






今天分享的这篇论文是 NAACL 2021 的一篇论文,有关于无监督学习、问题生成的多跳问答模型。
论文地址:Unsupervised Multi-hop Question Answering by Question Generation。
论文代码:GitHub
0. Abstract
这篇文章研究的是无监督学习进行多跳问题生成,从而实现问答。文章提出了一种叫做 MGA-QG 的框架,能够从文本中或文本和表格中选择和生成相关信息,随后集成这些信息,构建多跳问答数据集(文章构建的是两跳)。只通过这些生成的数据集,就能达到 61% 和 83% 的 HybridQA 和 HotpotQA 的监督学习的效果。利用这些无监督学习数据集,能够显著降低对人类标注数据集的需求。论文也开源了相关代码。
1. Introduction
文章提出的 Multi-Hop Question Generation (MQA-QG) 框架,主要包括两步:选择相关信息,整合信息构建问题。整合信息部分定义了8种 运算符 operators,构建问题部分定义了6个 推理图 reasoning graphs。这些问题在后面章节有详细介绍。最后,文章在两个数据集 HotpotQA 和 HybridQA 上进行对比测试。
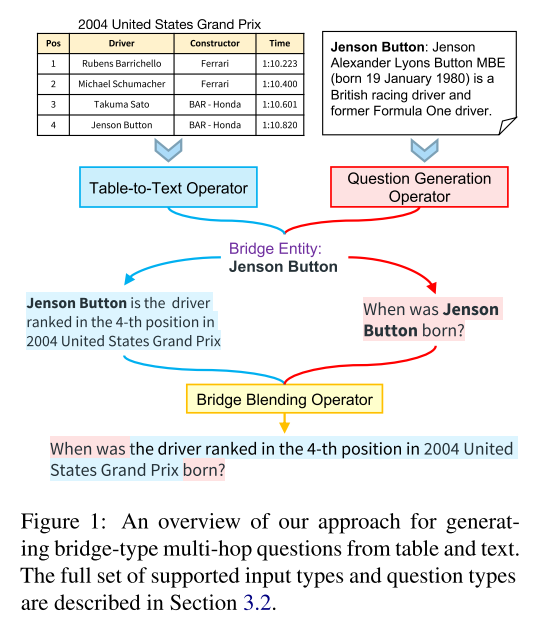
- 图1:产生 Bridge-type 多跳问题的方法概观。
2. Related Work
相关工作部分,介绍了 无监督问答 Unsupervised Question Answering 和多跳问题生成 Multi-hop Question Generation。文章是第一个提出无监督多跳问答的,也是第一个将半结构化信息(表格、知识图谱)融入到无监督多跳问答的。
3. Methodology
这篇文章主要考虑两跳问题,因此选择两个上下文 Ci, Cj 作为输入。
文章提出的方法 MQA-QG 包含三种组件:operators, reasoning graphs 和 question filtration。
operators 包含规则和现有预训练模型,功能是抽取、生成或融合相关信息。
reasoning graphs 由 operators 组合得到,用于定义不同推理链。执行 reasoning graphs 可以得到生成的多跳问题。
question filtration 可以移除不相关和不自然的问答对,获取最终问答对。
3.1 Operators
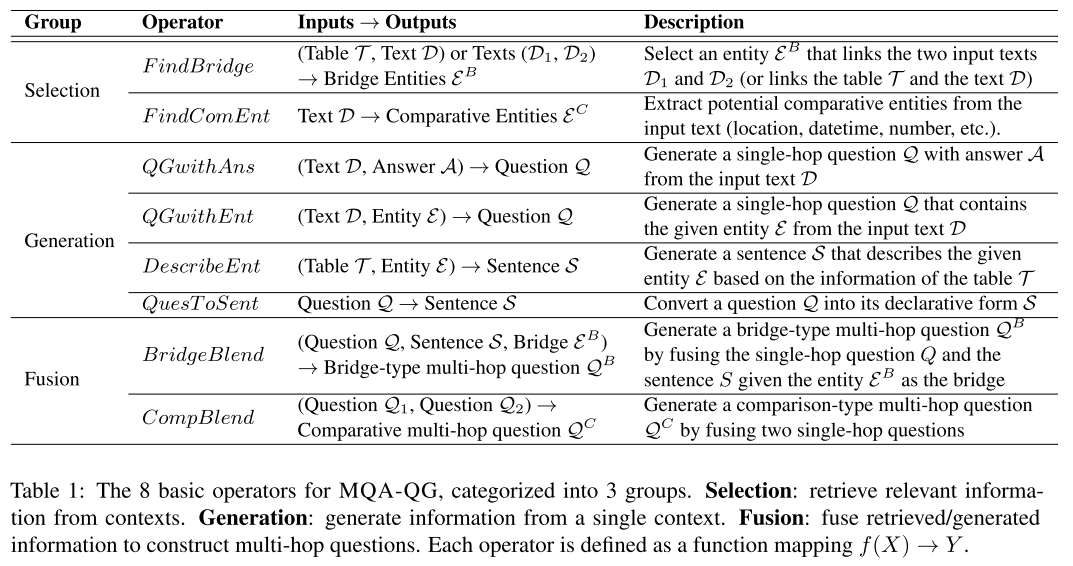
- 表1:8种基本运算符。
Selection:
- FindBridge:找到 Ci 和 Cj 中都出现的实体。
- FindComEnt:找到有可能比较的属性,采用的是实体识别中标明为
国籍、地点、时间和数量(Nationality, Location, DateTime, and Number)的属性。
Generation:
- QGwithAns:采用在 SQuAD 上训练的 Google T5 模型实现问题生成,目标是生成简单单跳问题。以 SQuAD 的一个上下文和答案作为输入,返回以给定答案为答案的一个问题。
- QGwithEnt:与 QGwithAns 类似,采用在 SQuAD 上训练的 Google T5 模型,目标是生成简单单跳问题。以上下文和一个实体作为输入,返回包含这个实体的一个问题。
- DescribeEnt:以一个表格和一个实体为输入,返回一个对该实体的描述句子。采用的是 GPT-TabGen 模型,原理是通过模板将表格展开成一段话,再用 GPT-2 生成描述句子。为了避免无关信息,采用模板仅保留包含指定实体的行。在 ToTTo 数据集(用于训练表格到文本转换的数据集)上精调了模型,最大化返回合适描述的概率。
- QuesToSent:将输入的问题转换为陈述的句子,方法是句法规则。
Fusion:
- BridgeBlend:构建一个 bridge 类型的多跳问题,输入包括:一个实体、一个包含实体的问题和一个描述实体的句子。构建过程是将问题中的实体替换成
the [MASK] that s,其中 [MASK] 采用 BERT-Large 填写一个词。 - CompBlend:构建一个比较类型的多跳问题。输入包括两个单跳问题,有同一个比较属性对应两个不同的实体,构建采用句子模板。

- 图2:DescribeEnt operator 操作过程。

- 图3:BridgeBlend operator 样例。
3.2 Reasoning Graphs
下面的图给出了6种推理图的具体内容。每个推理图都是一个有向无环图 DAG,包含了一系列 operators。执行推理图,就可以获取相应的问题。推理图的类型包括 仅文本、仅表格、文本到表格、表格到文本、文本到文本、比较。
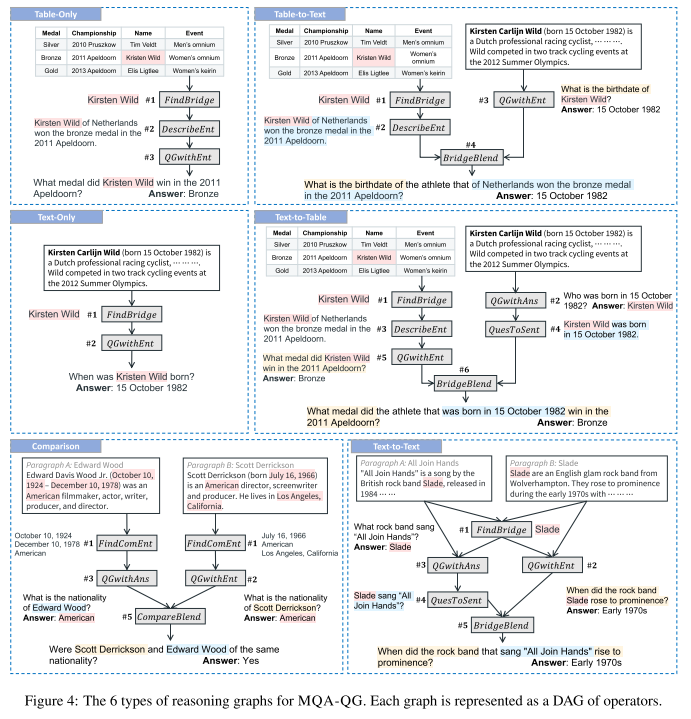
- 图4:6种推理图。
3.3 Question Filtration
最后的问题过滤部分,文章设计了两种方法,过滤 Filtration 和 改写 Paraphrasing。过滤采用 GPT-2 给出每个问题的流畅度和自然度的得分,最后用 Top N 选出 N 个合适的问题。改写采用 BART 进行问题生成,取得较好的效果,但会引入一些语义偏移的问题。
4. Experiments
文章采用两个数据集 HotpotQA 和 HybridQA 进行试验。HotpotQA 包含81%的 bridge 类型和19%的比较类型。HybridQA 包含56%的表格类型和44%的文本类型,并且80%是 bridge 类型。
4.1 Unsupervised QA Results
问题生成部分,HybridQA 生成了表格到文本数据集和文本到表格数据集,并通过过滤获取最终训练集。HotpotQA 生成了 bridge 和比较类型的数据集,并通过过滤获取最终训练集。
问答部分,HybridQA 数据集采用 SOTA 模型 HYBRIDER,HotpotQA 数据集采用 SpanBERT 模型。评价采用 Exact Match EM 和 F1。
Baselines 部分,与监督学习模型和无监督学习模型进行对比。
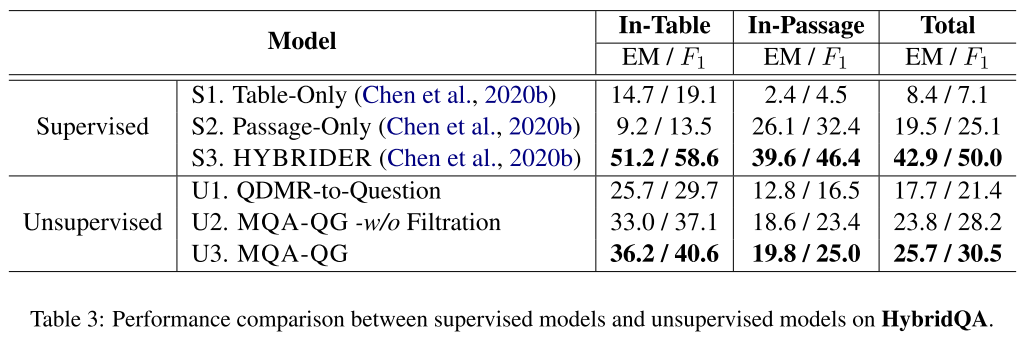
- 表3:HybridQA 模型对比。
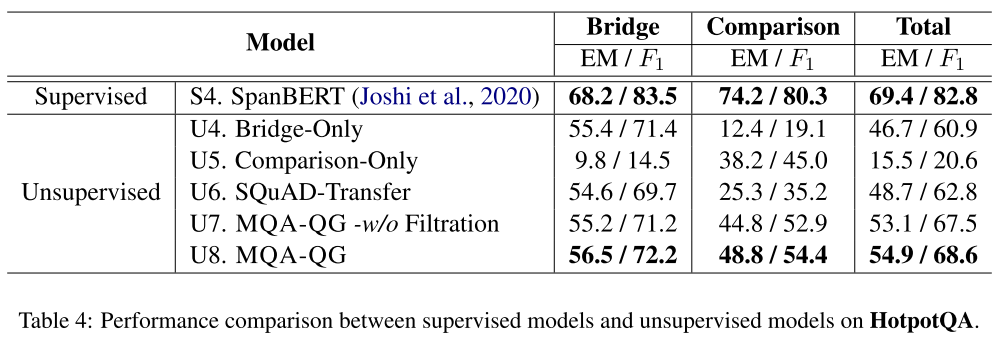
- 表4:HotpotQA 模型对比。
4.2 Ablation Study
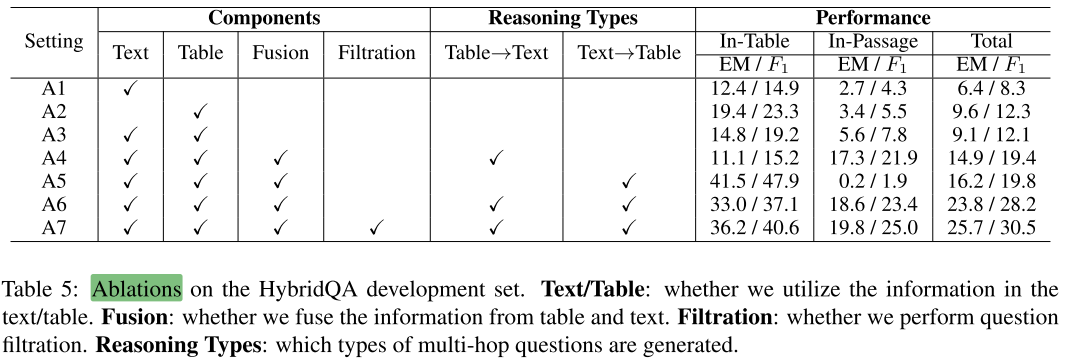
- 表5:消融实验。A1- A4 是移除了部分组件,A5-A6 是限制推理类型,A7 是完整内容。
4.3 Few-shot Multi-hop QA
文章还测试了 Few-shot 学习,使用无监督学习样本进行预训练,并用少量人类标注监督学习样本进行微调。证明了 MQA-GEN 可以用于缺少人类标注样本的领域。

- 图5:Few-shot 学习实验。蓝色线为无监督学习预训练后的效果。
4.4 Analysis of Generated Questions
文章对生成的问题进行了分析,发现缺少 "which" 问题,存在不准确问题和冗余问题。

- 表6:主要问题。包括不准确问题(红色)和冗余问题(蓝色)。
4.5 Effects of Question Paraphrasing
文章还研究了重写对结果的影响。重写采用的是 BART 模型,在 Quora Question Paraphrasing dataset 进行了精调,该数据集有超过 100k 的问题-含义对。结果证明,虽然重写后,语言更自然了,但是明显引入了一些语义偏移。经过分析,语义偏移对效果的影响比自然性还要重要。
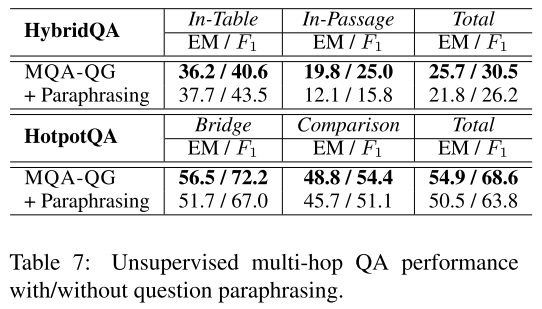
- 表7:是否采用重写对效果的影响。
5. Conclusion
文章重点研究无监督学习的多跳问答,并提出了一个 MQA-QG 框架,通过 operators, reasoning graphs 和 filtration 生成多种类型的多跳问题,可以在无监督领域和 few-shot 学习领域为问答模型提供良好的支持。后续的工作需要继续研究如何重写问题,以及如何将问题生成扩展到更复杂的问题。
个人认为,这篇文章写的也相当不错,介绍部分非常准确易懂,实验分析也很清晰明了,值得借鉴学习。自动阅读理解是很重要的研究方向,值得深入探索。
Comments | 2 条评论
博客写得很棒!非常清楚,谢谢!
@iven 感谢支持~