





论文地址:Dense Passage Retrieval for Open-Domain Question Answering
EMNLP 2020 Open Domain QA 领域论文,也是陈丹琦推荐的论文。
0. Abstract
段落检索是 Open Domain QA 领域的重要问题。传统方法采用稀疏向量空间模型,如 TF-IDF 和 BM25。本文重点研究段落检索的密集向量空间模型,也就是进行密集表示。同时,密集表示的学习采用了简单的双层编码器框架,同时采用了非常少量的问题和段落对。
后面实验部分可以看到,密集检索器可以在 top20 任务上超过此前的 sota 模型 9-19%,实现了密集表示对稀疏表示的降维打击。
1. Introduction
开放领域问答的一个重要方法:检索器 + 阅读器模型。其中,检索器负责从海量文档中检索相关段落。阅读器负责实现一个 mrc 任务,从段落中提取答案,例如 SQuAD 任务。
此前采用的检索器,通常是稀疏向量检索器,采用 TF-IDF 或 BM25,通过词频和逆文档频率,有效匹配问题和上下文。但是,这种检索器无法获取语义信息,而只能进行关键词匹配。例如,针对句子:
-
Who is the bad guy in lord ofthe rings -
Sala Baker is best known for portraying the villain Sauron in the Lord ofthe Rings trilogy.
传统的稀疏向量检索器无法很好地匹配 bad guy 和 villain 的语义关系。而密集向量检索器经过语义训练,因此可以更好地捕获语义信息,能匹配 `bad guy 和 villain。
一般认为,密集向量检索器需要大量标记的问题和文本对进行培训,以 ORQA 为代表,采用复杂的反向完形填空任务 ICT 进行额外的预训练,随后用问答对进行问题编码器和阅读器的微调。
本文的重点就是,研究能否仅仅使用成对的问题和段落(或答案),而不进行其他预训练,训练更好的密集嵌入模型。通过结合 BERT 预训练模型和双编码器结构,仅仅使用了较少的问答对就实现了非常大的检索效果提升,从而证明了不需要额外的预训练就能提高检索效果。随后证明了检索精度提升有助于提高后续阅读器的效果。
2. Background
表示方法:
- D:文档集合。
- C:段落集合。
- W:跨度。
- q:问题。
3. Dense Passage Retriever (DPR)
3.1 Overview
本文的研究重点是检索器,提出了密集段落检索器 DPR 模型,在 M 个文档中找到 top-k 个相关段落。DPR 采用了多种编码器 EQ,将输入段落映射到 d 维向量,并匹配与问题最接近的 k 个段落。
编码部分,测试了多种编码器模型,最后采用的问题和段落的编码器是两个 BERT,[CLS] 作为输出。
问题和段落的相似性度量部分,测试了多种计算方式(点积、余弦相似性和 L2 距离),最后选择了精度较高且计算简单的点积。
最后的推断部分,将段落编码器应用于所有段落,并使用开源库 FAISS 进行问题相关段落的检索。DPR 将输入模型应用问题编码器进行嵌入表示,随后用 FAISS 找到 top-k 个最相关段落。
3.2 Training
训练部分:
- 训练数据:问题,一个正例段落,n 个负例段落。后面会介绍这种训练方法的高效之处。

- 目标函数:负对数似然估计。
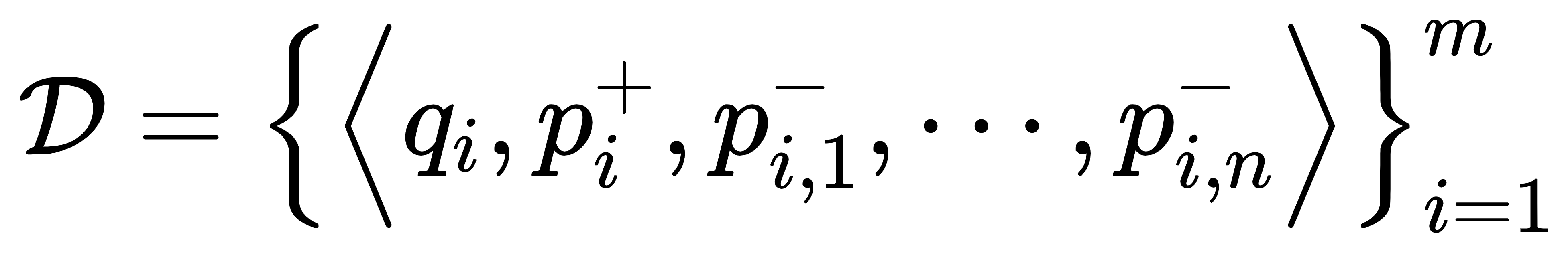
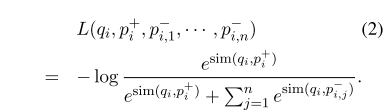
负例选择:
-
由于负例有 n 个,默认情况下虽然可以认为怎么选择都可以,但可能对训练高质量的检索器有非常大的影响。本文研究了三种负例选择方法:
-
随机选择段落。
-
BM25 获取的 top-n 段落,去除正确答案。
-
其他问题对应的正确段落。
-
最后,经过试验证明,采用 n 大小批次训练,采用 n-1 个其他问题对应的正确段落和 1 个 BM25 获取的 top-1 段落进行组合,结果兼具时间复杂度低和精度高的特点。
批内负例方法:
- 设置每个批次都有 B 个问题,每个问题有对应段落。构建 B*B 矩阵,则 i != j 时对应的是负例,i == j 时对应的是正例。
- 这种方法是学习双编码器模型的有效策略,能够极大提高训练实例的数量。
- 这也是为什么采用 1 个正例、n 个负例的原因。
4. Experimental Setup
4.1 Wikipedia Data Preprocessing
本文采用的是维基百科数据。首先使用 DrQA 代码中的预处理部分,将维基百科信息转换为纯文本段落。转换过程将半结构化数据(表格、信息框、列表、消歧页面)都删掉,并将文本转换为 100 字的段落,并在段落后加上段落来源的维基百科标题,以及一个 [SEP]。
4.2 Question Answering Datasets
问答数据集采用了五种:
NaturalQuestion (NQ):端到端问答。TriviaQA:琐事问答。WebQuestion (WQ):谷歌问答。答案是 Freebase 实体。CuratedTREC (TREC):非结构开放问答。SQuAD v1.1:机器阅读理解任务问答(因为是原段落答案跨度检索问答,所以跟上面的都不太一样。不过也拿过来进行一个对比)。
正例段落选择:
- 由于
TREC、WebQuestions、TriviaQA没有给出正例段落,因此采用BM25获取 top-100 段落中排名最靠前的含答案的段落作为正例段落。如果 top-100 都不含答案,就丢弃问答对。 - 由于
NaturalQuestion和SQuAD v1.1的正例段落和维基百科的不匹配,因此将正例段落替换为维基百科中的相应段落(原文没有写怎么找相应段落,应该也是BM25top-100 含答案段落)。如果无法替换则丢弃问答对。
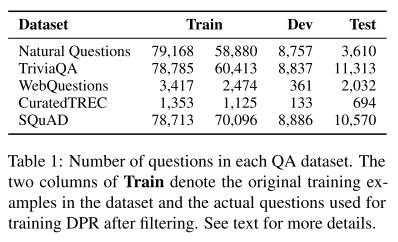
- 表1:处理后的可用于本模型的数据集。
5. Experiments: Passage Retrieval
训练过程,采用前文提到的批内负例方法进行训练。批大小设置为 128,每个问题额外增加一个前文提到的 BM25 负例。为大数据集 NQ、TrivalQA、SQuAD v1.1 训练 40 个 epoch,小数据集 TREC、WQ 训练 100 个 epoch。Adam 学习率 10^-5,warm-up 和 dropout 设为 0.1。
同时,除了研究单个数据集效果良好的检索器,本文还研究了在各个数据集都工作良好的检索器。这个方向研究了除了 SQuAD 的其他数据集进行训练,标注为 Multi 与 Single 相对应。
除了 DPR,还将 BM25 和 BM25 + DPR (线性组合)作为参考。
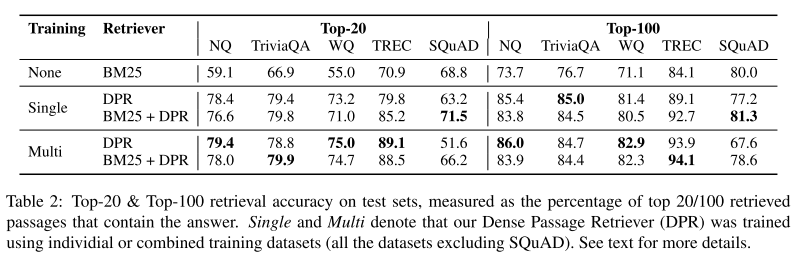
- 表2:检索器 top-20 和 top-100 检索精度。
Multi一般效果更好。在SQuAD上表现不好,因为SQuAD是原段落跨度答案检索问答,段落和问题的词汇重叠太多,BM25能够取得很好的效果。
消融实验:
- 样本效率。研究需要多少样本实现更好的检索效果。 实验证明 1k 已经能实现更好效果。
- 批内负例效果。和前文介绍的其他负例生成方法进行对比,证实了批内负例的效果。
- 正例段落影响。将原始正例替换为
BM25正例,结果只下降了 1,证明BM25就可以获取足够好的正例。 - 相似度选择。相似度进行了点积、余弦和 L2 相似度,结果证明 L2 和点积效果相当,都比余弦相似度好。
- 损失函数选择。损失函数比较了排序常用的三联体损失和负对数似然估计,结果差不多。
- 跨数据集泛化。在一个数据集上训练,在其他数据集上实验,结果仍然优于
BM25。
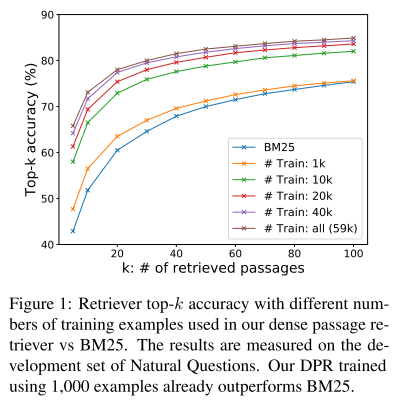
- 图1:检索器 top-k 检索精度。在训练量达到 1k 时,
DPR效果就胜过BM25了。
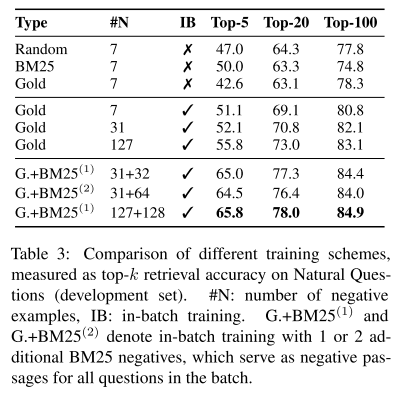
- 表3:消融实验。
DPR 和 BM25 性能分析:
DPR和BM25没有优劣之分。前者更适合处理词汇不同、语义方面的问题,后者更适合术语、关键词、短语匹配。
运行效率:
-
构建
FAISS索引:8.5 h。 -
构建
Lucene索引:30 min。 -
DPR效率:基于FAISS处理 top-10 可以极大提高DPR效率,每秒 995 个问题,每个问题返回 100 个相关段落。也可以采用Lucene索引。 -
BM25效率:每秒 23.7 个问题。
6. Experiments: Question Answering
本文构建了一个端到端问答系统,它的检索器部分可以直接换用不同检索器。检索器将相关段落传输给阅读器。阅读器从每个段落提取一个答案跨度,并分配跨度得分,最后选择得分最高的跨度作为答案。
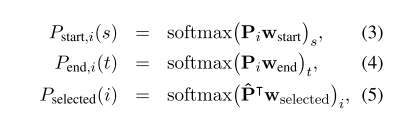
- 公式3-5:计算跨度。P:表示向量,w:权重
训练数据集中,每一批有一个正例,其他为负例。对大数据集,设置每一批为 16。对小数据集,设置每一批为 4。实验是在 8 个 32 GB GPU 上进行。
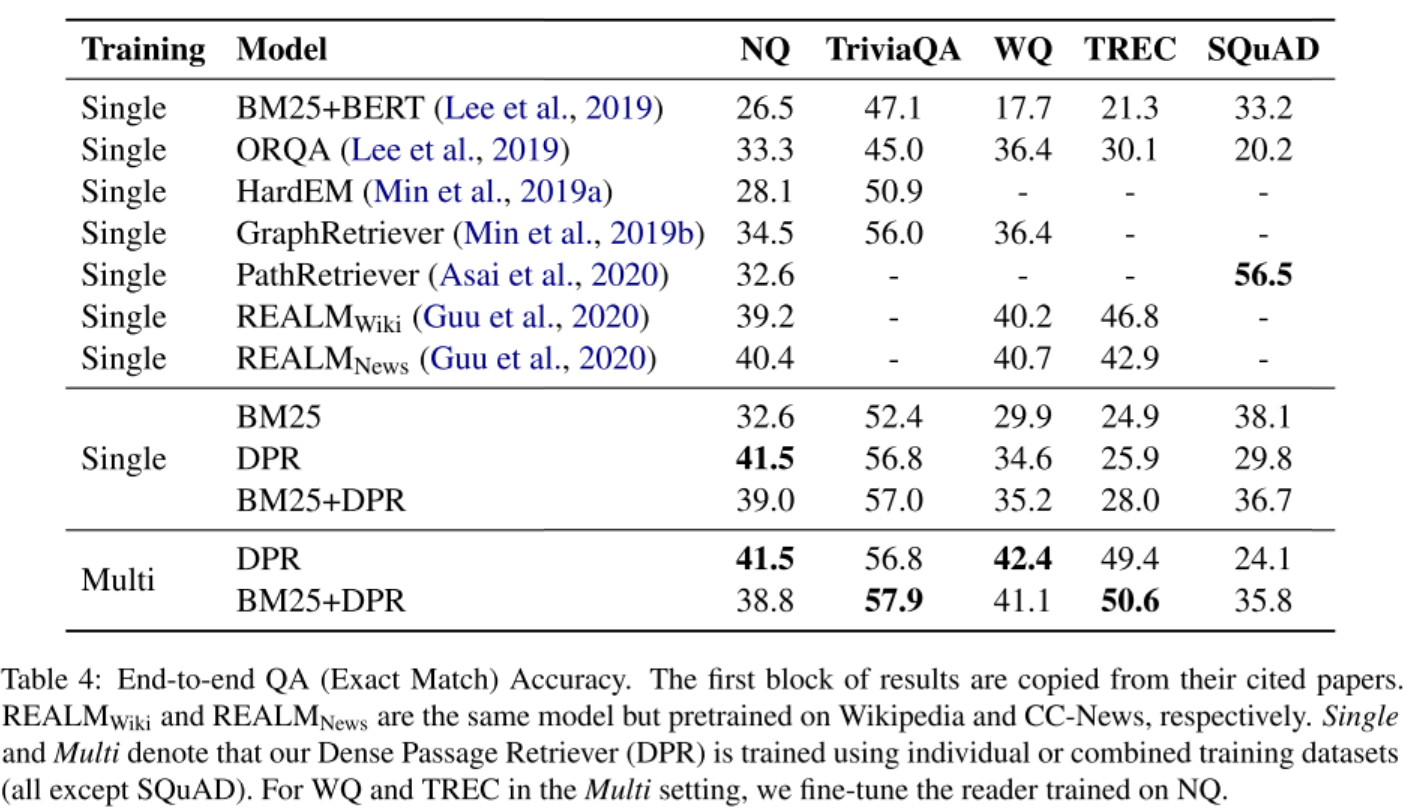
- 表4: QA 准确度。结果来看,在多个数据集上的效果更好。
同时,本文还对比了联合训练方法和管道训练方法,结果联合训练方法在 NQ 数据集上取得了39.8 的精度,比管道方法低,这也说明了孤立训练检索器和阅读器能取得更好的效果。
7. Related Work
段落检索是开放领域问答的重要组成部分。
密集向量表示研究很早就出现了。
ORQA 是密集向量表示应用在段落检索的开创性研究内容,也是本文的对比。本文证明了不需要进行复杂的预训练,只使用问答对就可以提高检索效果。
8. Conclusion
本文研究表明,密集检索可以胜过传统稀疏检索组件,尤其是在需要语义信息的领域。
Comments | NOTHING