理:通常采用手工特征提取结合启发式的分类器。在段落上运行答案类型的命名实体标记器,每种答案类型都需要一个对应的命名实体标记器。返回正确答案的字符串。
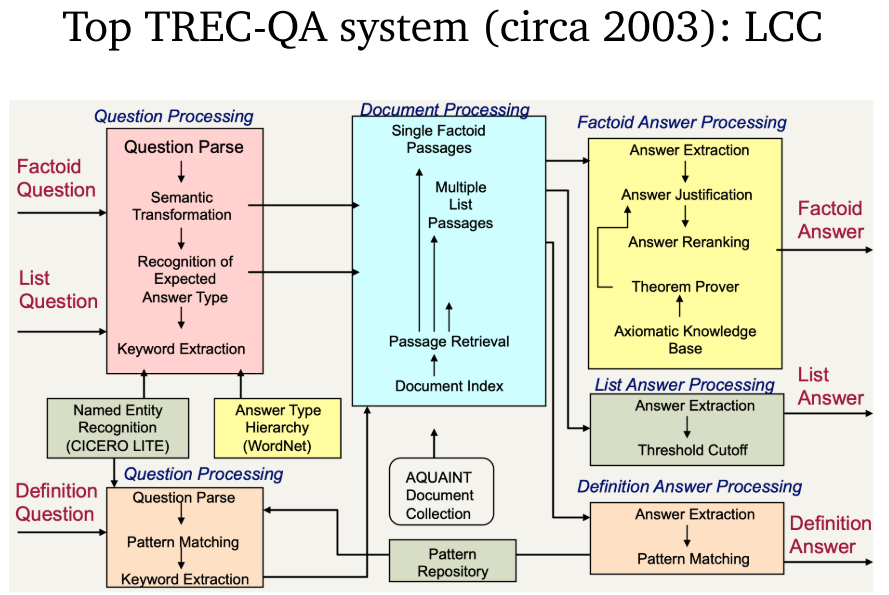
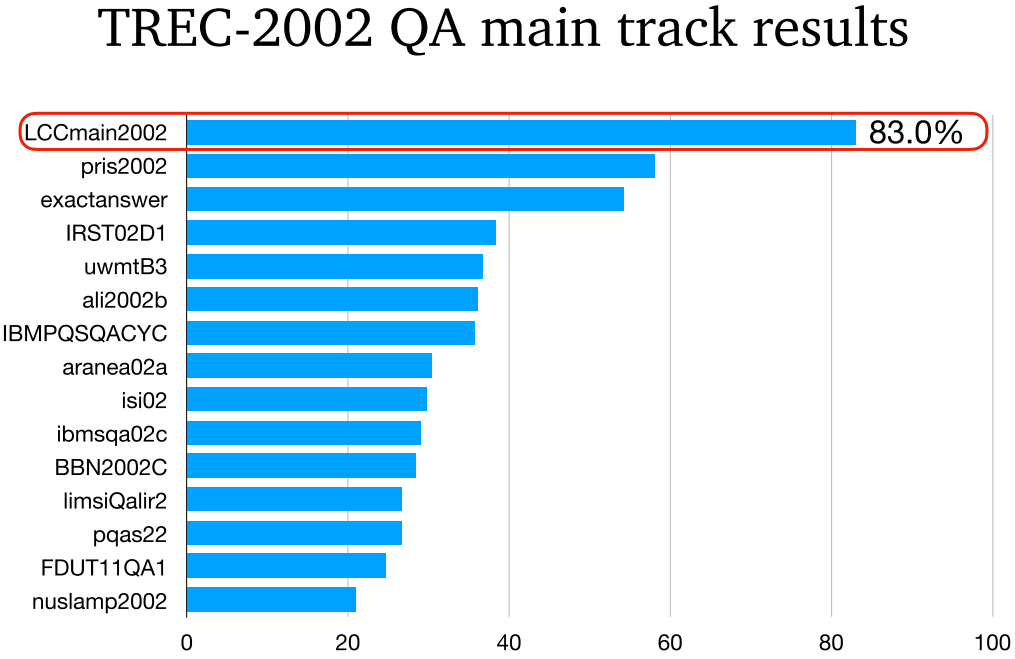
- LCC:TREC-2002 QA 最好的模型。

- AskMSR:数据密集型问答系统。采用搜索引擎作为语言模型,选择文档中最频繁出现的 n-gram 作为答案。处理 head questions 很合适,不适合 tail questions(英语语法问题)。无法提供可靠证据。
2.3 IBM Watson


- Jeopardy!的特点:问题中有答案的线索,问题很长很详细,答案很标准。
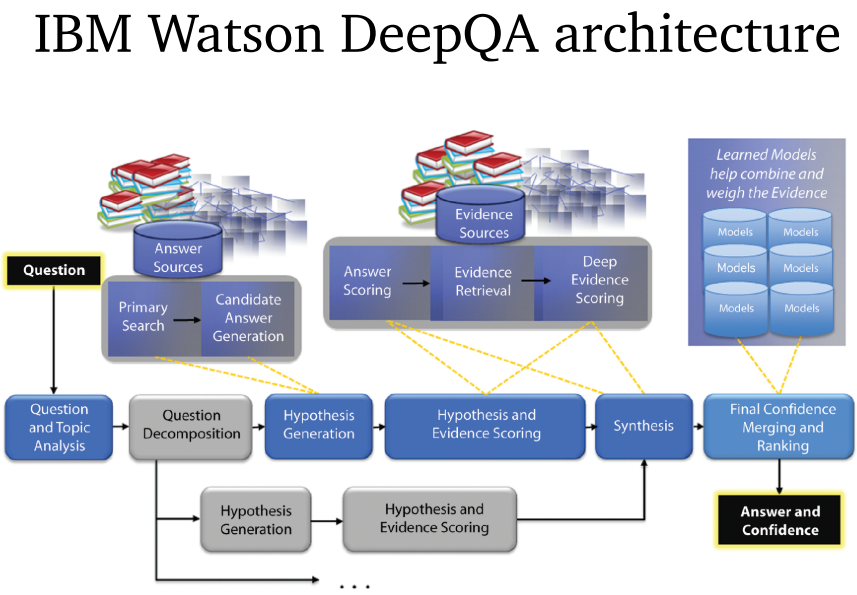
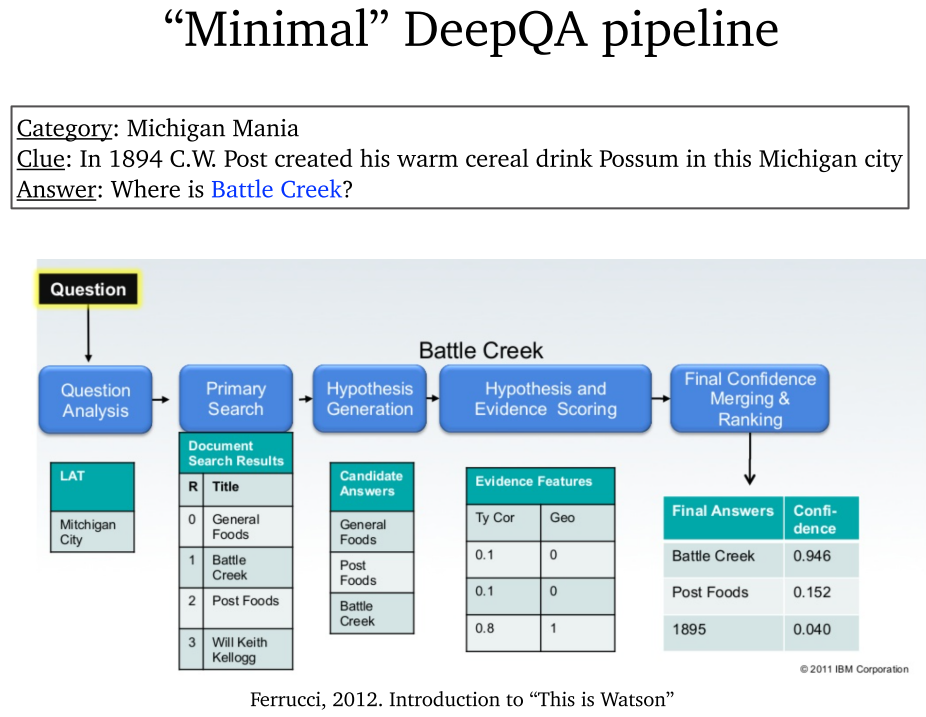
- IBM Watson:也是一种 Pipeline 深度问答模型。

- IBM Watson 成功的原因:IBM 企业代码写的很好,Jeopardy! 比较容易回答,以及 Wikipedia 是很关键的问题答案源。
- IBM Watson 影响:是 AI 的里程碑,也是问答系统热门的开始。
2.4 2013 年后的发展

- 研究趋势:宏观阅读向微观阅读。新数据集和新任务为导向。深度学习模型取得快速进展。
- 研究问题:给定上下文,通过上下文回答问题。
- 研究目标:
- 机器阅读理解 MRC。
- 解决用户信息需求:答案抽取及处理。

2.5 新数据集

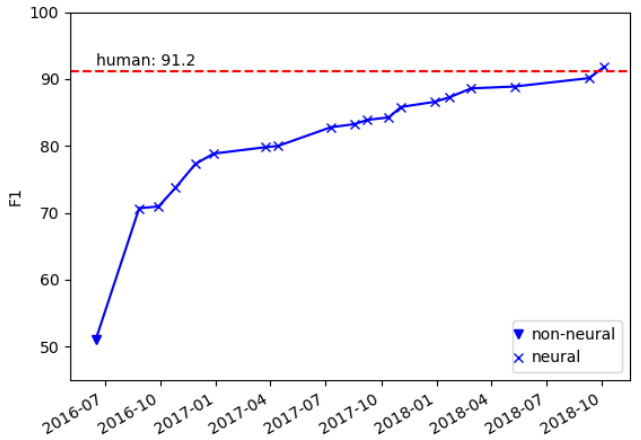


3. Dataset Evaluation
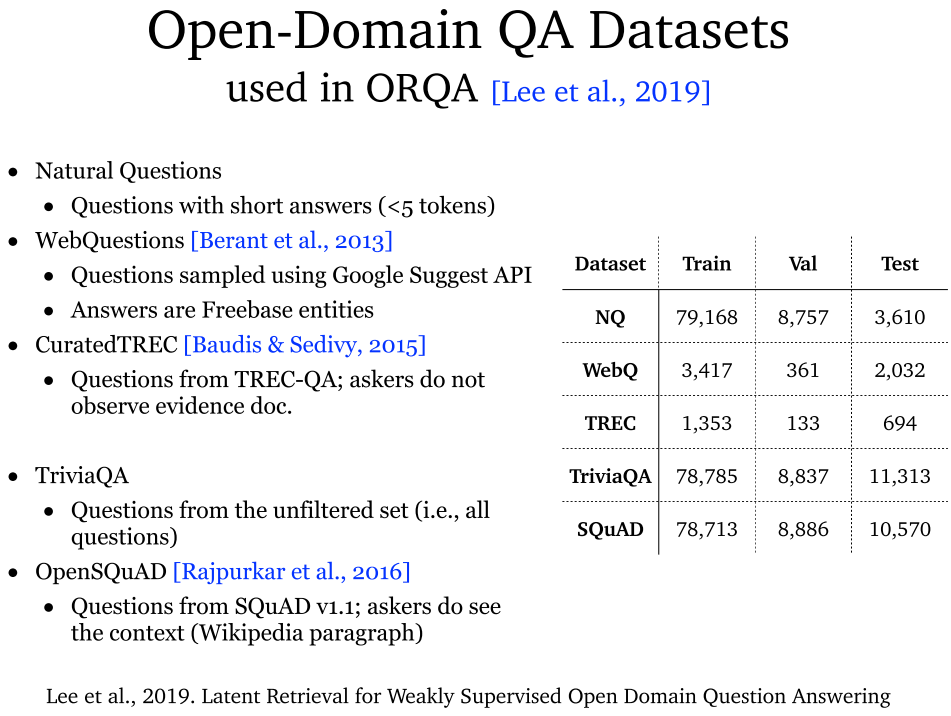
3.1 数据集概述
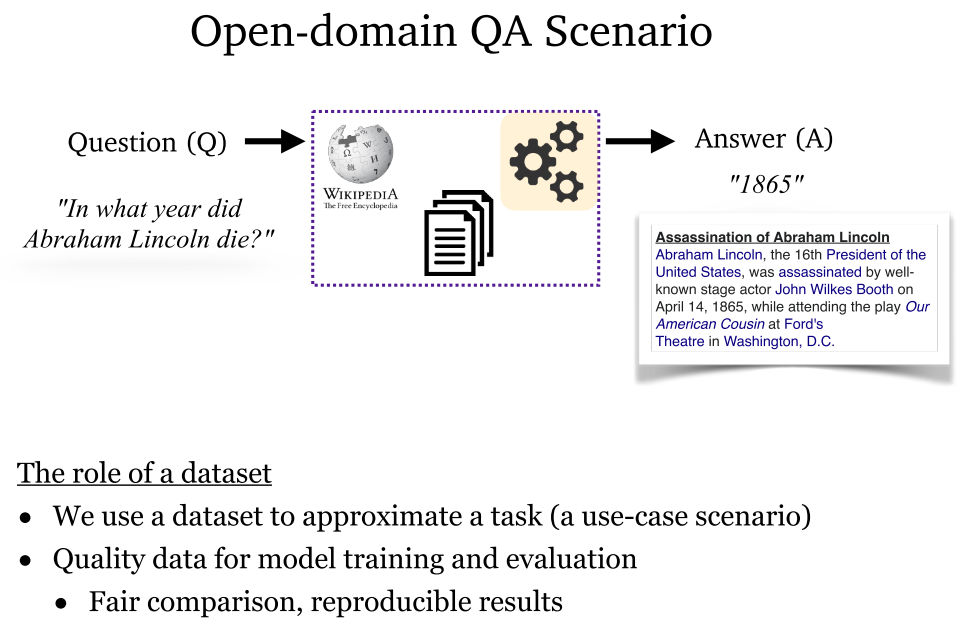
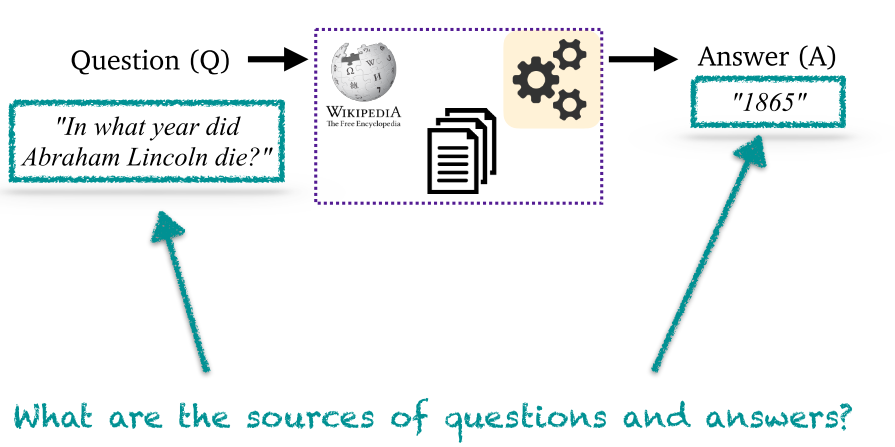
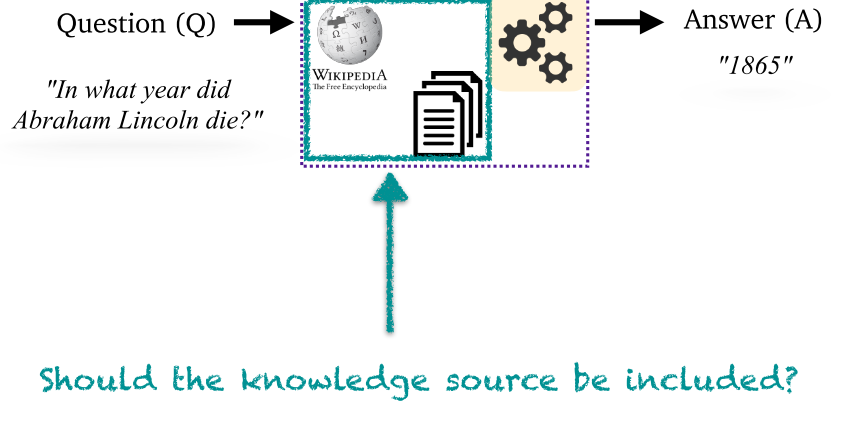
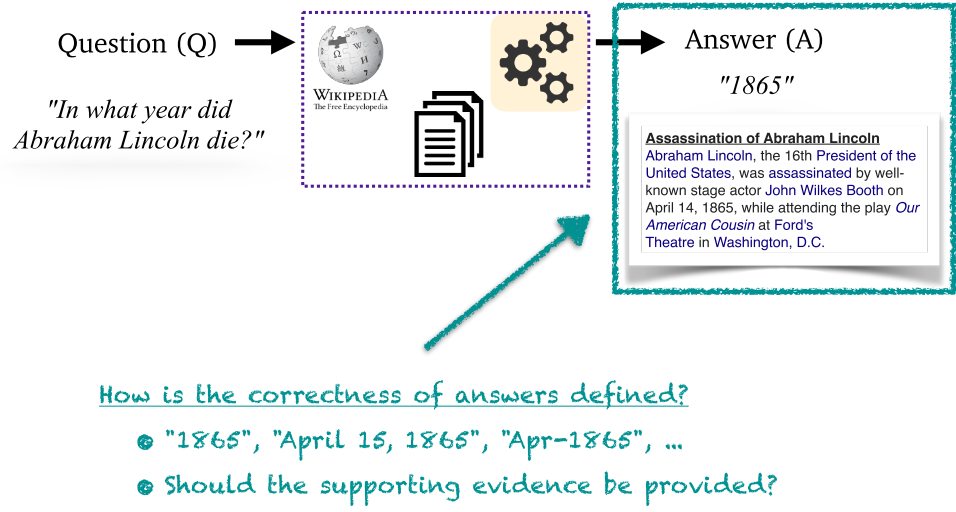


- 常用数据集及其配置:{{p1, p2, ...}, q, a} 和 {{p1, p2, ...}, {q, a}} 两种最为常用。
- 数据集分类:提供相关段落以及提供维基百科。

3.2 TriviaQA (2017)


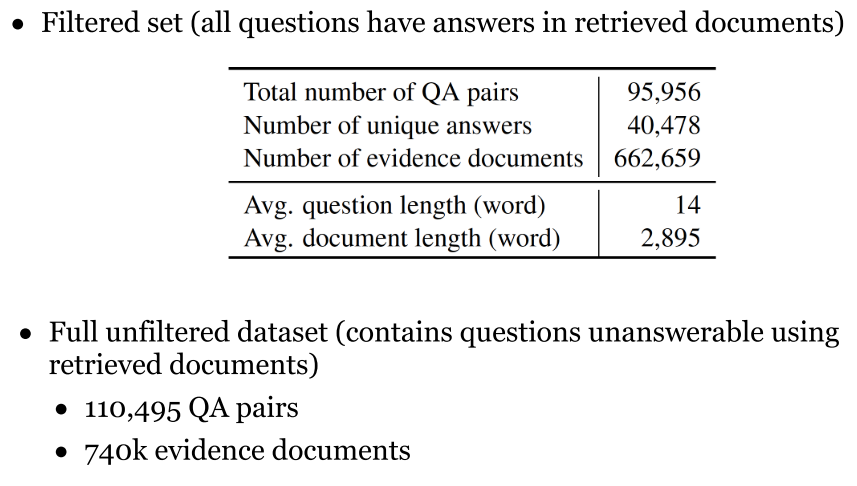
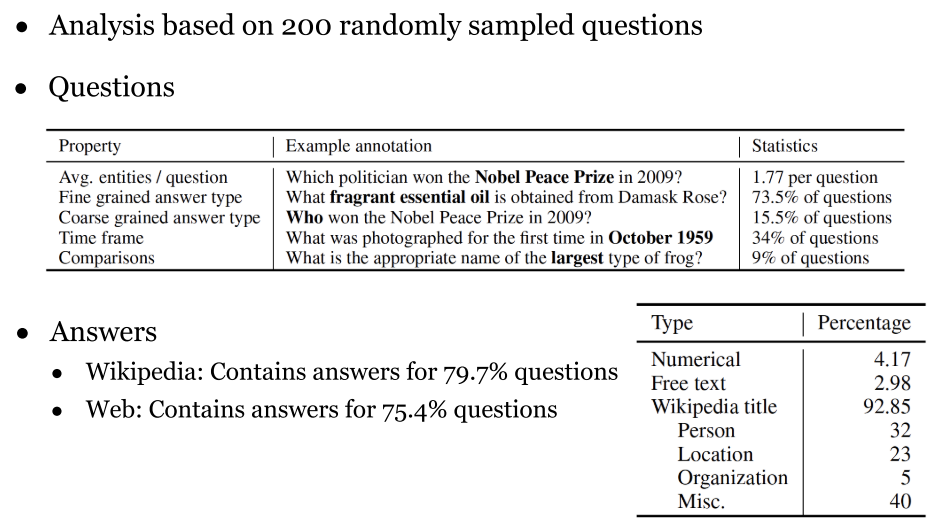

3.3 SearchQA (2017)



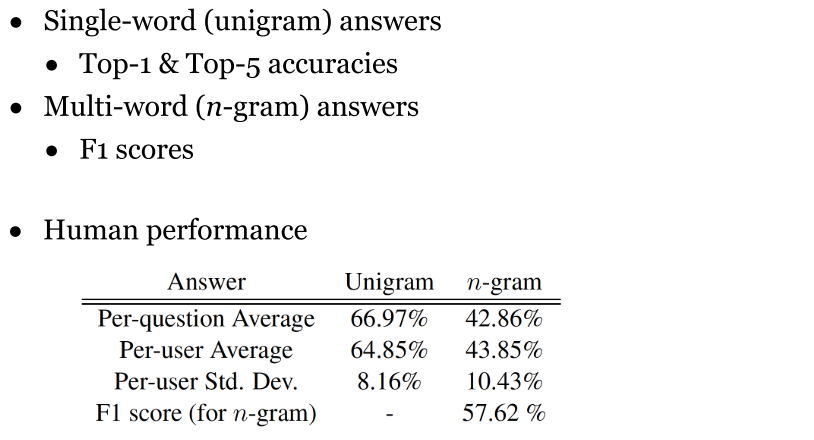
3.4 Quasar-T (2017)


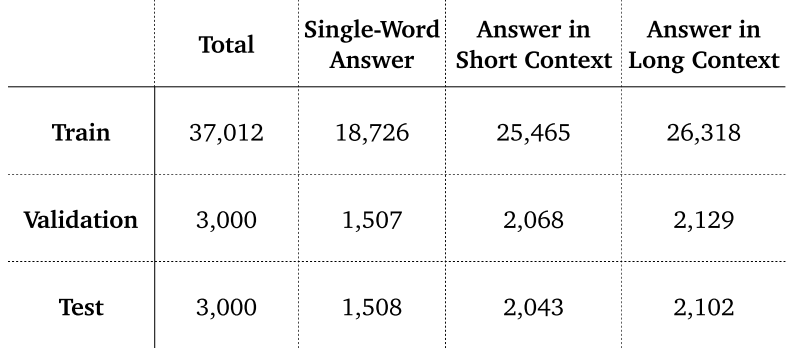
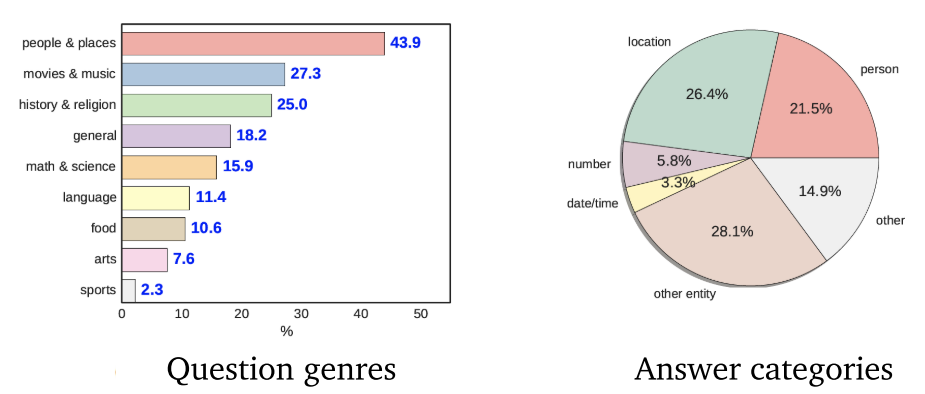

3.5 Natural Questions (2019)


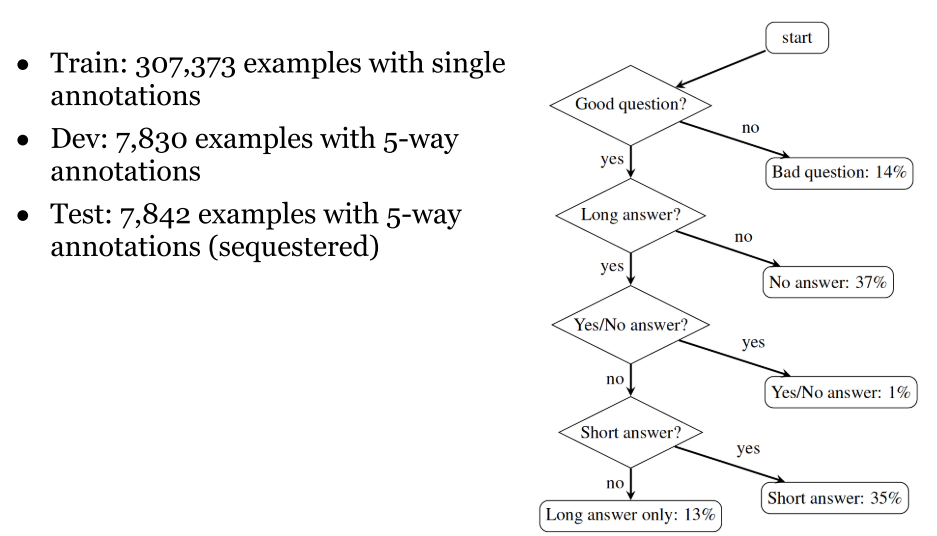
3.6 数据集评估
3.7 总结

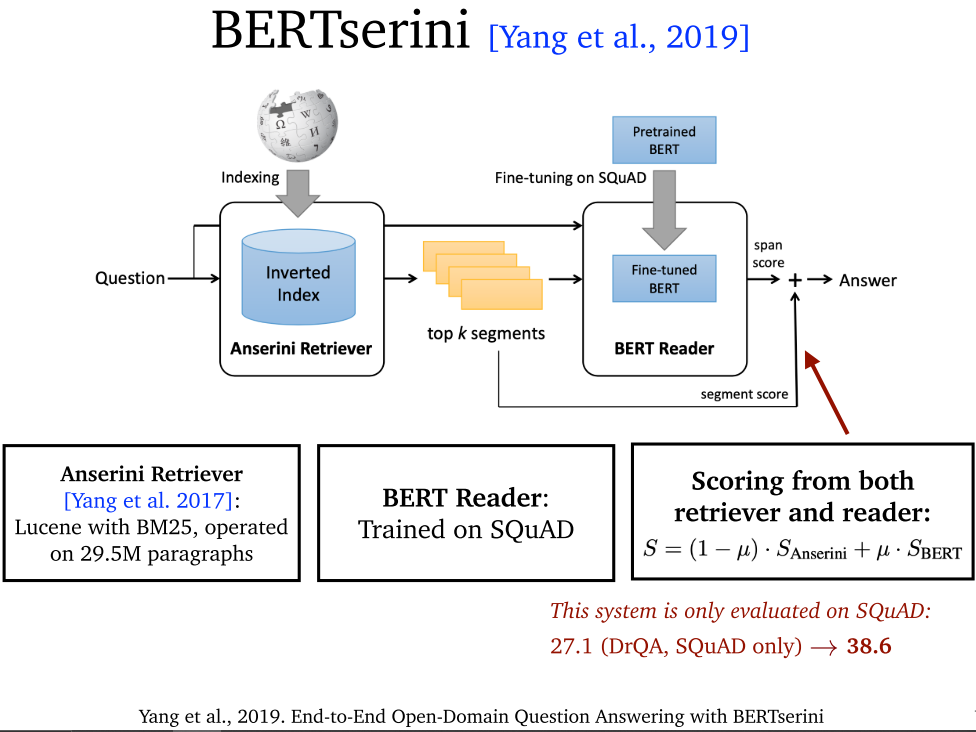
4. Two-stage Retriever Reader
4.1 概述
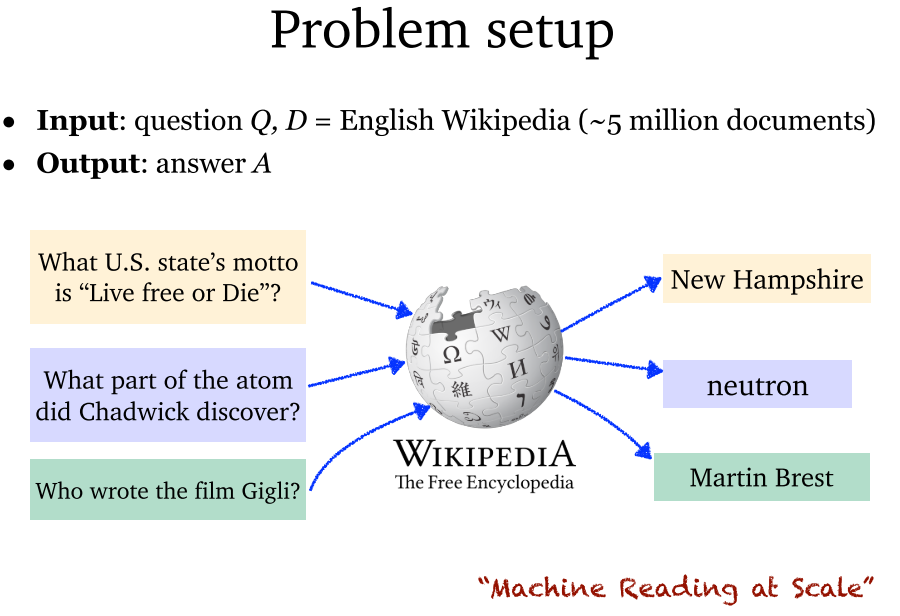

4.2 DrQA (2017)
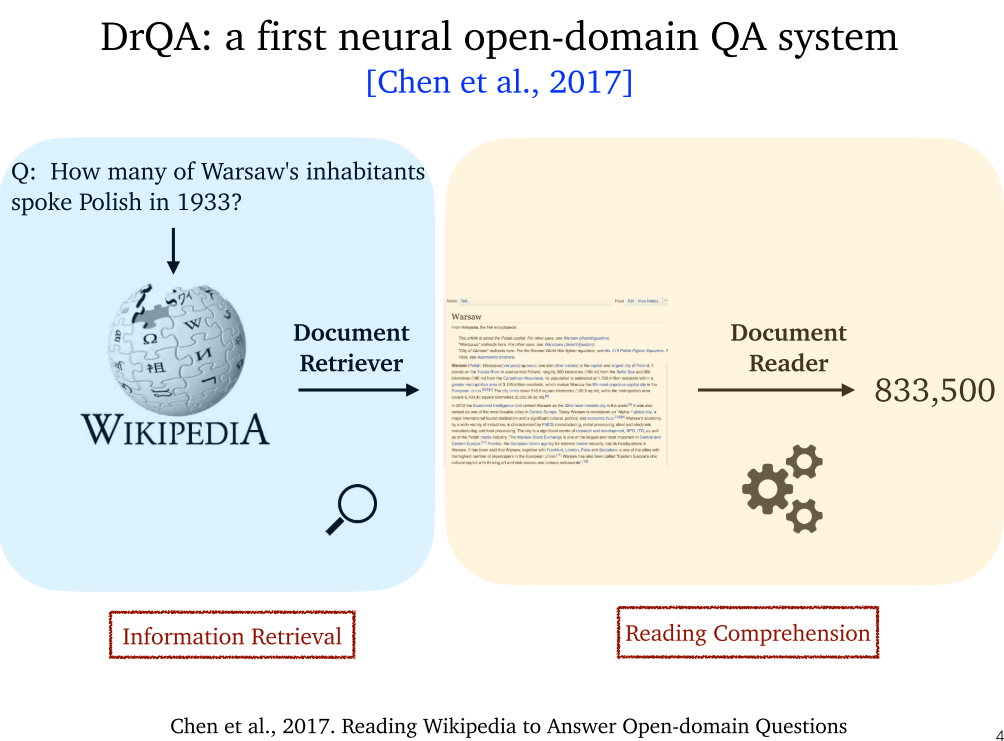

- 文档检索器:采用 TF-IDF
- TF-IDF:术语频率-反向文档频率,最基础的文档检索器,是不可训练的,基于统计信息。提供文档级别的检索。

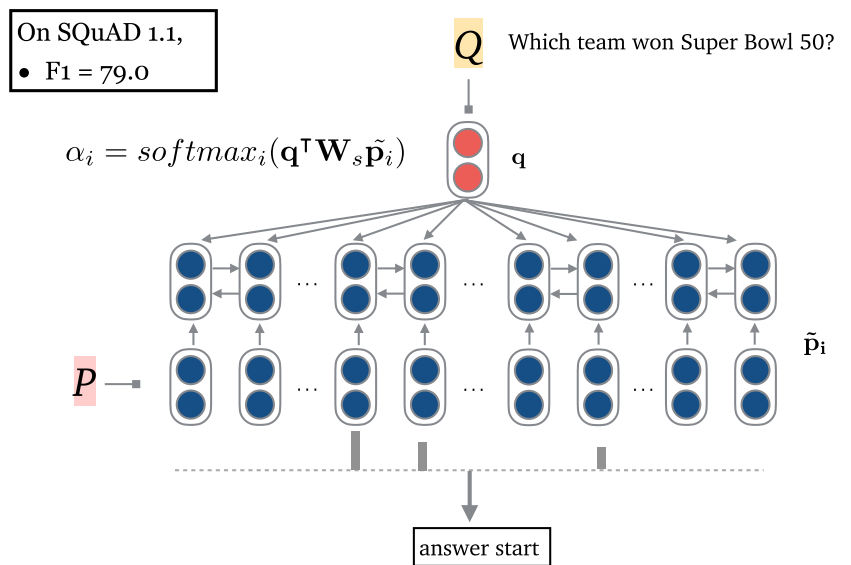
- 文档阅读器:采用 LSTM。
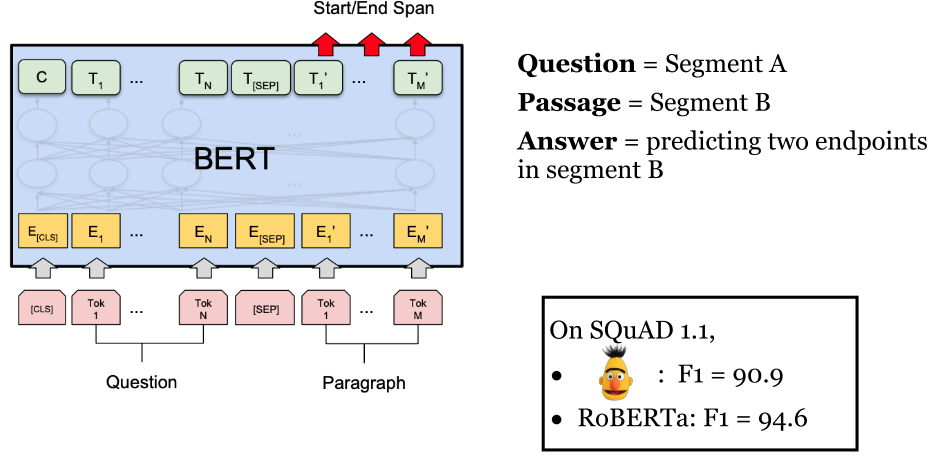
- 文档阅读器:采用 BERT。

- 扩展数据集:通过远程监督的方式,利用文档检索器,将其他数据集的 {(Q, A)} 格式应用到我们的 {(P, Q, A)} 格式上。

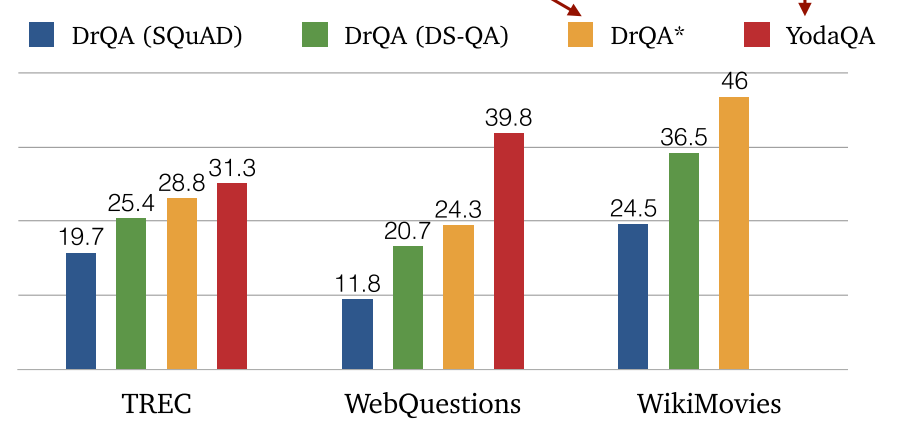

-
问题:采用文档级检索器,各个段落的答案缺少直接比较,段落重要性被忽视,检索器不能训练。
-
改进点:构建段落级检索器,构建多段落训练,构建段落排序器,构建可训练检索器。
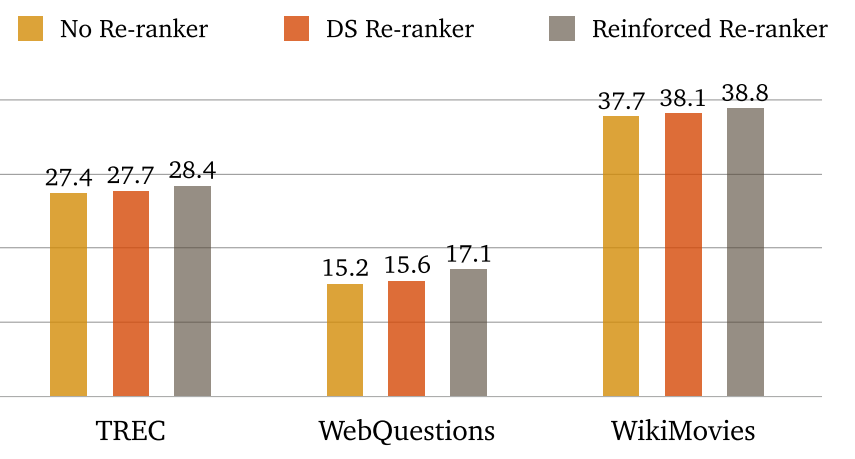
4.3 段落级检索器
4.4 多段落训练

4.5 段落排序器
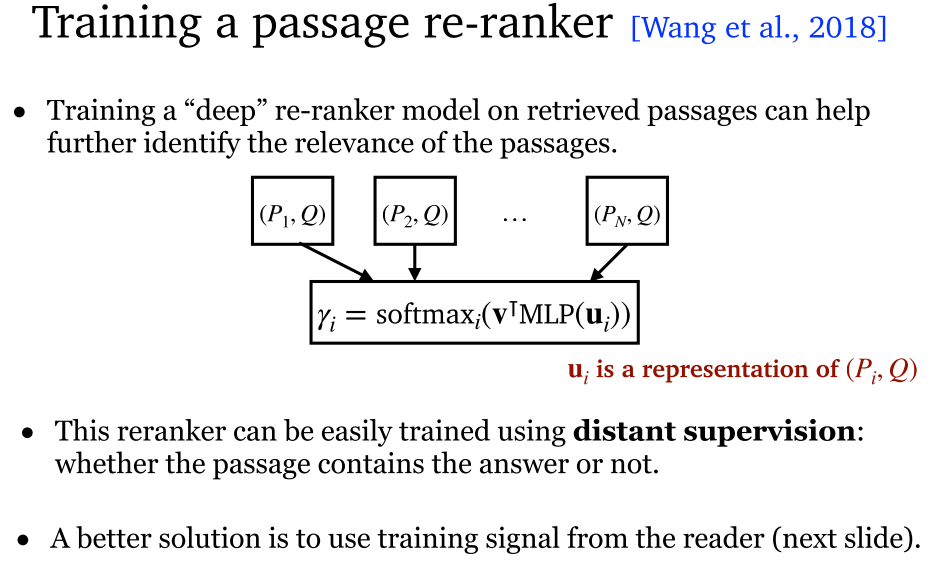
4.6 可训练检索器
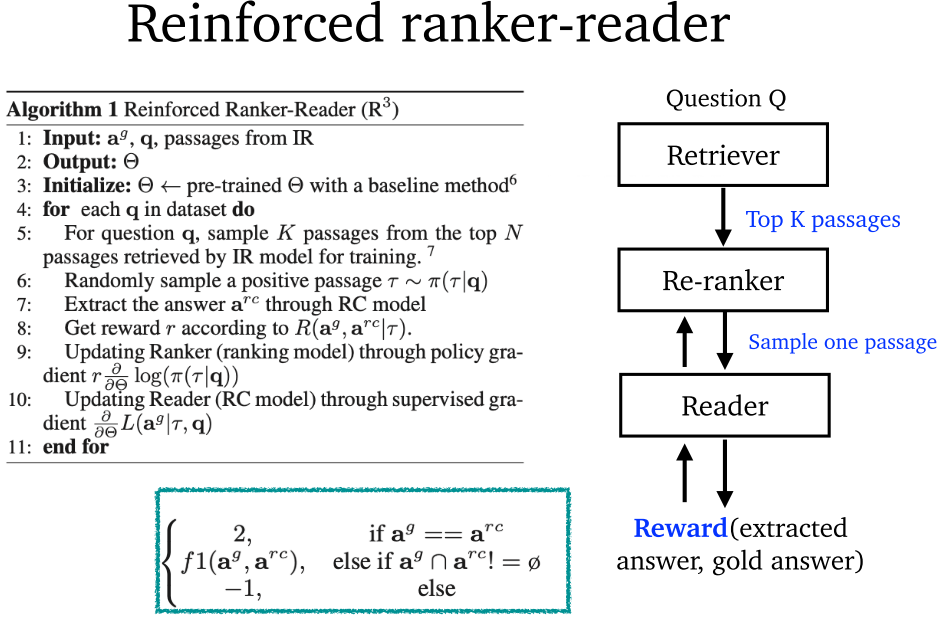
4.7 其他改进
4.7.1 答案检索器


- 答案检索器:基于 Strength 和 Coverage 进行排序。
4.7.2 Hard EM Learning

- 答案段落中有多次出现问题实体怎么办:大部分算法采用获取第一个所在的句子作为答案所在句子,或者随机选一个作为答案所在句子。
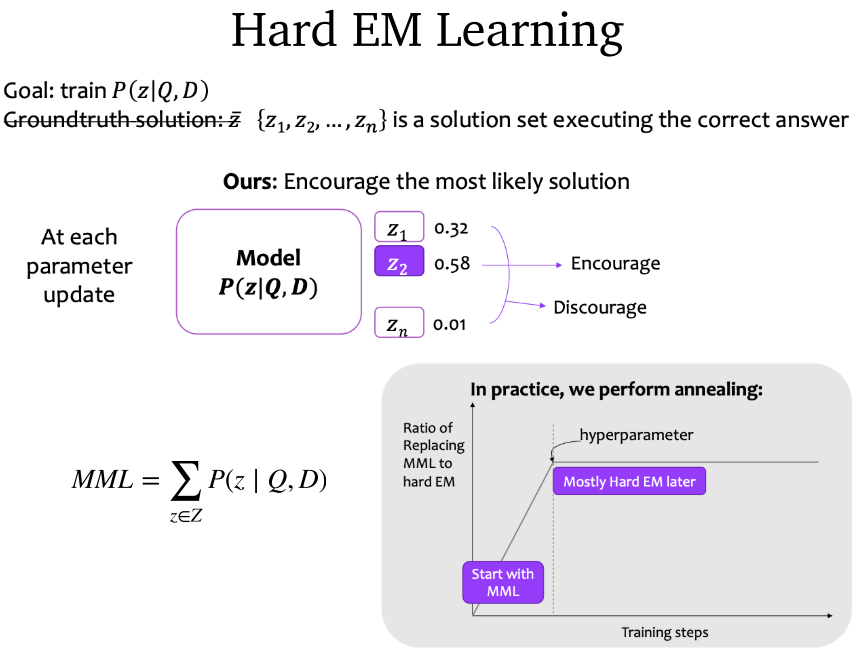
- Hard EM Learning:鼓励正确的获取答案所在句子。
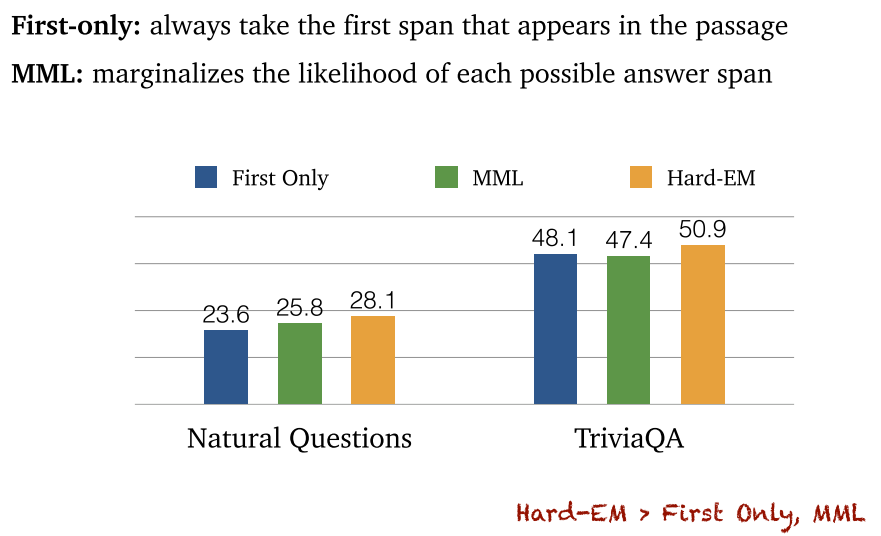
4.8 总结

5. Dense Retriever End-to-end Training
5.1 稀疏表示和密集表示


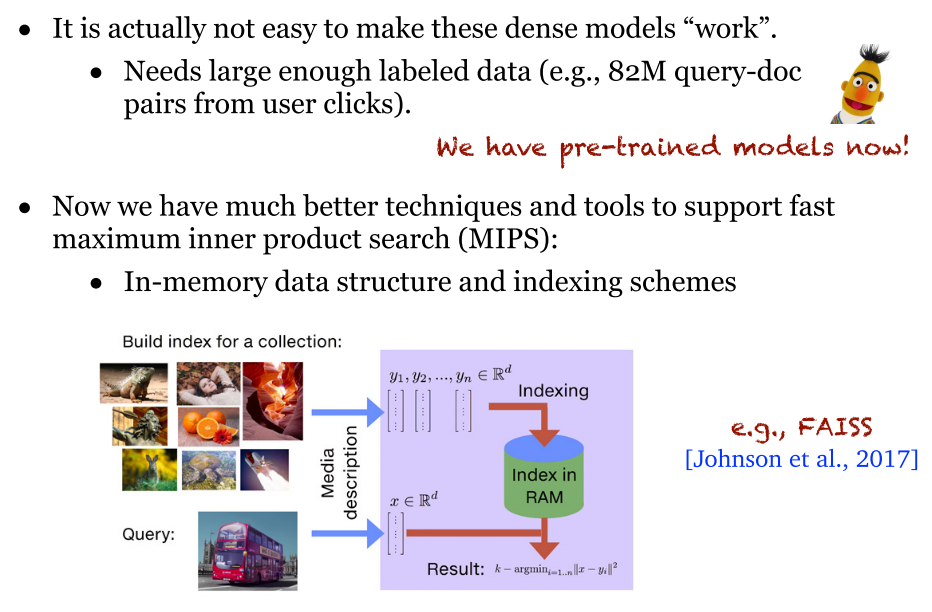
- 密集表示:用于处理大量数据。现在的技术已经能够方便密集表示进行各种处理,比如点积向量检索 MIPS。同时,现在也有了预训练模型。
5.2 ORQA (2019)

- ORQA:将文章分为 288 个字的段。
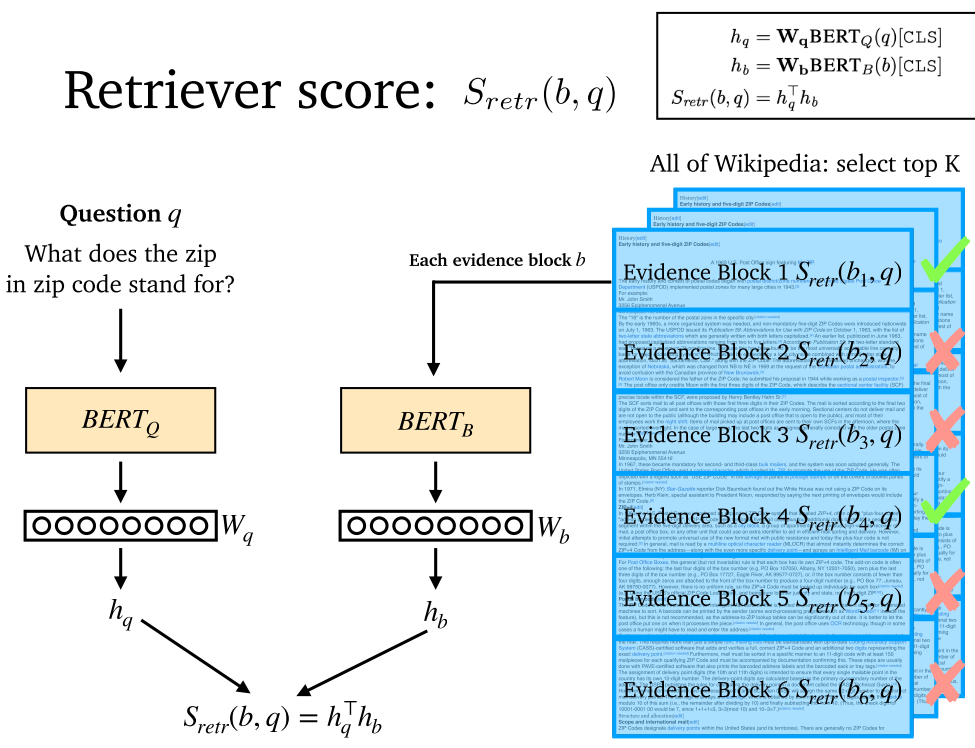

- ORQA:训练跨度指针。
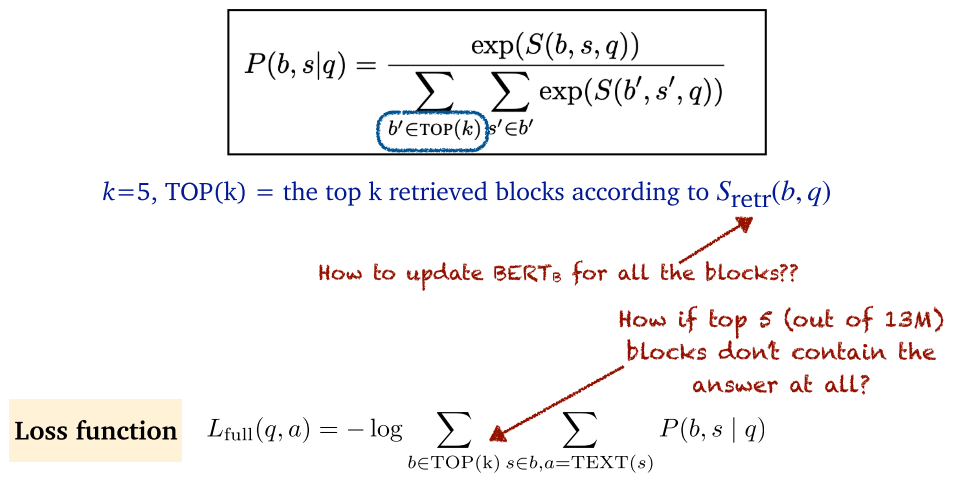

- ORQA:为了避免 top5 文档没有答案,先用大量数据训练(c=5000),确保 top5 文档中有正确答案。

- ORQA:采用 ICT ,训练模型找正确上下文的能力。下面提到, 在 90% 的实例中删除句子。

5.3 REALM (2020)
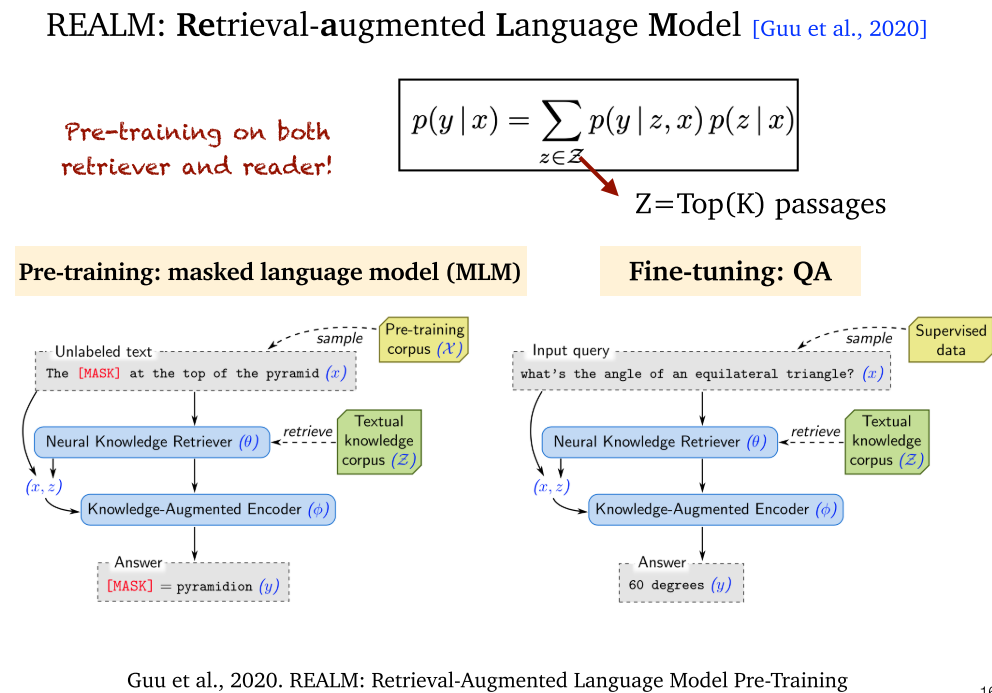

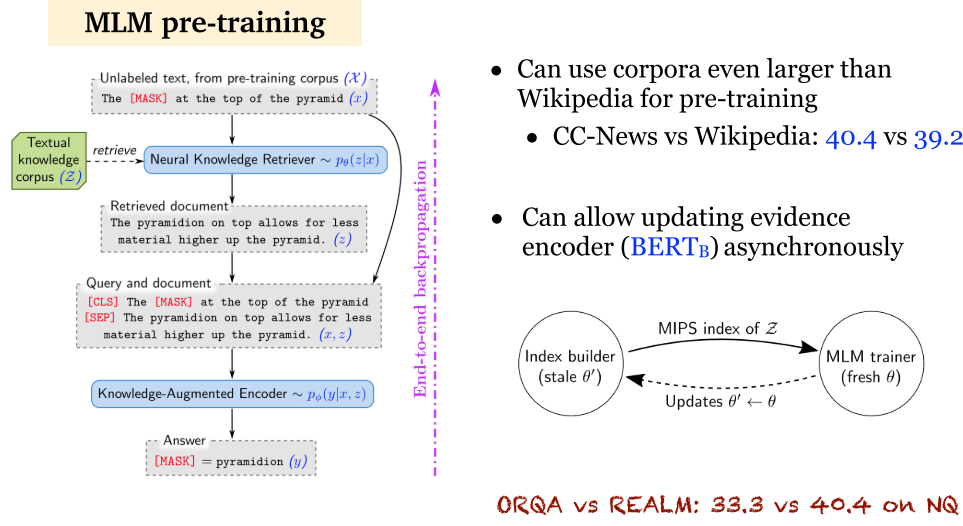
- REALM:通过 MLM 进行预训练,再利用问答对进行微调。MLM 和 BERT 的 MLM 一样。
5.4 ORQA 和 REALM 分析

- ORQA 和 REALM:都采用了联合训练文档检索器和文档阅读器。预训练过程在这两种方法中十分重要,然而,预训练其实也不是必须的。
5.5 DPR (2020)
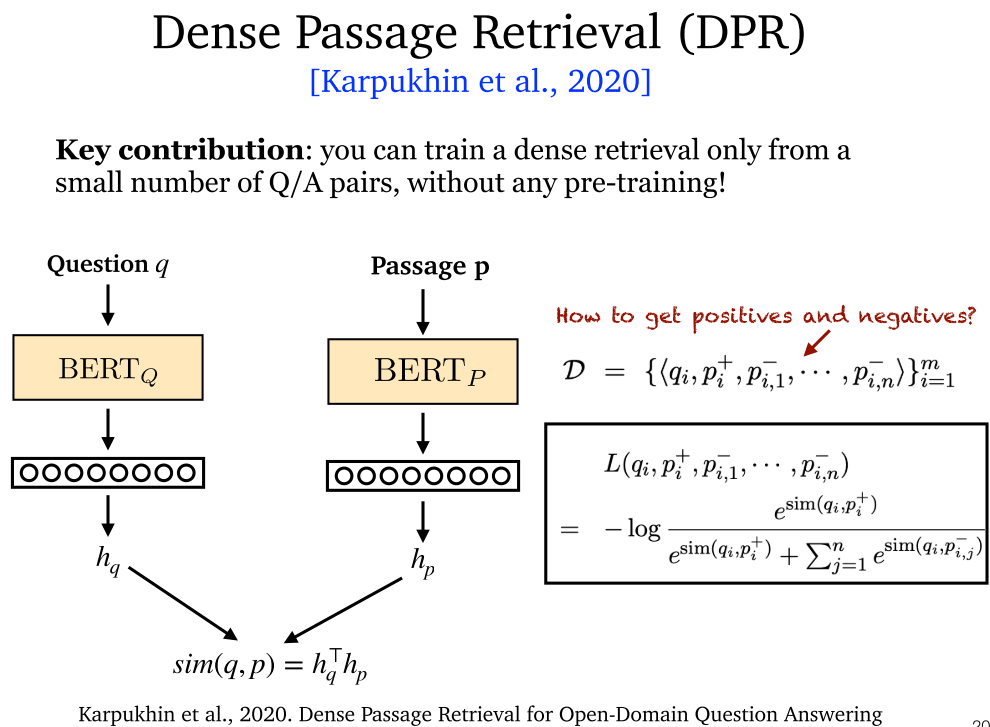
- DPR:通过少量数据,生成密集表示!

- DPR:利用少量训练样本,生成新的正例和负例。

- DPR:利用 n 对问答对生成 n^2 对问答对。
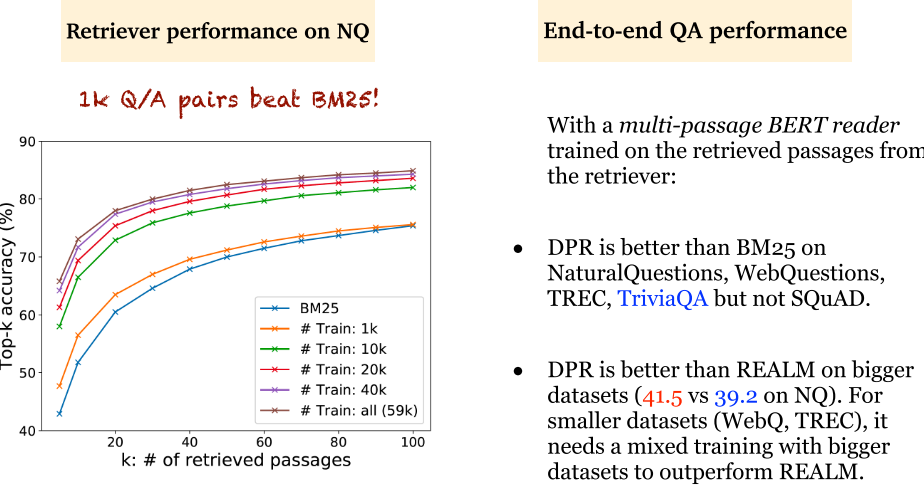
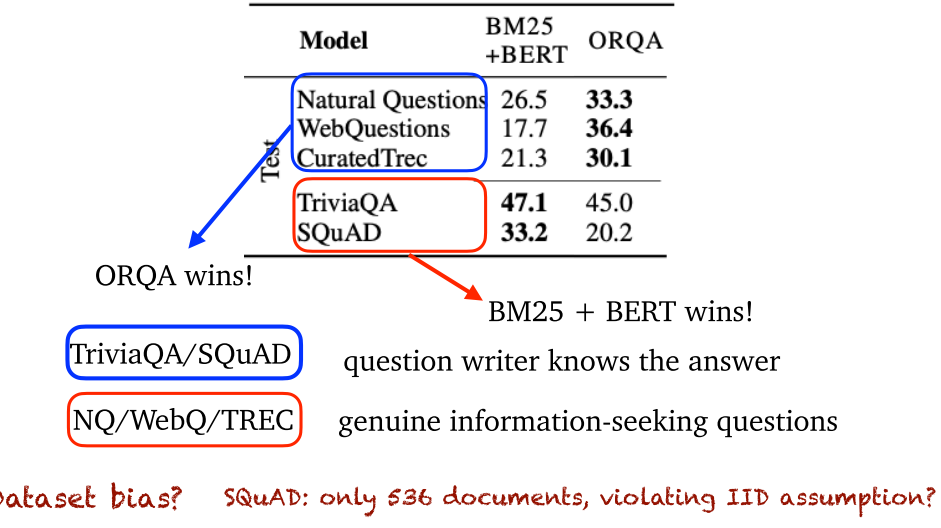
- DPR:仅使用 1k 问答对,就击败了 BM25。但是对于小数据集,还是预训练方法更好。

- DPR 带来的思考:
- 不一定需要预训练。
- 联合训练不一定优于管道方式,有时管道方式更快更好。
- 不一定需要阅读理解训练,只是用问答对也可以训练很好。
- BM25 + DPR 可以轻微改善 DPR 的效果。
5.6 RAG (2020)
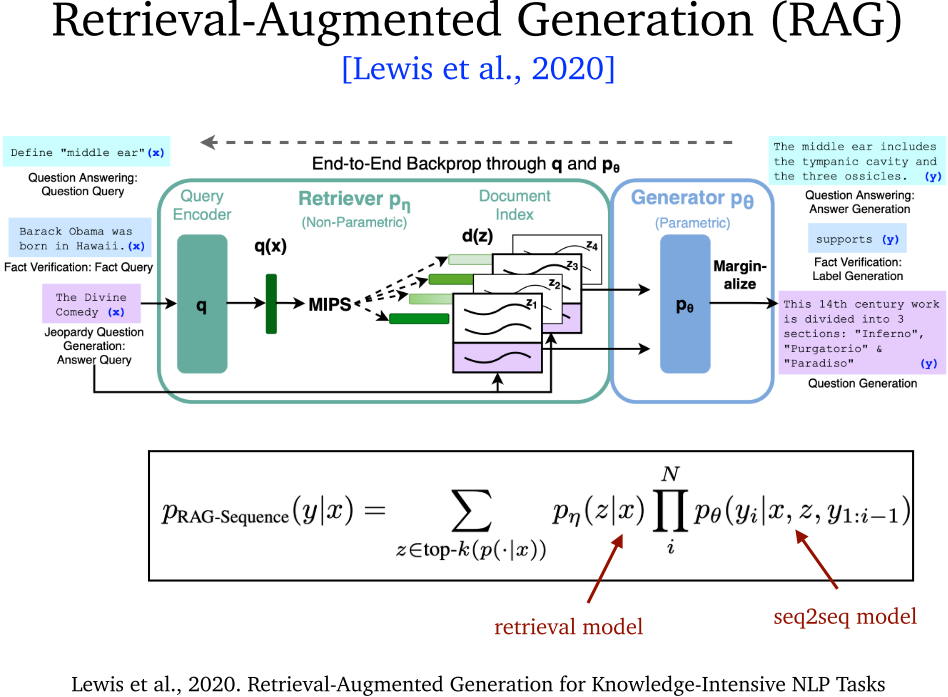

- RAG:将 DPR 和 BART 结合起来,构建了编码器、解码器模型。
5.7 DenSPI (2019)
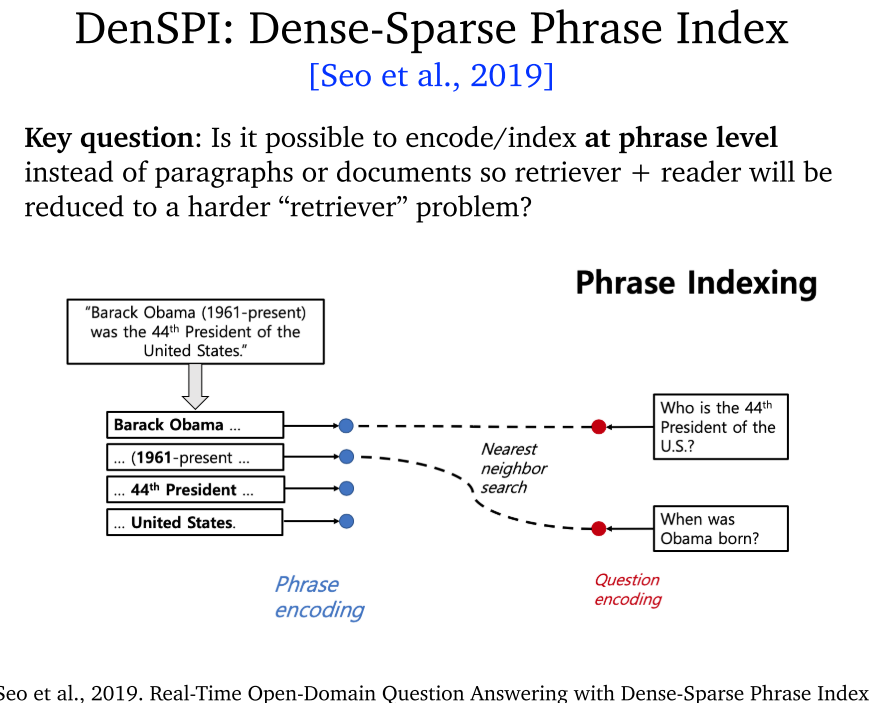
- DenSPI:将编码降到词组级别(phrase level 不是 word level)。密集-稀疏词组索引。
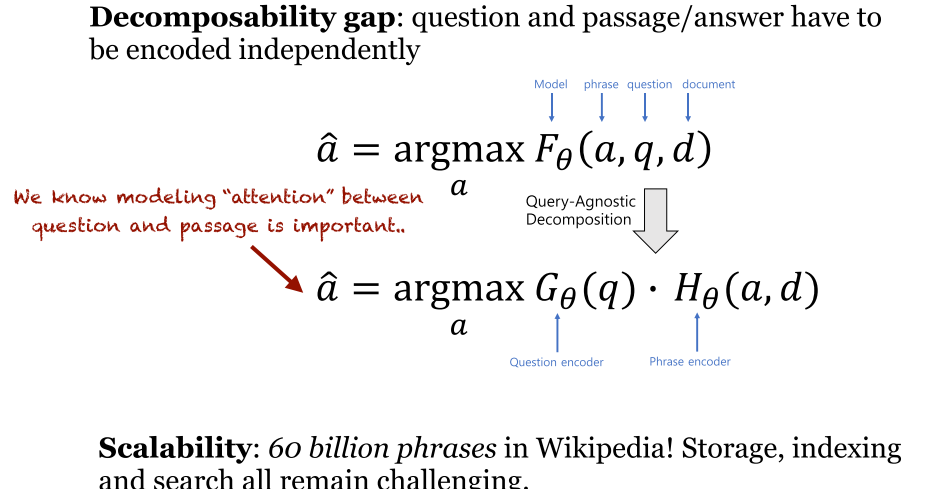
- DenSPI:里面的 a 是词组表示。生成了 60 billion 的词组,很难处理,怎么办呢?采用了下面的密集-稀疏表示法。
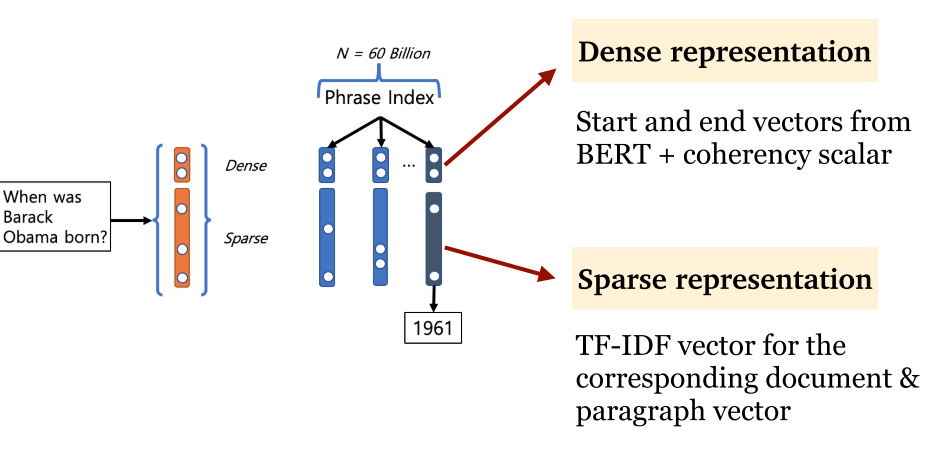
- DenSPI:密集-稀疏表示法,上面是 BERT 得到的密集表示,下面是 TF-IDF 向量的稀疏表示。通过这种方法,极大减少了存储数量和计算时间。
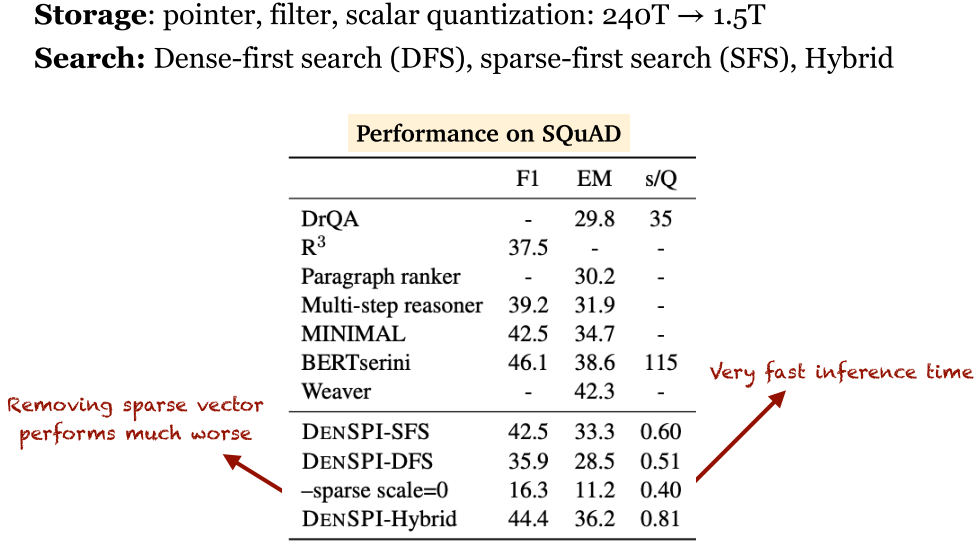
- DenSPI 性能:可以看到 DenSPI 效果拔群。
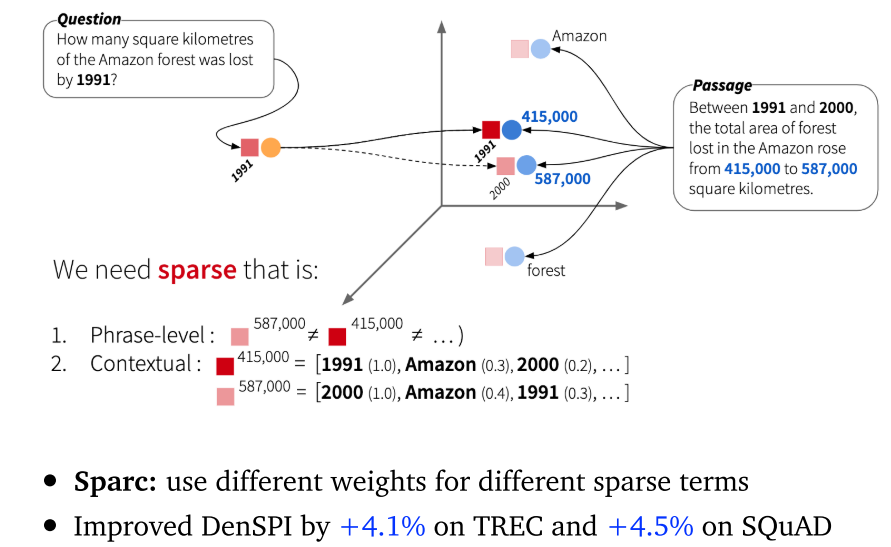
5.8 总结
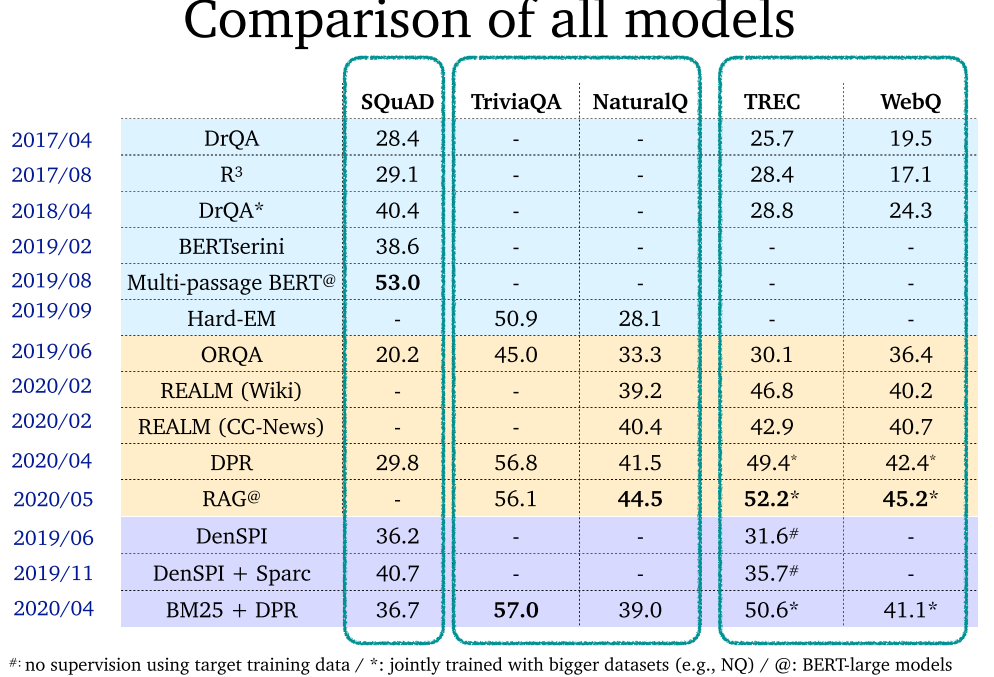

- ORQA / REALM:首先证明了可以联合训练检索器和阅读器,而无需任何稀疏的信息抽取组件。同时,需要新颖的与训练算法。
- DPR / RAG:无需预训练,可以只从问答对中学习密集表示。
- DenSPI / Sparc:可以在短语级别索引和检索,无需阅读器。推理时间非常快,性能稍差。这也证明了稀疏特征十分重要。
6. Retrieval-free
6.1 概述

- 无检索器模型:将预训练语言模型作为知识仓库。毕竟预训练语言模型是基于 Wikipedia 等大规模现实世界数据训练的,所以是可以的。
6.2 GPT-2 (2019)
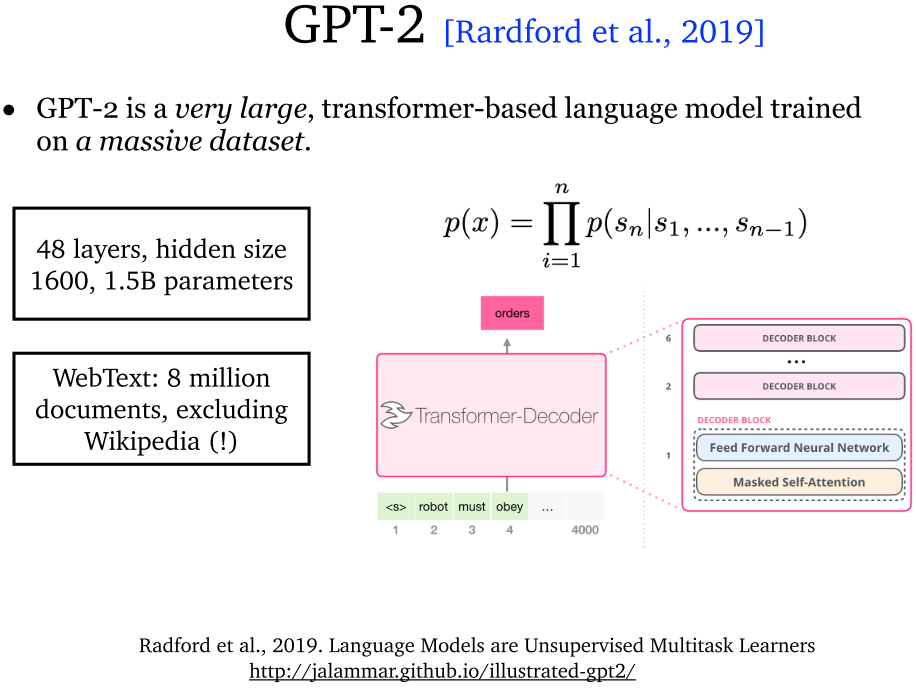
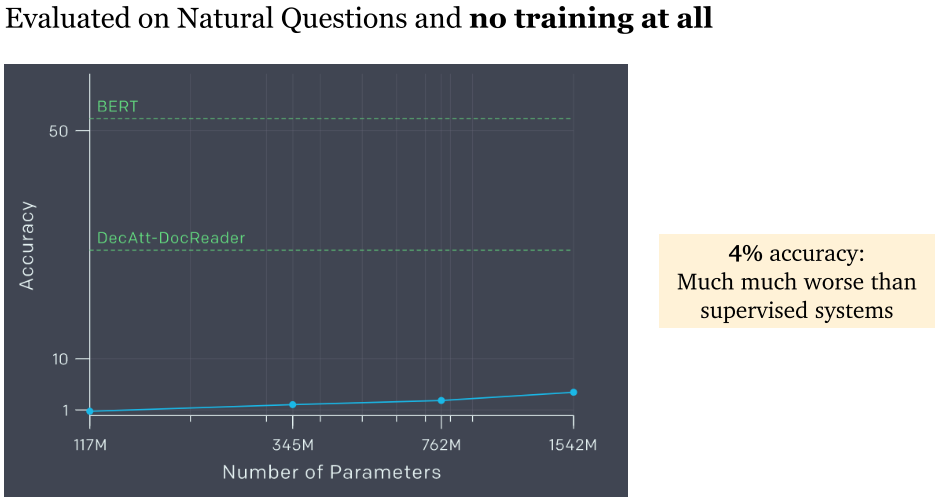
- GPT-2:采用巨量数据作为数据来源进行训练。结果模型精度只有 4%,非常糟糕。原因是采用了零次学习 (zero-shot learning)。零次学习是希望模型能够对没见过的类别进行分类,从而具有推理能力。
6.3 GPT-3 (2020)
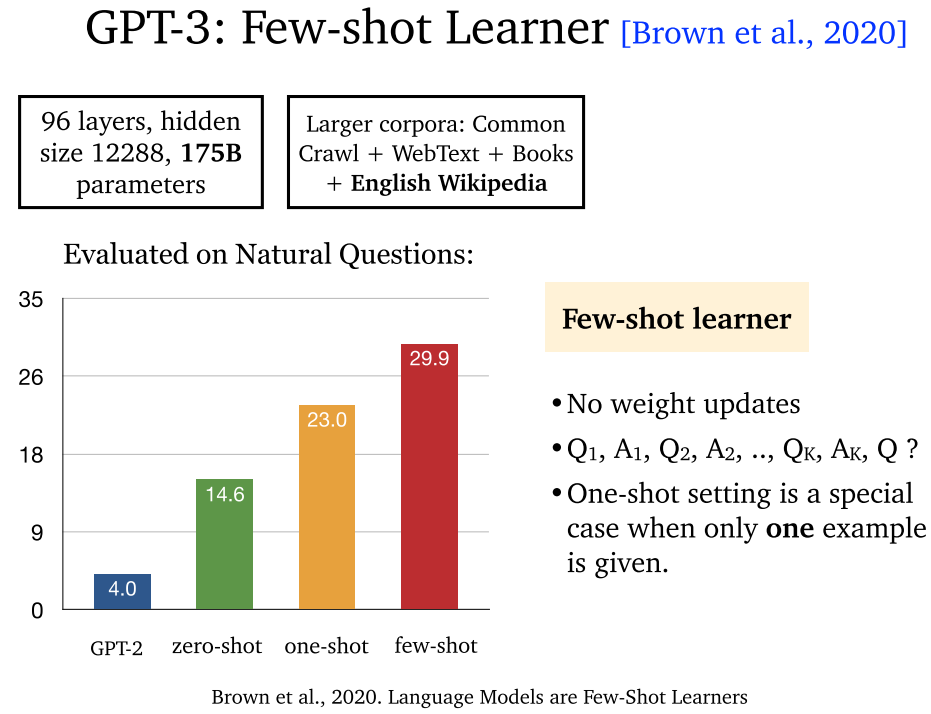
- GPT-3:采用小样本学习 (few-shot learning)。
6.4 GPT-5 (2020)

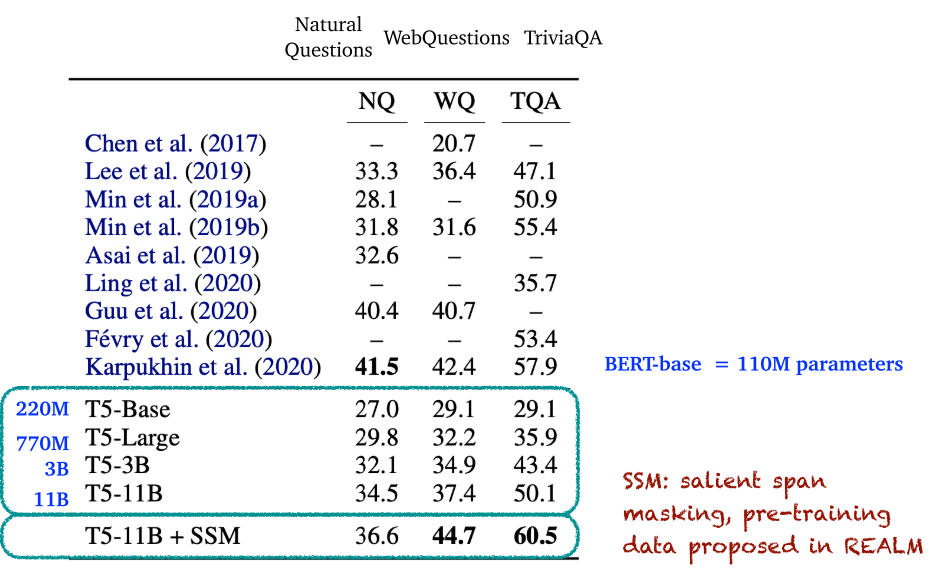
6.5 总结

- 无检索器模型:性能受到模型大小的影响。
7. Knowledge Base
7.1 概述

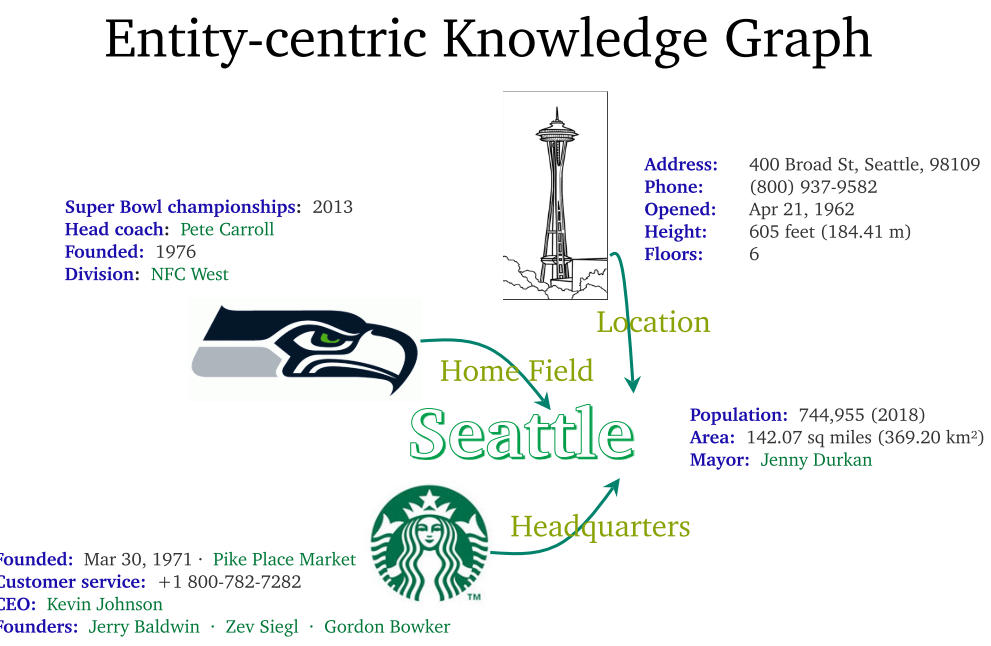
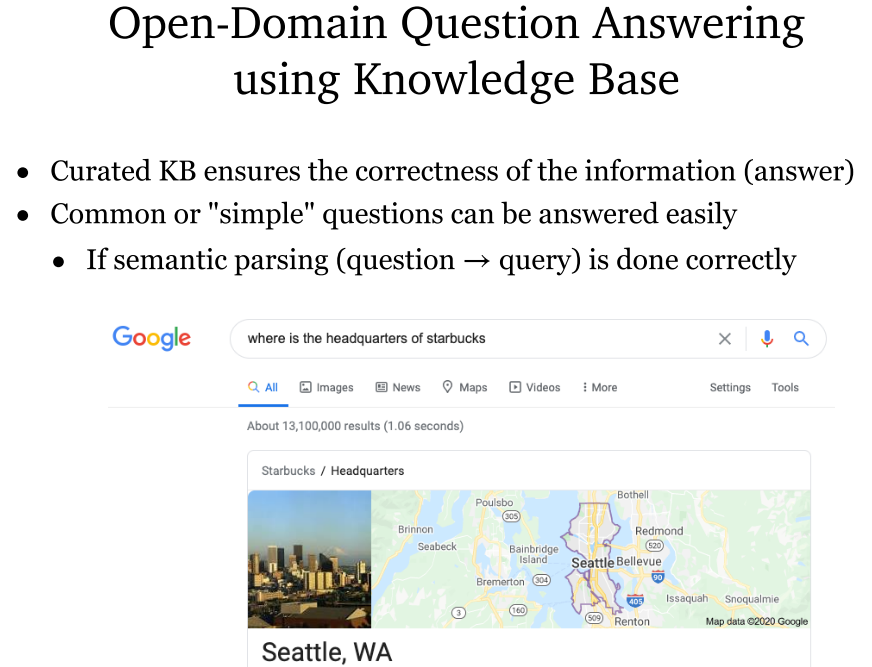
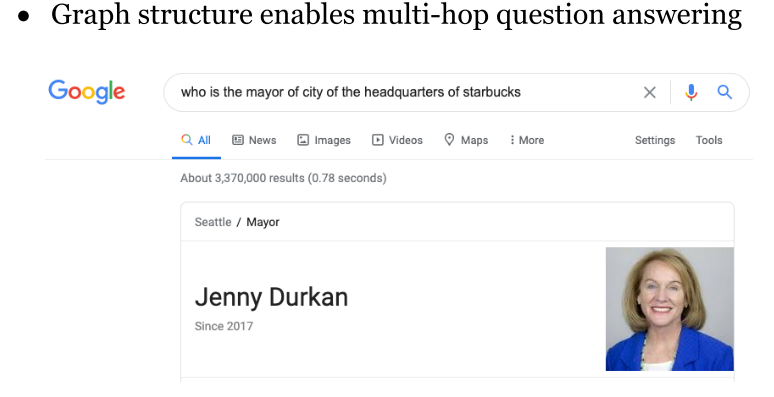
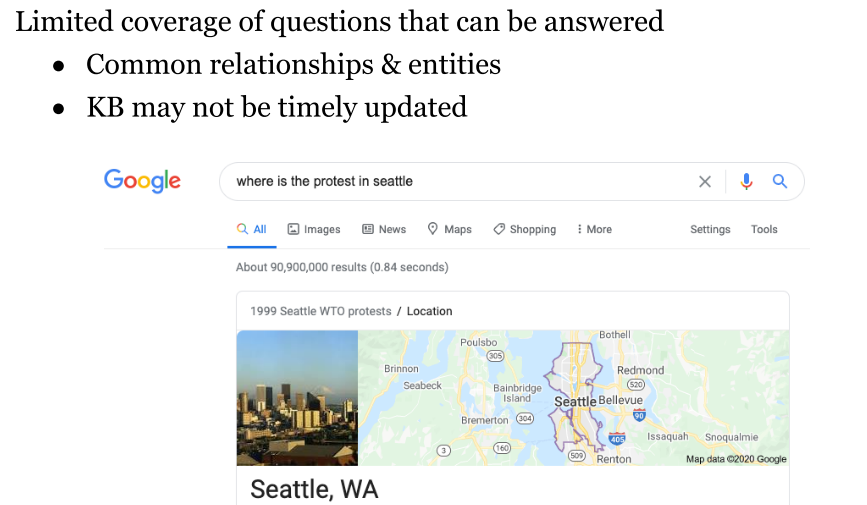
- 基于知识图谱的问答系统:以实体为中心的知识图谱,图结构能够帮助搜索。问题是知识图谱可能不具有时效性。
7.2 知识图谱与文本信息结合
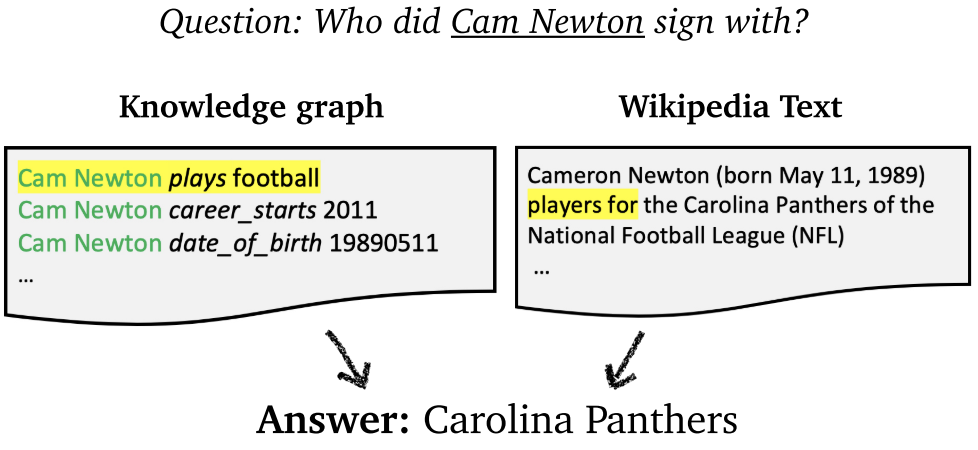

- 普遍方式:通过实体链接,将文本的实体与知识图谱关联起来。利用图表示获取答案。
7.3 WebQSP (2016)

- WebQSP:基于 Freebase 实现问答。主要是依靠 SPARQL 表示。
7.4 GRAFT-Net (2018)
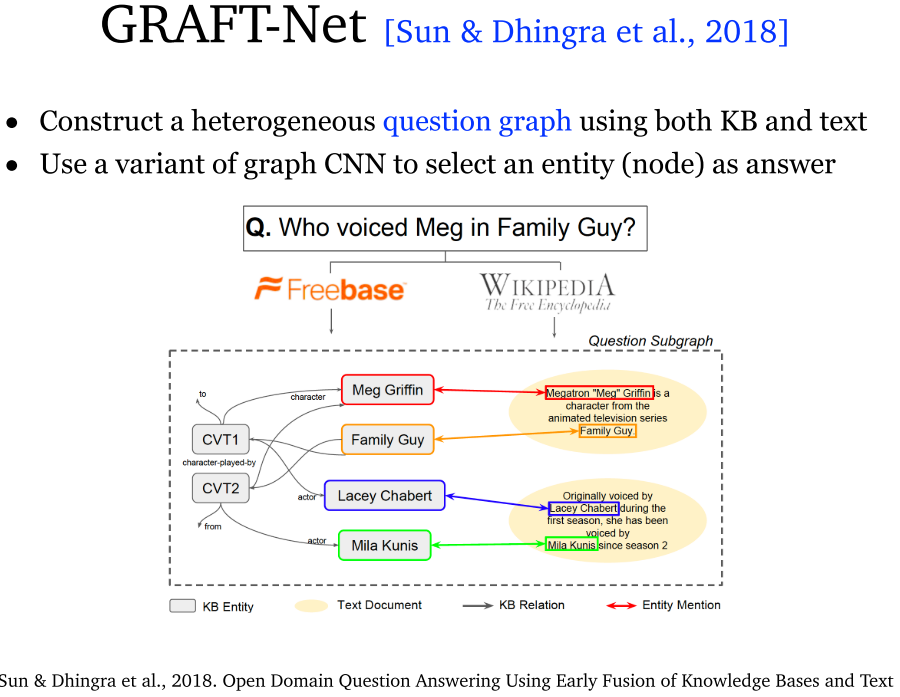


- GRAFT-Net:构建了知识图谱检索器和文本检索器,分别获取知识图谱中 top 内容和 Wikipedia 中 top5 内容。其中使用了一种后面还会提到的图传播算法,通过图关系获取实体的表示,并训练二分类器判断实体是否为答案实体。
7.5 PullNet (2019)


- PullNet:基于GRAFT-Net 进行修改,采用 GCN。每次都找到实体的邻域实体,并加入到图中。最后在图中找到答案实体。要求在问题实体和答案实体之间找到最短路径,同时长度不能超过最大长度。
7.6 Knowledge-aware Reader (2019)
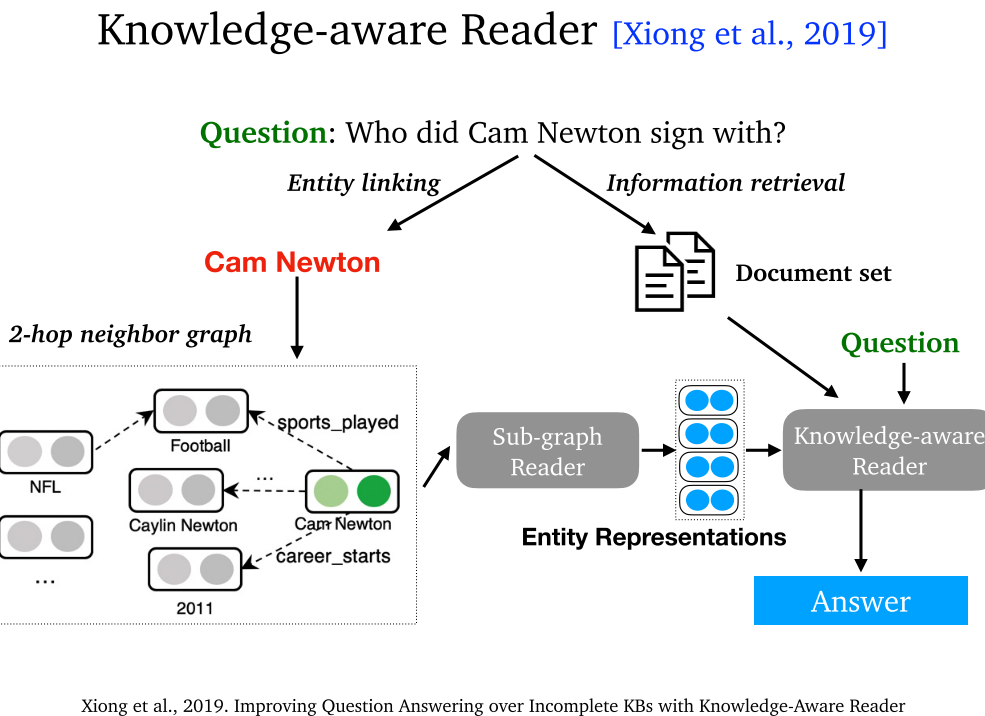
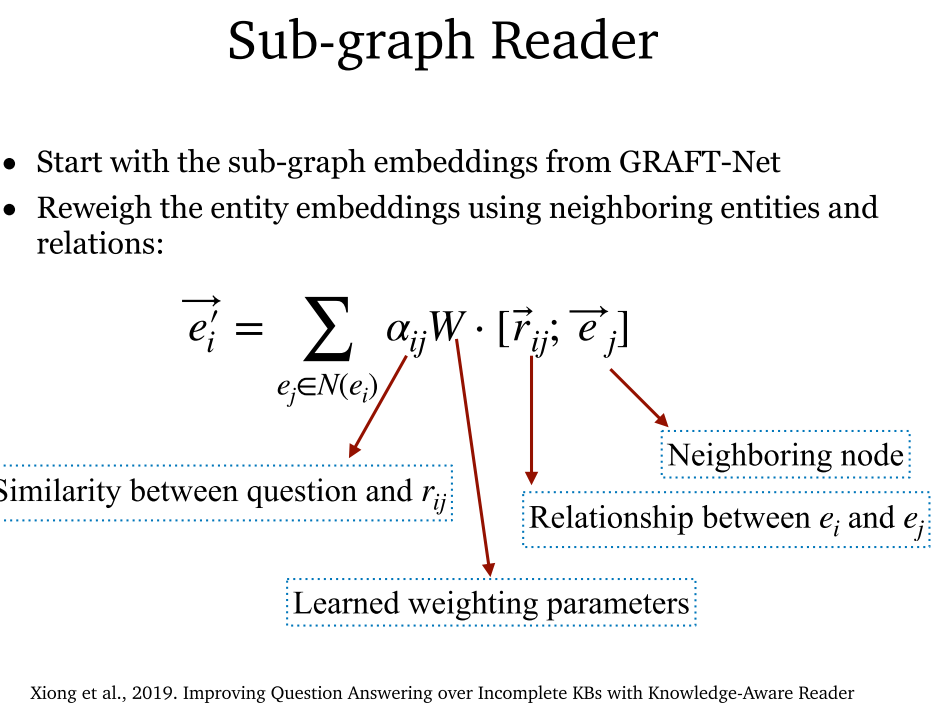
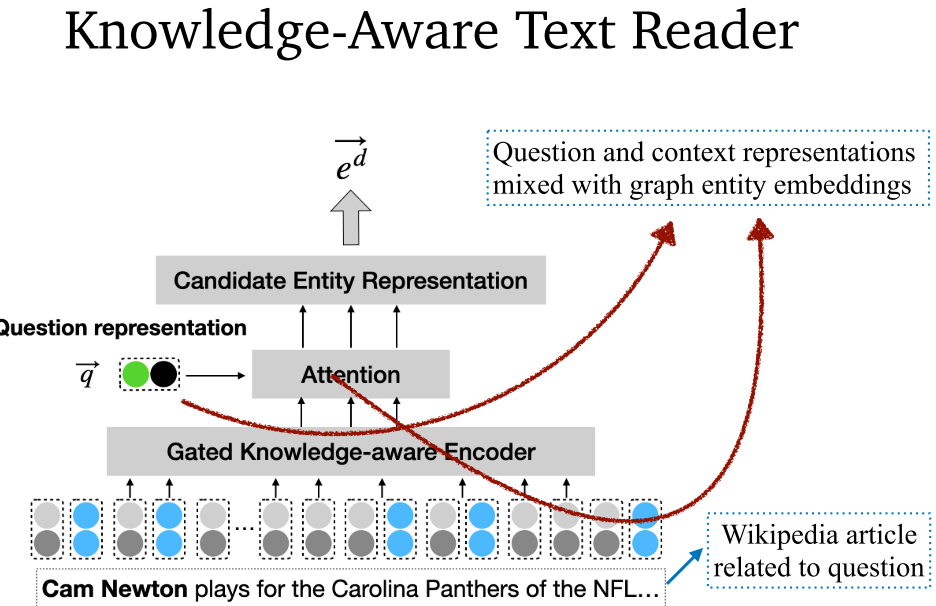
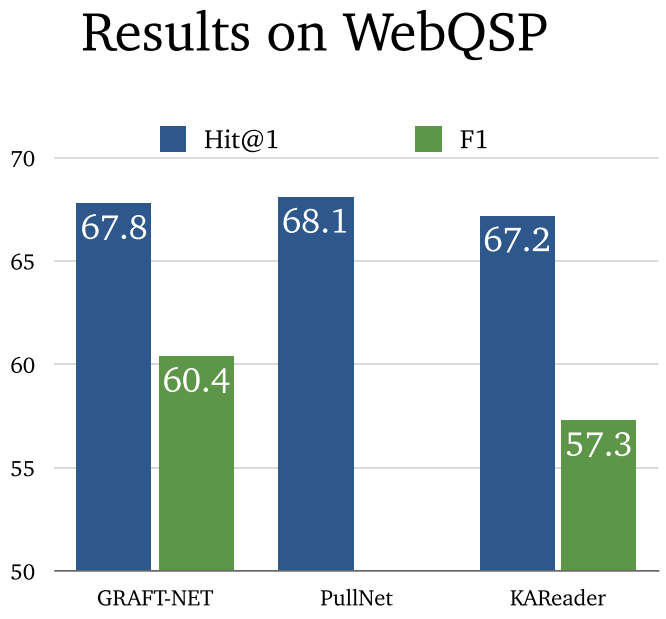
- Knowledge-aware Reader:可以解决多跳问答。首先通过 GRAFT-Net 获取子图嵌入,随后重新调整权值,综合考虑问题和关系相似度、学习参数、实体间关系类型、相邻实体。最后通过注意力机制将问题表示和上下文进行融合。
7.7 Knowledge-Guided Text Retrieval and Reading (2020)
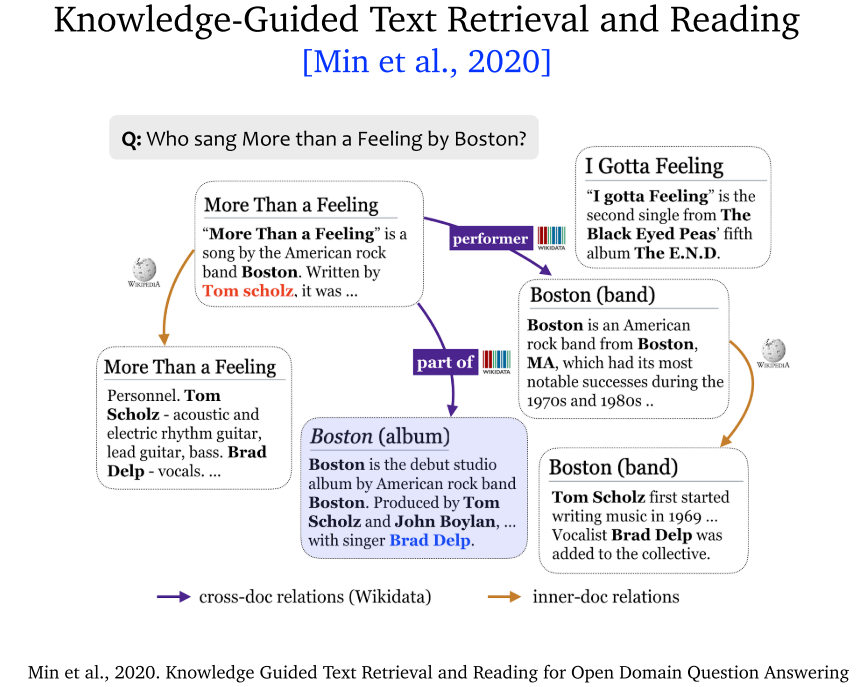
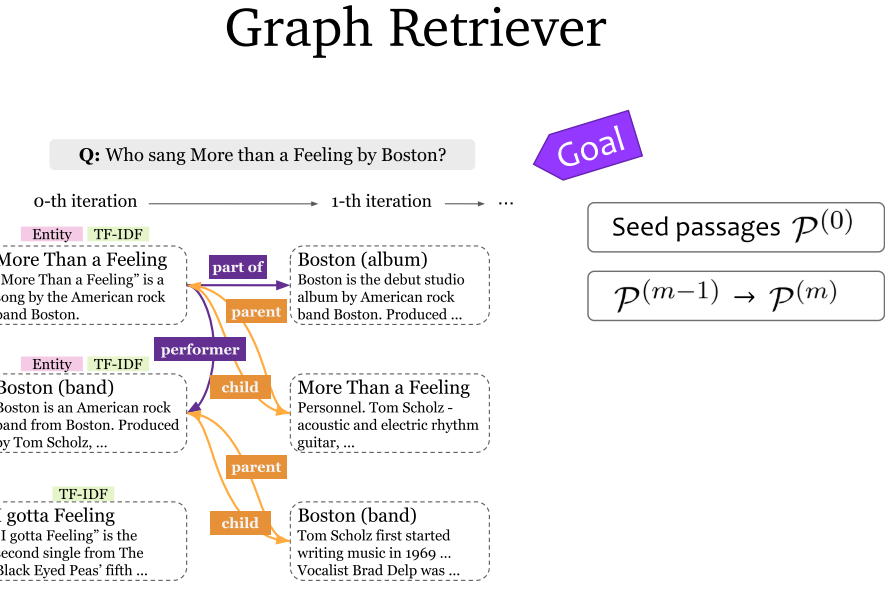
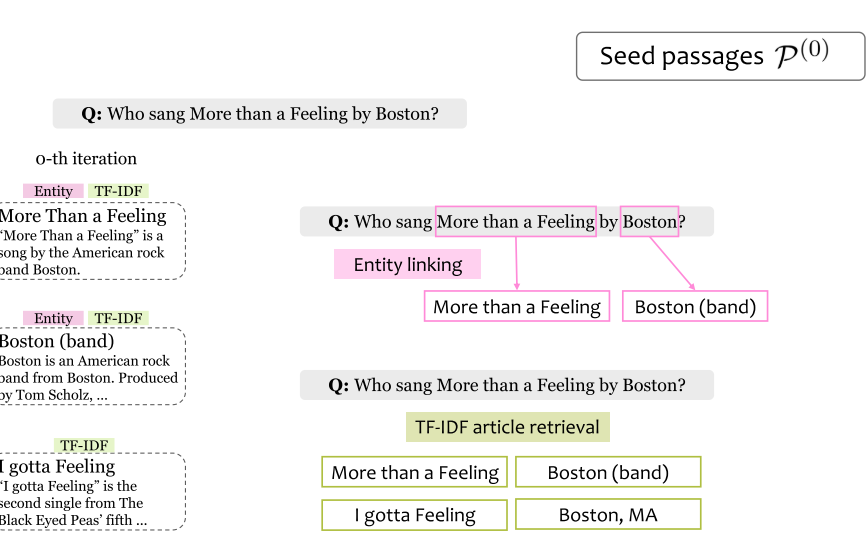
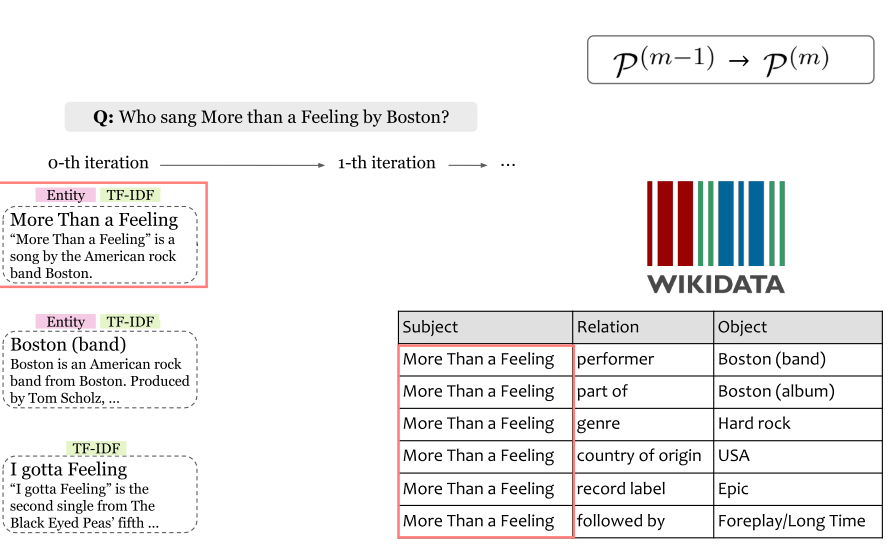
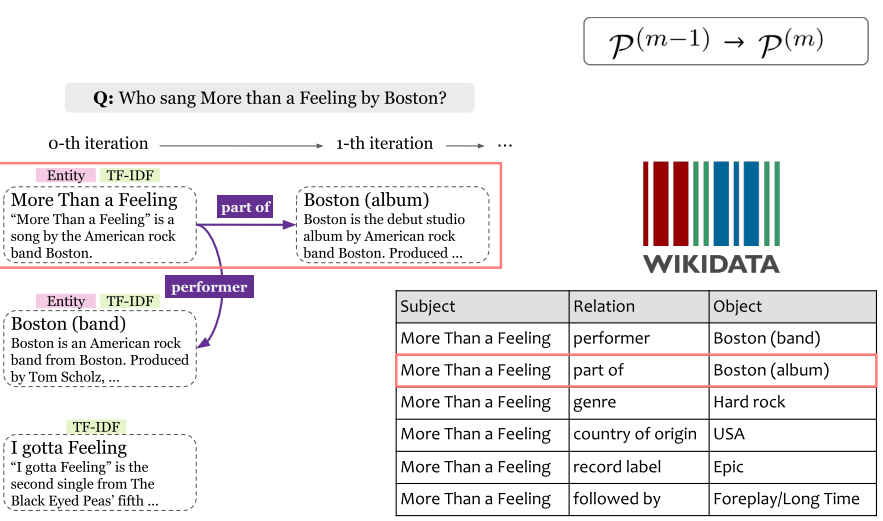
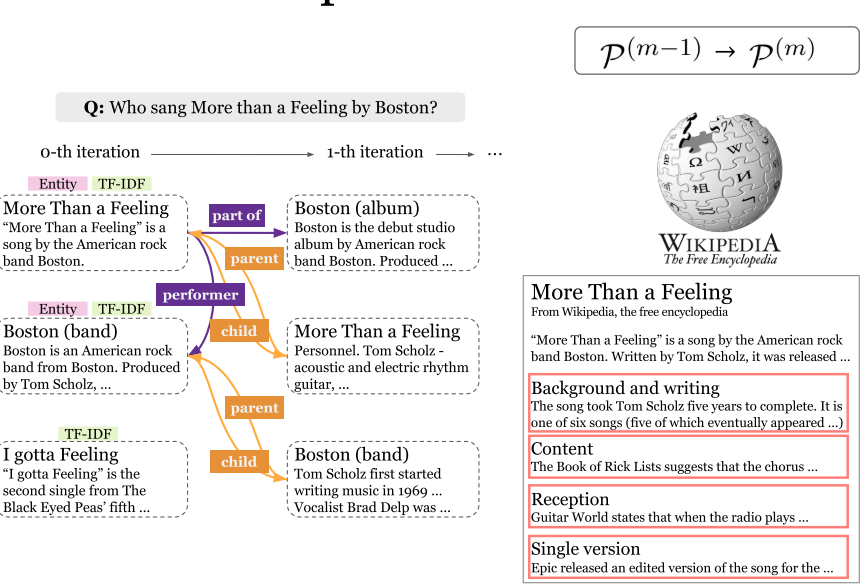
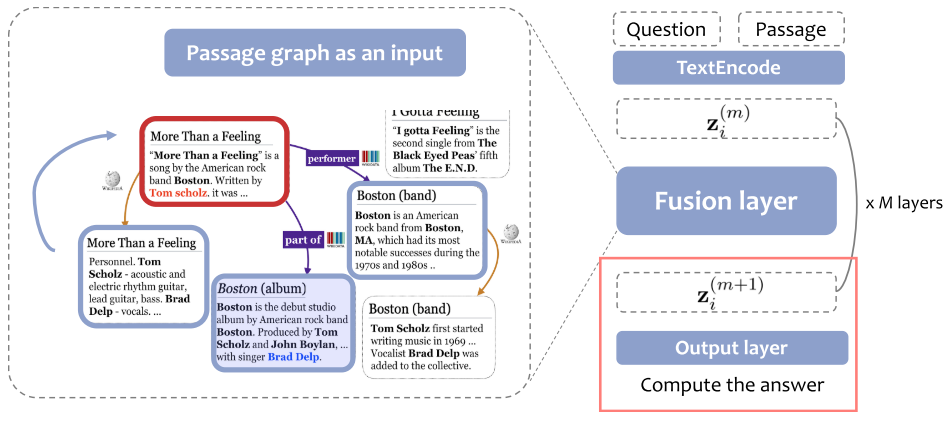
- Knowledge-Guided Text Retrieval and Reading:综合考虑跨文档关系和文档内关系。将知识图谱内容与文档内容进行融合。
7.8 总结

8. Conclusion




当前热门问题:
- 显示知识检索和知识嵌入的比较:
- 利弊。
- 大型预训练模型的影响。
- 效率和准确性。
- 完整用户体验:
- 获取支持证据。
- 答案触发机制:知之为知之,不知为不知。
- 解决叙述性问题,以及获取较长的答案。
- 用户交互和落地:
- 多轮理解性对话。
- 多模态交互。(VQA,虚拟导游等等)。
Comments | NOTHING