





论文:HopRetriever: Retrieve Hops over Wikipedia to Answer Complex Questions
0. Abstract
从大型文本语料库收集分散的证据片段支撑答案提取是一个巨大挑战。这篇文章提出的方法是将跃点定义为超链接和出站链接文章的组合:
- 超链接被编码为
提及嵌入,表示出站链接实体如何在上下文文本中被提及的结构化知识。 - 出站链接文档被编码为
文档嵌入,表示其中的非结构化知识。
通过 HotpotQA 数据集,证明了效果很好。
1. Introduction
多跳问答需要从多个支持文档中搜集分散的证据,提取最终答案。最近的方法主流是将多跳证据收集视为迭代文档检索问题。
- 分解为单步文档检索。
- 关注其中实体,遍历实体数据,如知识库。
作者认为这体现了两种思想:
- 关注结构性知识。
- 关注非结构性知识。
因此,文章将跃点定义为超链接和出站链接文档,分别包含结构性知识和非结构性知识,从而包含关系证据和事实证据,可以进一步进行迭代检索。
通过分布式关系学习(采用 BERT 模型)获取实体间关系的分布式表示。将当前实体作为主题实体,出站链接实体作为提及对象实体,学习实体间关系。
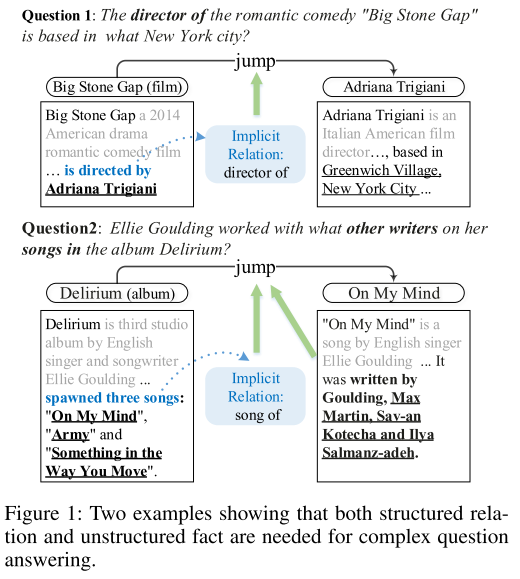
- 图1:结构性知识和非结构性知识。结构性知识指的是提及关系。非结构性知识指的是知识库之类外来知识。
2. Related Works
文件推理。
以实体为中心的推理。
问题分解。
3. Method
3.1 Overview
需要构建一个检索器模型,用于在大规模知识源上收集证据片段。
需要构建一个答案提取模型,获取答案。
为了结合结构化知识和非结构化知识,实现跃点迭代检索,对两种知识分别进行编码,再进行融合,作为一个跃点。随后对编码的跃点进行迭代检索。

- 图:检索器模型和答案提取模型。
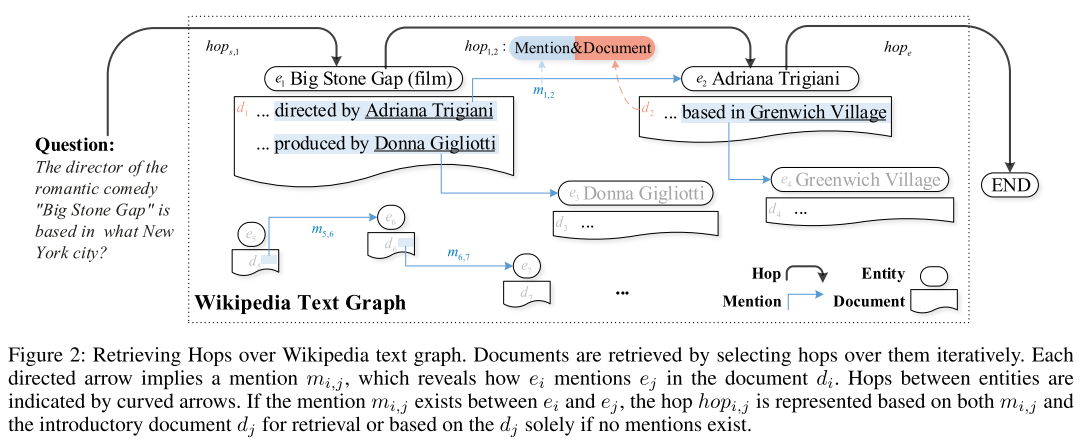
- 图2:迭代检索跃点。利用了两种知识。
3.2 Hop Encoding
结构性知识,采用提及嵌入。
非结构性知识,采用上下文嵌入。
跃点,采用知识融合获取嵌入。
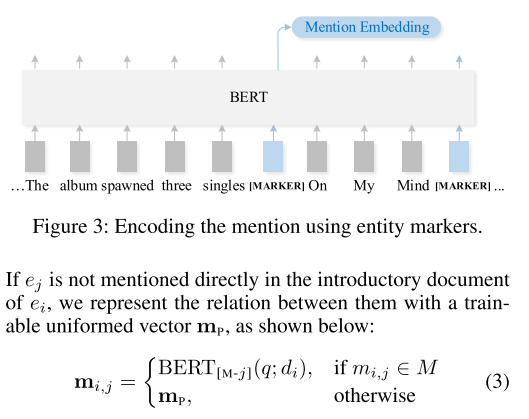
- 图3:结构性知识采用提及嵌入。在提及实体前后加入 [MARKER] 进行标注,与问题连接,输入 BERT 模型,将第一个 [MARKER] 对应向量作为嵌入向量。如果没有提及,则采用统一的向量 mp。

- 图:非结构性知识采用上下文嵌入。将出站链接文档与问题连接,输入 BERT 模型,将 [CLS] 对应向量作为嵌入向量。
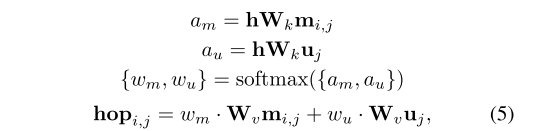
- 图:跃点嵌入为两种知识嵌入的加权融合。采用注意力机制,并通过 softmax 激活函数获取权重,进而实现知识融合,获取跃点嵌入。
3.3 Iterative Retireval of Hops
迭代跃点部分,将跃点嵌入与 RNN 模型进行融合,获取实体。
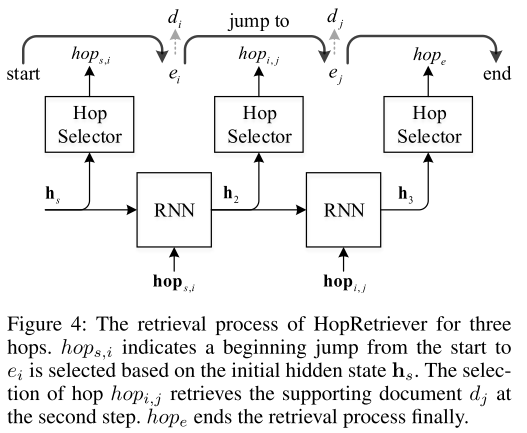
- 图4:迭代跃点。跃点选择是通过跃点嵌入和 RNN 隐藏状态向量决定。
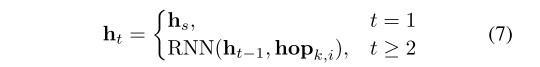
- 图:RNN 模型隐藏状态向量。

- 表1:跃点编码类型。
3.4 Fine-Grained Sentence-Level Retieval
支持句子检索需要从支持文件中找到证据。
支持句子检索与迭代跃点一起进行。利用迭代跃点的 RNN 模型的隐藏状态嵌入进行计算。
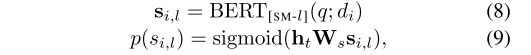
- 图:支持句子检索。si,l 的计算和提及嵌入的计算方法一致。随后结合 RNN 隐藏状态嵌入,通过 sigmoid 转化为 0-1 的概率。当 p > 0.5 时,认为句子是支持句子。
3.5 Objective Functions of HopRetriever

- 图:目标函数。采用交叉熵损失函数。
4. Experiments
4.1 Setup
数据集采用 HotpotQA 数据集。90564 个问答对。主要关注 fullwiki 部分。支持文档分散在 5M 的维基百科中。
实验包括三个部分:
- 初步检索。基于 TF-IDF 选取前 500 个文档,作为初始文档。
- 支持文档检索和支持句子预测。迭代检索初始文档。
- 答案提取。通过 BERT 获取答案。
作者还采用了一种基于 BERT 的神经排序器,获取更精确的前 500 个文档。同时,使用 ELECTRA 代替 BERT 进行答案获取。结果作为 HopRetriever-plus。这也体现了更好的初步检索的重要性。
4.2 Results
基线模型包括三种:
- Cognitive Graph QA。节点表示由图神经网络 GNN 实现。关注结构化知识。
- Semantic Retrieval。关注非结构化知识。
- PathRetriever。关注非结构化知识。

- 表2:证据收集结果。
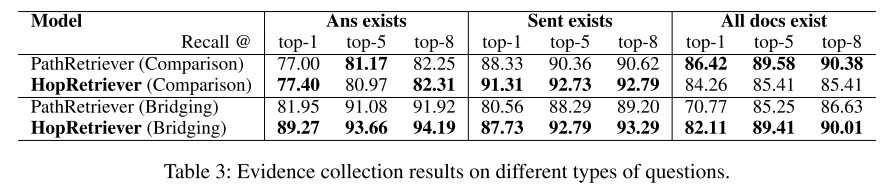
- 表3:比较问题和桥接问题结果。比较问题上支持文件可能不相关,因此两种模型效果差不多。桥接问题上 HopRetriever 则能够更好利用结构性知识(提及),实现更好效果。
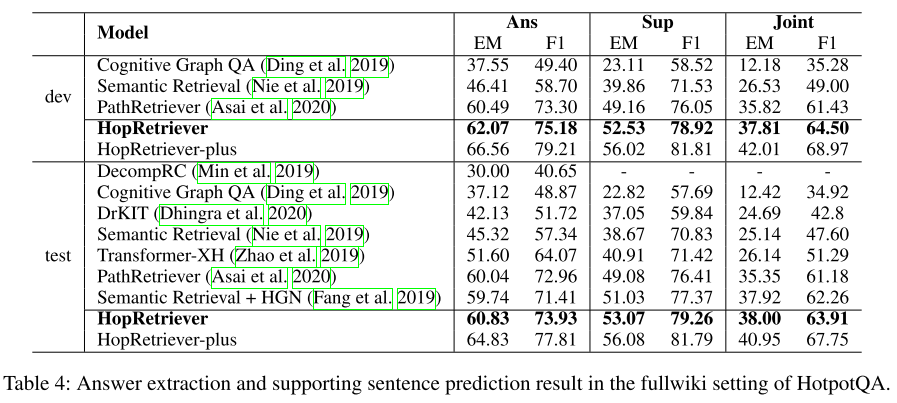
- 表4:答案提取和支持句子预测结果。
4.3 Analysis
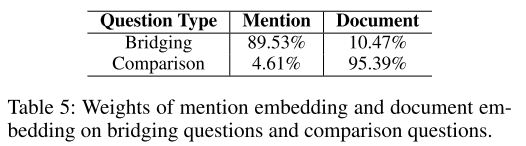
- 表5:桥接和比较问题的结构性知识和非结构性知识的权重。

- 图5:不同问题的结构性知识和非结构性知识的权重。
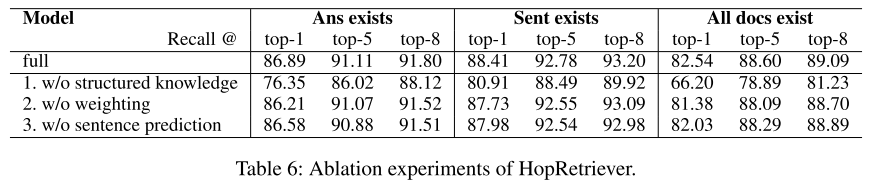
- 表6:消融实验。结构性知识的重要性。

- 表7:结构性知识的效果。结构性知识不但要能检测到
提及,还要确定这是证据相关的提及,而不是仅仅关注提及。实验证明模型能够确定证据相关的提及。
5. Conclusion
HopRetriever 能够将结构性知识和非结构性知识进行结合,确定比较好的跃点。同时,跃点迭代模型能够一步步寻找下一个跃点,最终确定答案实体。除此之外,初步文档检索也是十分重要的内容,文章采用的神经排序器效果不错,值得后面继续研究。
Comments | NOTHING