





近期 EMNLP 的论文也是放榜了。实验室的小伙伴们上周分享了不少论文,我从中选择了一些与我研究方向比较相关的论文,进行了整理。
TimeTraveler: Reinforcement Learning for Temporal Knowledge Graph Forecasting —— 论文阅读笔记
这篇文章是 EMNLP 2021 年的文章,主要采用了强化学习框架实现时序知识图谱(Temporal Knowledge Graph)的预测。
论文:TimeTraveler: Reinforcement Learning for Temporal Knowledge Graph Forecasting
代码:TITer
0. 摘要
时序知识图谱 TKG 逐渐受到关注,本文研究基于 TKG 的预测问题,并遇到两个挑战:如何有效对时间信息建模、如何预测 unseen 实体。
本文定义了一个相对时间编码函数来捕获时间跨度信息,设计了基于 Dirichlet(狄利克雷)分布的时间奖励,提出了一种预测 unseen 实体的实体表示方法。
实验是在四个数据集上开展的。
1. 方法
1.1 问题定义
查询为 (es, r, eo, t),其中 t 是三元组对应的时间。每个节点是 (ei, t),也就是都对应一个时间。查询被定义为 (eq, rq, ?, tq) 或者 (?, rq, eq, tq),则已知事实是 ti < tq 的所有三元组的集合。
1.2 强化学习框架
首先增加了三种边,反向边、自循环边和时序边,其中时序边是后面发生的事推演到前面的事,也就是 (es, r, eo, ti),其中 ti < tj 且 (es, r, eo) 存在。这样有助于从历史知识中找到答案。
状态空间:(el, tl, eq, tq, rq),其中 el 和 tl 是当前的节点,后面三个是查询的内容。
动作空间:要求动作对应的 t 必须小于 tl 和 tq。
动作转移
奖励:存在稀疏性,所以考虑引入时间分布这一先验知识来帮助调整奖励,用时间分布来帮助 agent 找到答案。各种关系对应的时间分布在这里用了 Dirichlet 分布。

策略网络:
为了生成未知实体的表示,设置了一个时间变量函数。
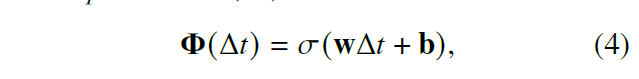
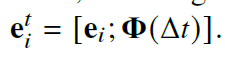
采用随机梯度下降优化策略网络。
对历史路径的编码采用了 LSTM 模型。
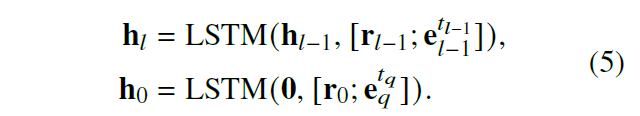
采用了两个多层感知机来预测动作的实体和关系,并通过计算动作和最终答案的相似度进行动作打分。
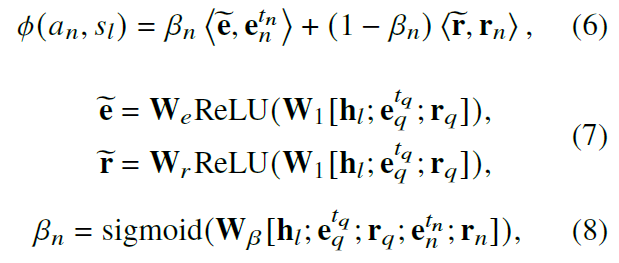
1.3 实体的 IM 表示
针对新实体和普通实体,文章设计了一种 Inductive Mean Representation 感应平均值表示的方法,具体计算方法如下所示。新实体采用公式 11 的平均实体值来代替。对于所有实体,都可以采用公式 12 的方法进行更新(但是为什么要更新这么多实体,是否会造成计算复杂度增加,这里存疑)。对于答案实体可以采用公式 13 的方法进行更新(同样存疑)。
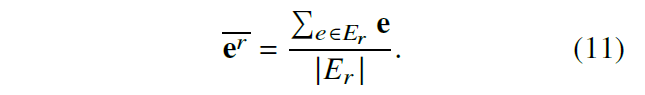
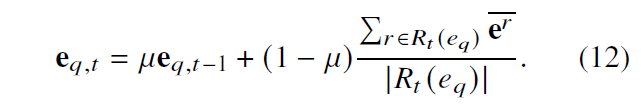
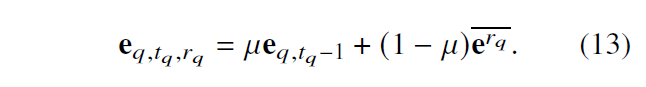
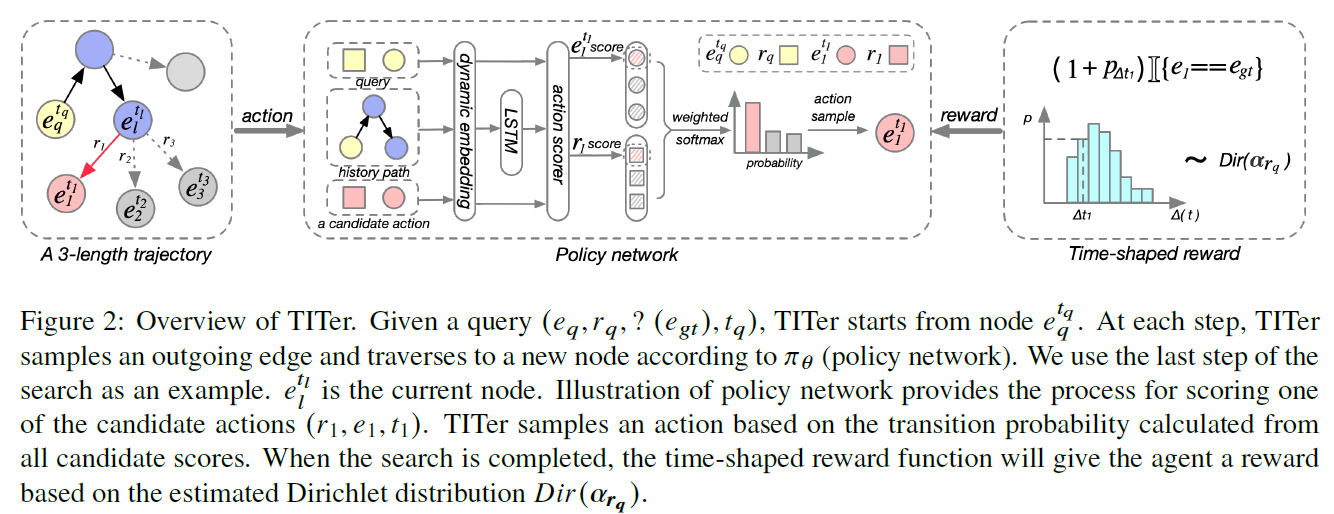
模型整体图:
2. 实验
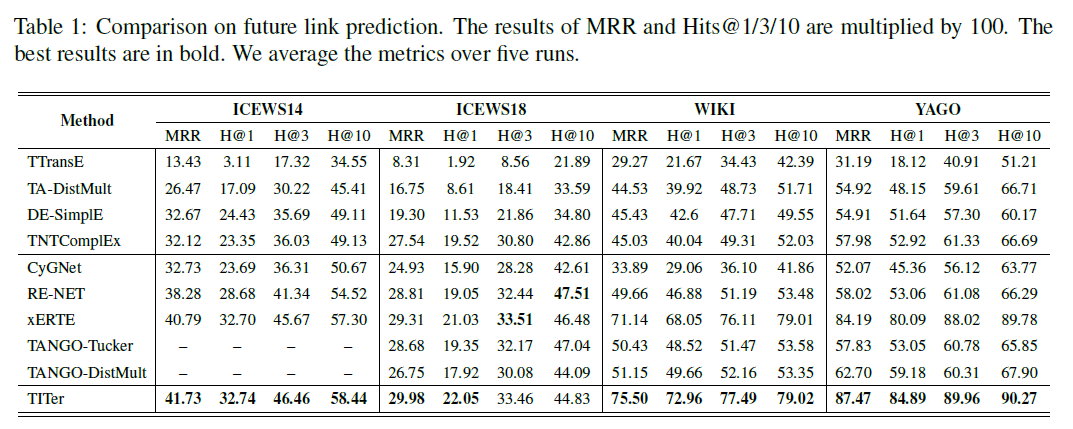
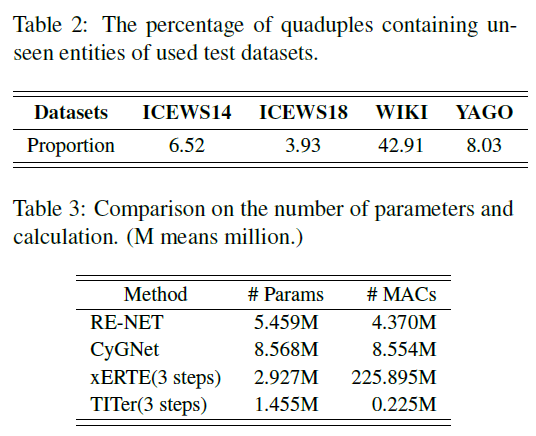
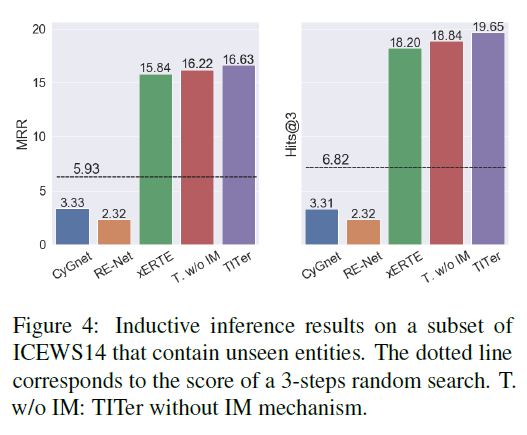
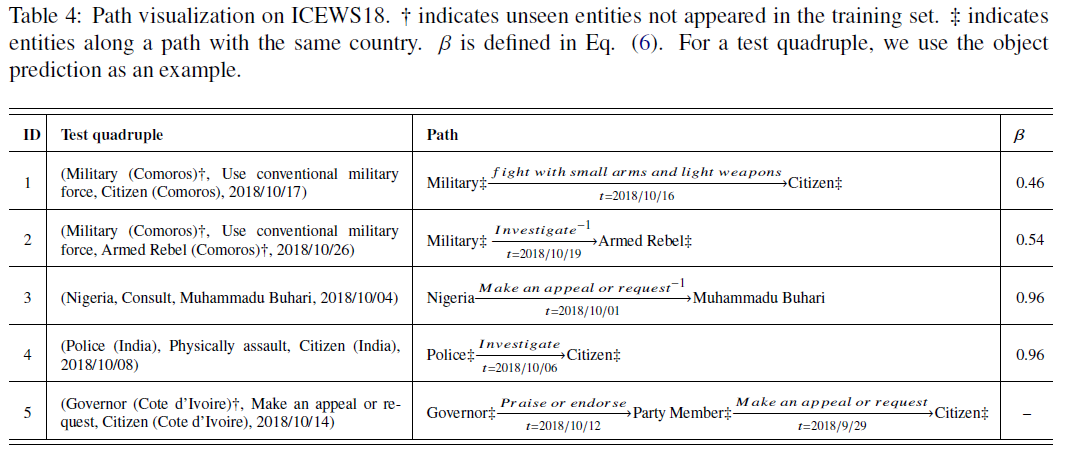
实验数据集:ICEWS14, ICEWS18, WIKI, YAGO。
实验内容:实验做得很多,包括链接预测、参数数量比较、包含未知实体的链接预测、路径可视化、消融实验和 IM 表达方法效果。
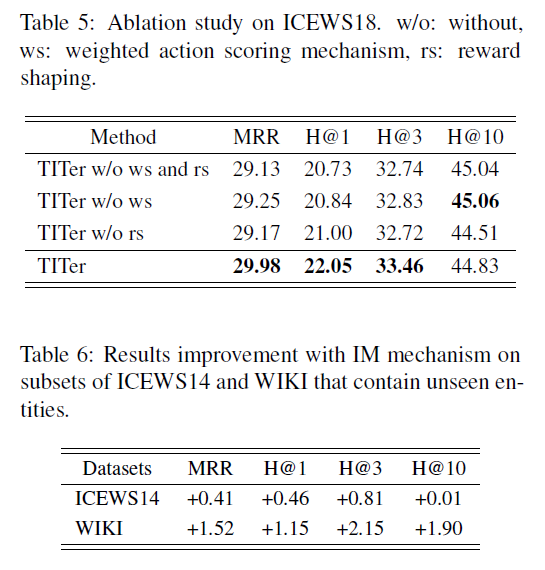
3. 思考
实验值得学习。
FewshotQA: A simple framework for few-shot learning of question answering tasks using pre-trained text-to-text models —— 论文阅读笔记
EMNLP 2021,主要研究小样本问答,比较有趣。
代码:无
0. 摘要
对于小样本情况(低于100样本数),现有方法表现很差。本文主要是将输入(问题,答案跨度和上下文)中的答案跨度进行部分遮掩,随后就可以用和训练预训练模型一样的方法进行微调。实验结果证明小样本情况下,该框架效果很好。
1. 方法
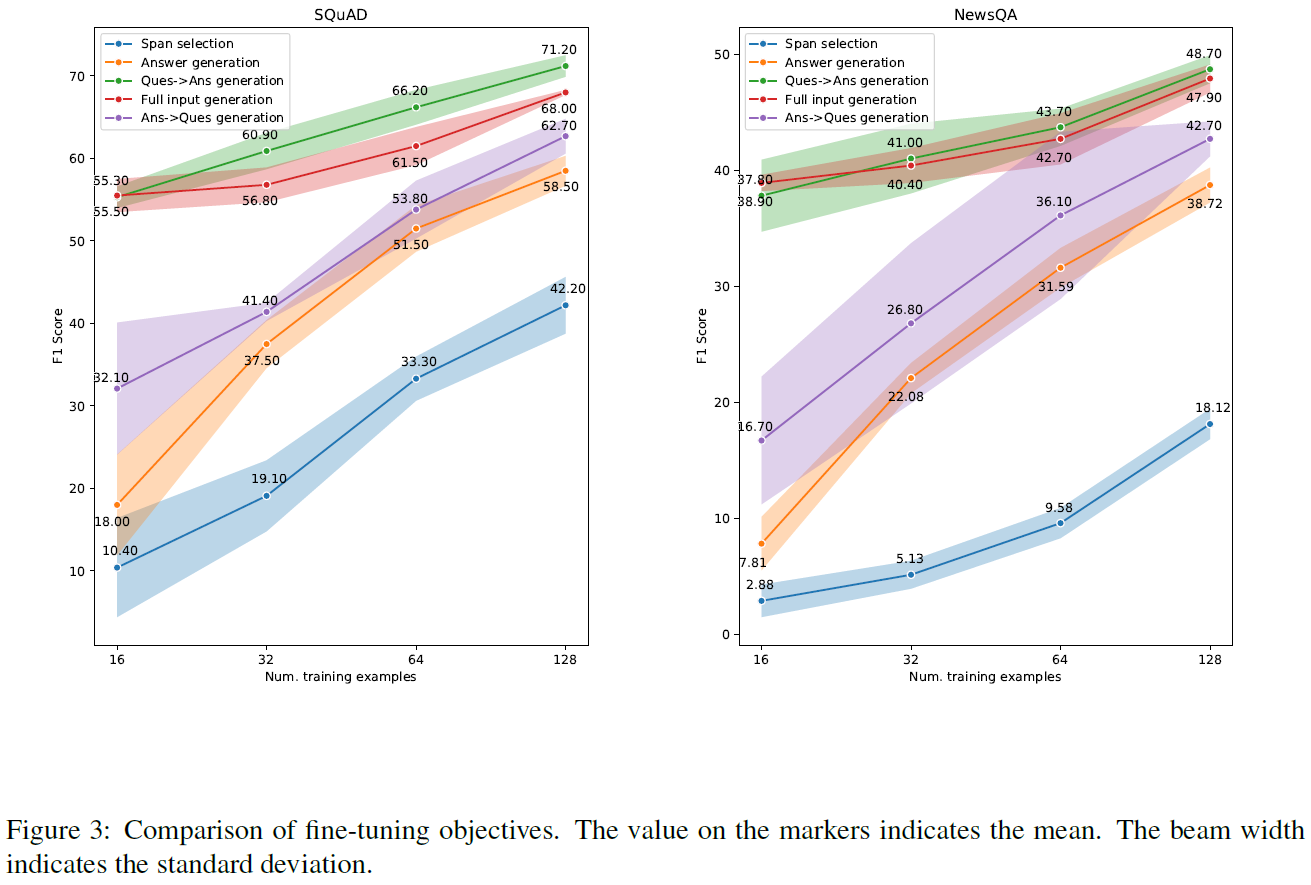
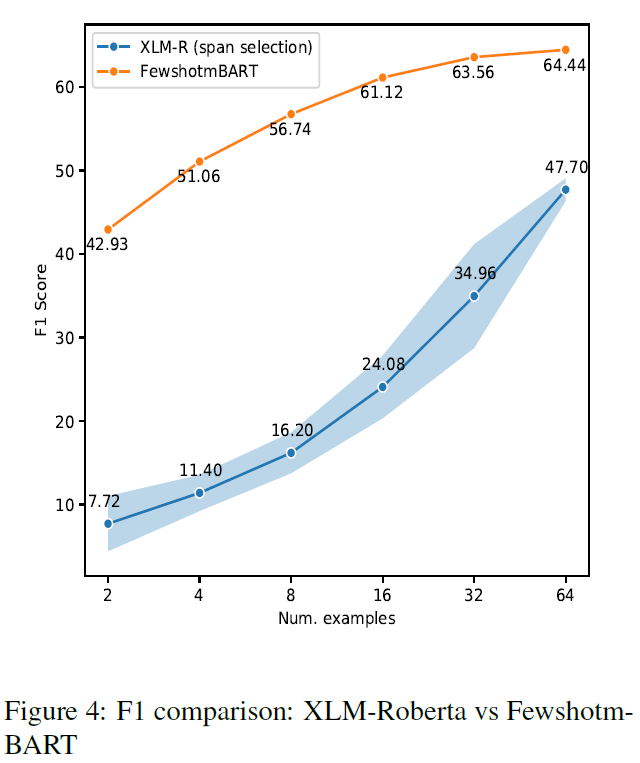
图 A 介绍了三种目前重要的预训练模型,BERT、BART 和 T5。图 B 是目前的微调框架。图 C 是本文提出的 FewshotQA 框架,可以看到主要是运用了 BART 和 T5。其中 BART 用于生成答案,T5 用于遮掩跨度生成。

损失函数:
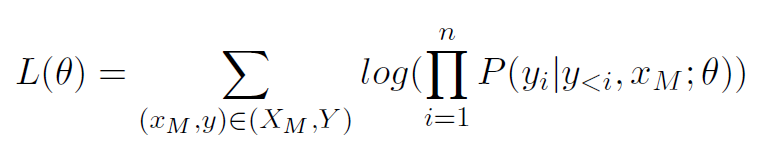
生成策略:文章设置了 BART 最多生成 50 个 token,T5 最多生成 25 个 token。
答案抽取:输出结果后,结果的格式:(question, answer, context),所以很容易就能获取答案。
跨语言扩展:改变预训练模型就行了。
2. 实验
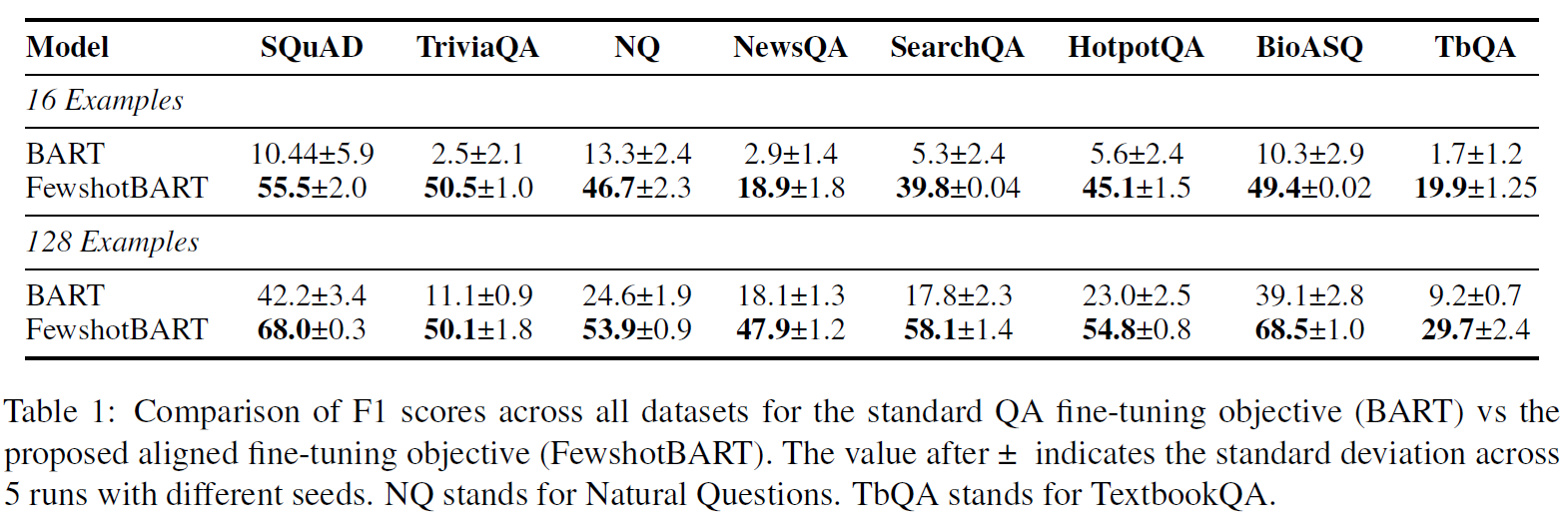
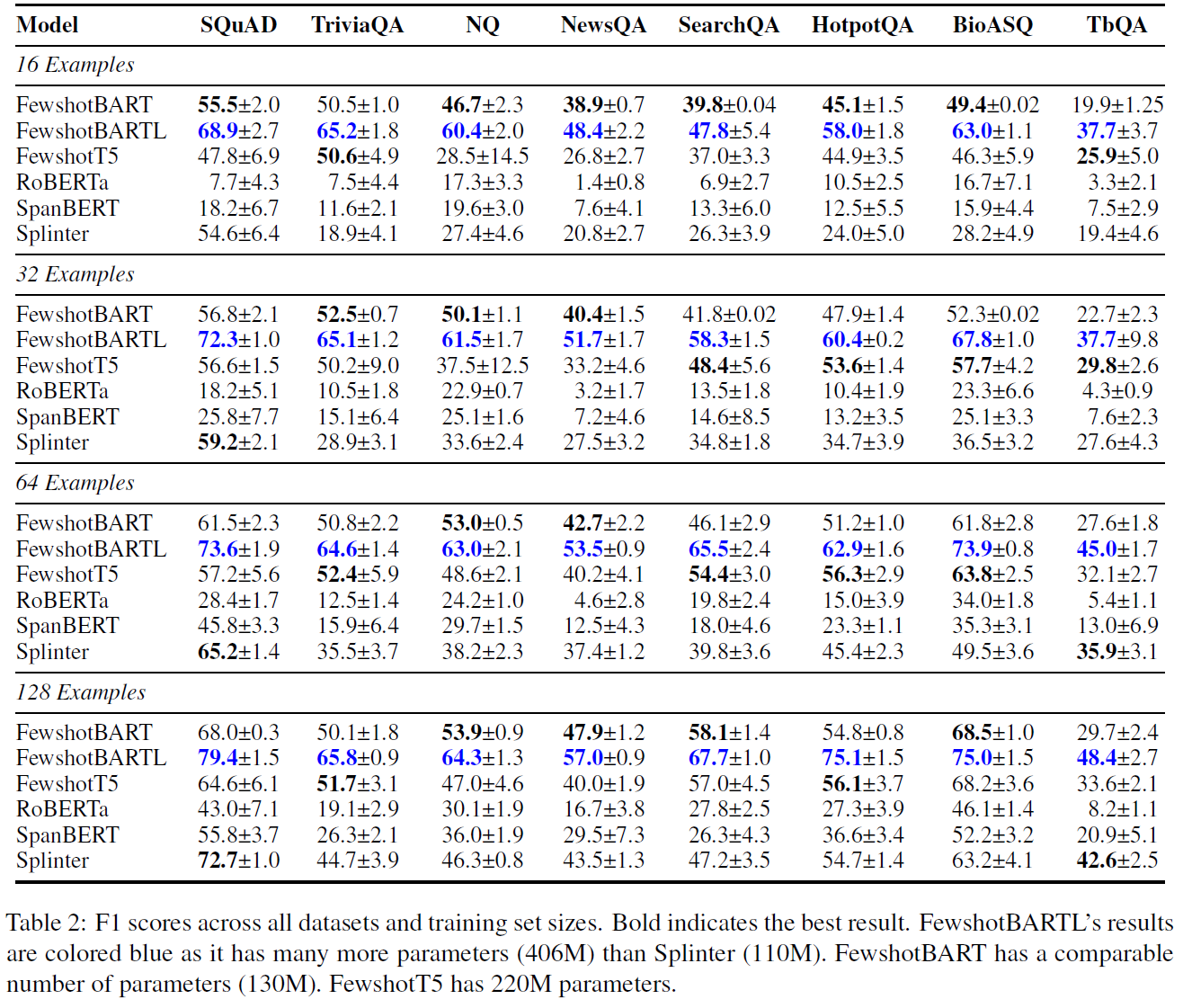
实验做的比较充分,主要集中在小样本学习领域,实验重点体现了不同数量样本对模型效果的影响。
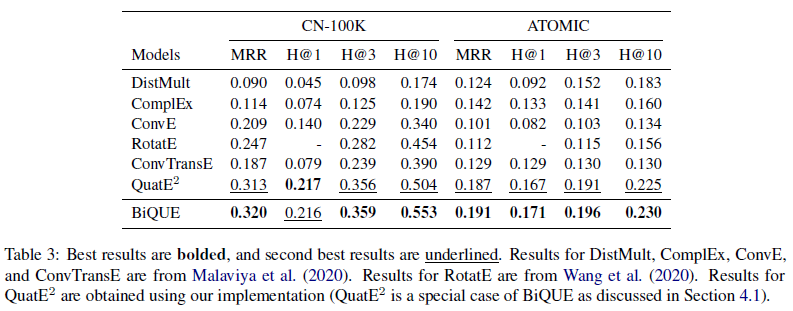
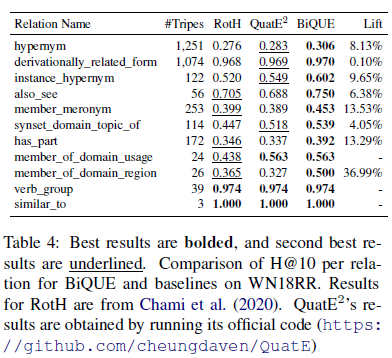
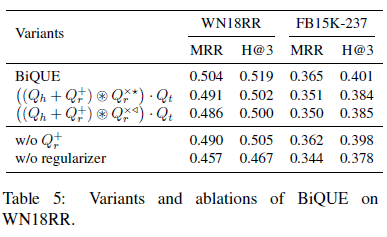
BiQUE: Biquaternionic Embeddings of Knowledge Graphs —— 论文阅读笔记
0. 摘要
BiQUE 结合了四种模型的优势:度量模型,翻译模型,欧氏空间模型和双曲空间模型,并在训练过程中进行了均衡。
1. 方法
2. 实验
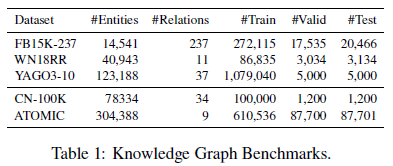
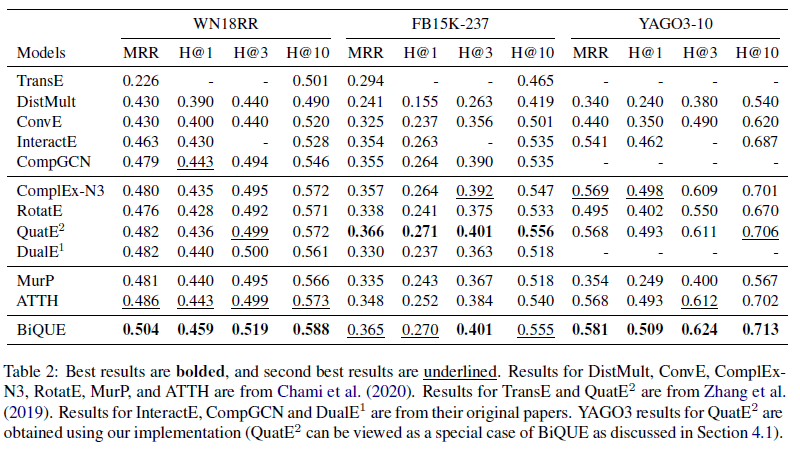
这篇论文的实验还是比较充分的。包括三个常规数据集的实验和两个超大型数据集的实验、针对不同关系的实验、消融实验、修改嵌入规模的实验、相同参数规模的实验等等,证明了模型的参数更少、对各种关系的效果好,以及对大规模数据集的效果好。后面实验可以参考借鉴。

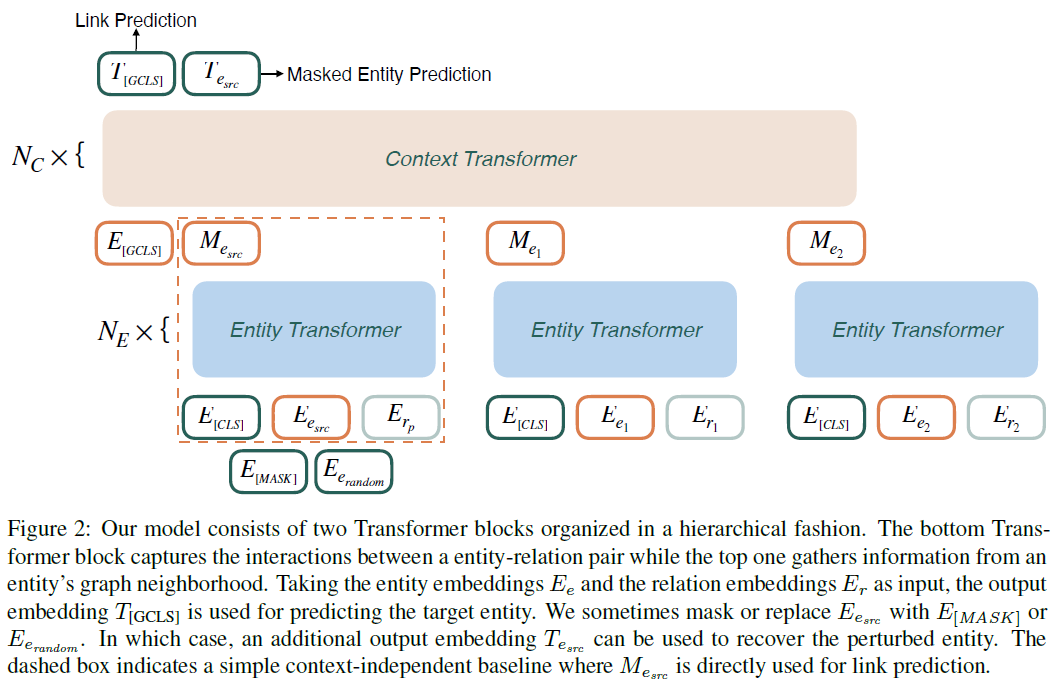
HittER: Hierarchical Transformers for Knowledge Graph Embeddings —— 论文阅读笔记
0. 摘要
本文研究复杂多关系知识图谱中的知识图谱嵌入问题。提出的方法由两个不同的 Transformer 模块组成,底部模块提取实体邻域中每个实体-关系对的特征,顶部模块汇总底部模块的关系信息。此外,文章还提出一种遮掩实体预测任务,以平衡来自上下文和实体本身的信息。
1. 方法
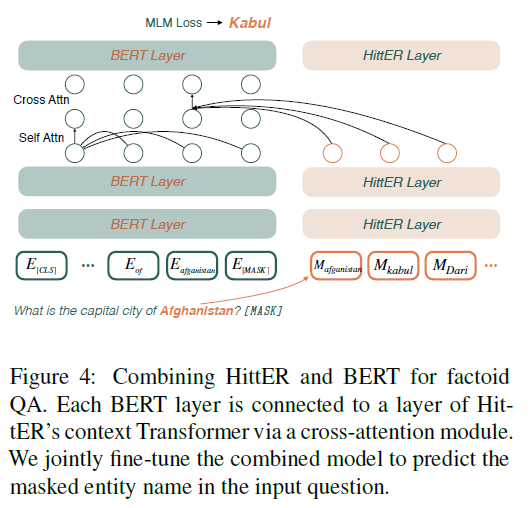
模型结构如下图所示。可以看到主要是 entity transformer 和 context transformer 组成,最简单的就是输入实体和关系嵌入作为输入,输出链接预测结果。同时文章还随机将实体嵌入替换成遮掩或者随机嵌入,并在结果预测原嵌入的值,从而提高模型鲁棒性。
损失函数是两个任务的求和结果。
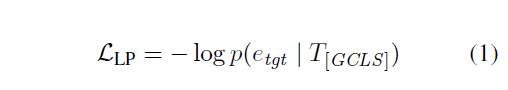
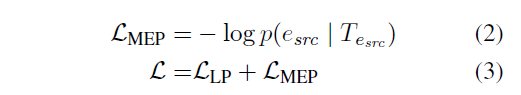
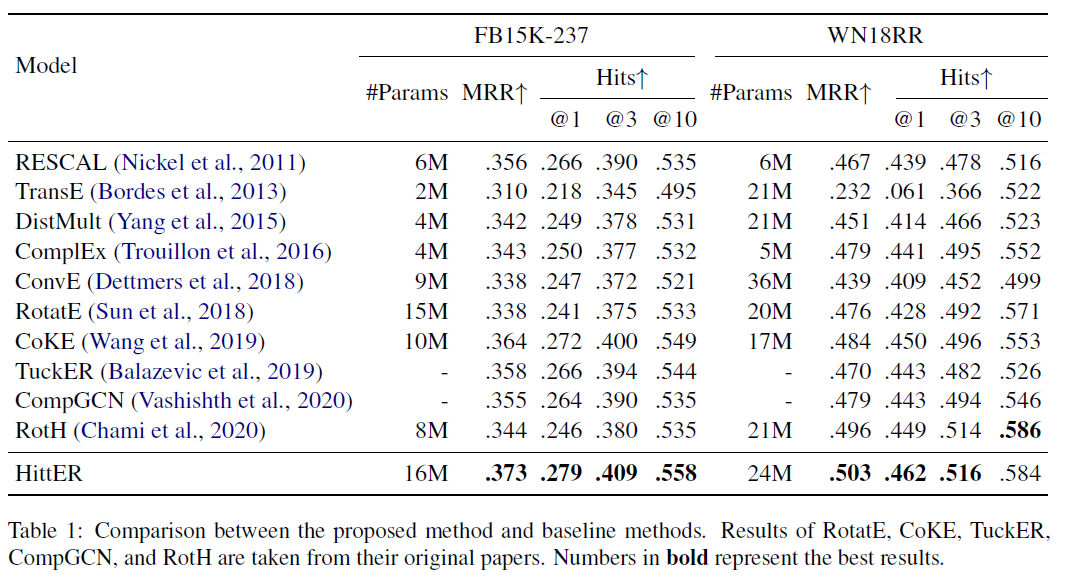
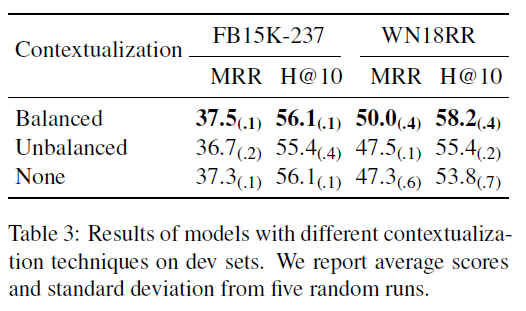
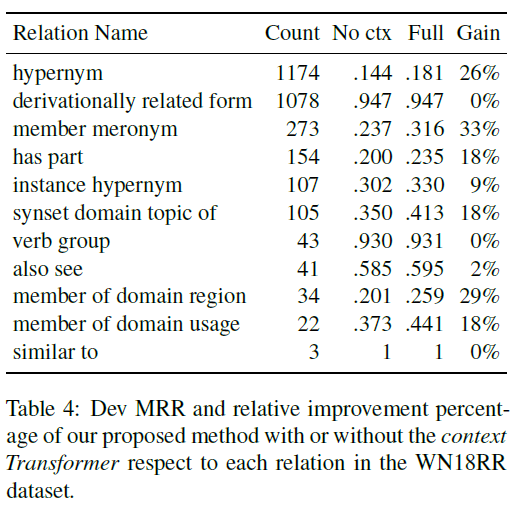
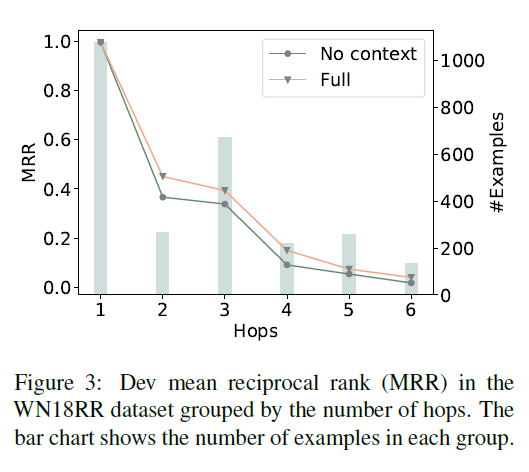
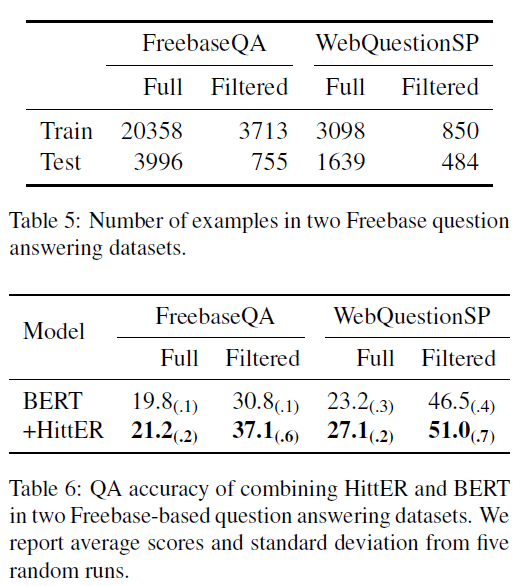
2. 实验
Contrastive Domain Adaptation for Question Answering using Limited Text Corpora —— 论文阅读笔记
0. 摘要
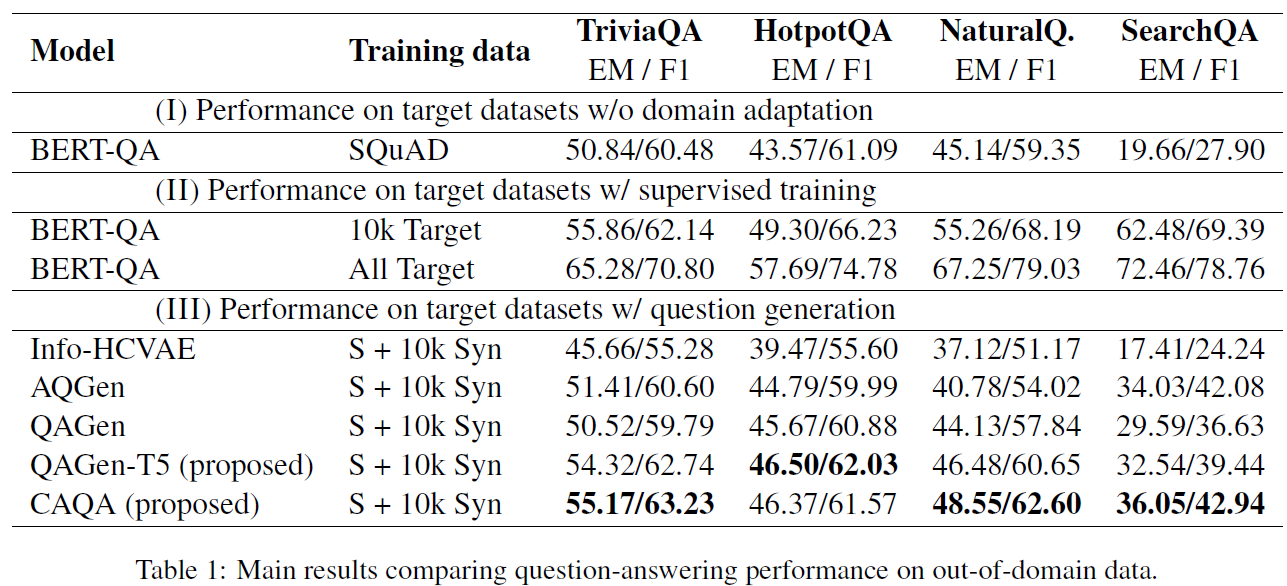
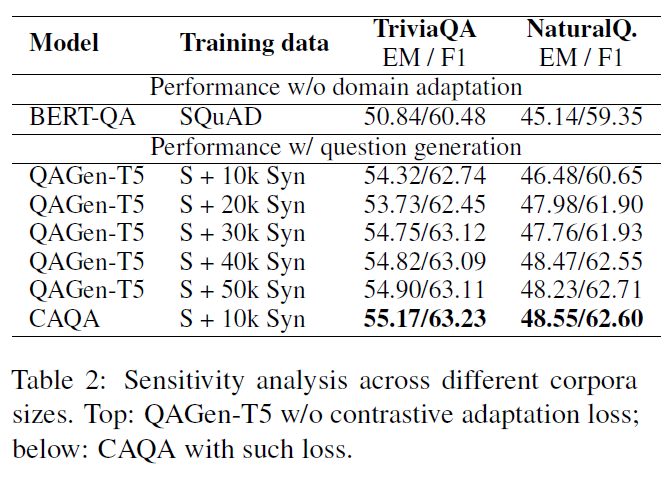
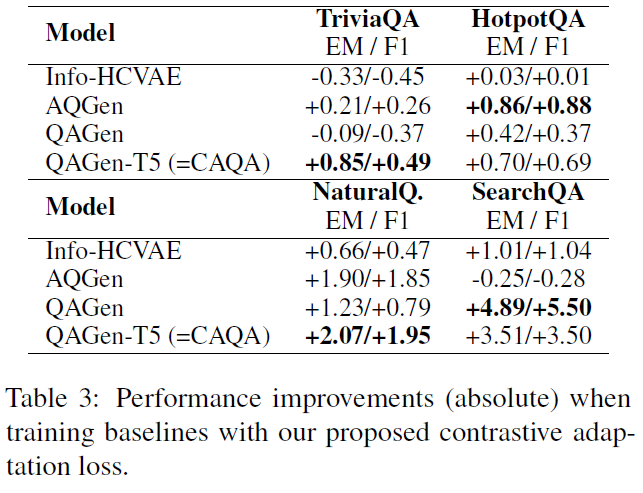
本文提出的 CAQA 模型结合了问题生成模型和领域不变问答(domain-invariant)模型,同时通过很少的语料,实现领域外问题的问答。
1. 方法
本文研究的是跨领域问答,因此设置学习域和目标域是不同的。
学习目标:
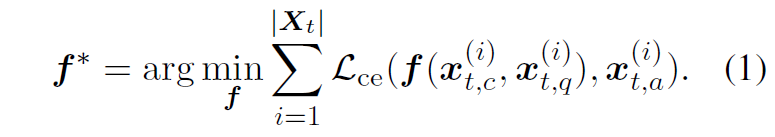
模型有三个部分:问题生成模块、问答模型、对比自适应损失部分,
模型结构图画的非常好看!一定要学习。可以看到隐藏了很多内部细节,但是都是大家比较熟悉的部分。同时由于 loss 有三种,所以单独弄了个模块来介绍,很清晰。

问题生成采用了 T5 模型,问题生成损失函数:
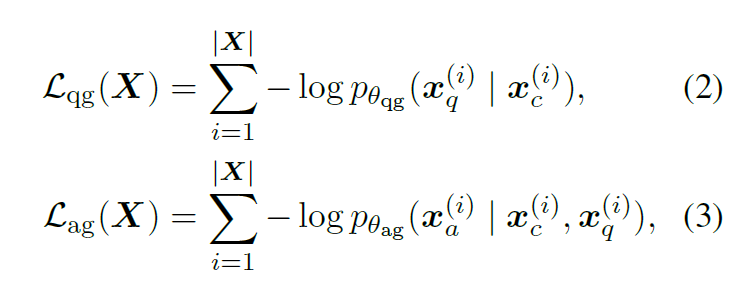
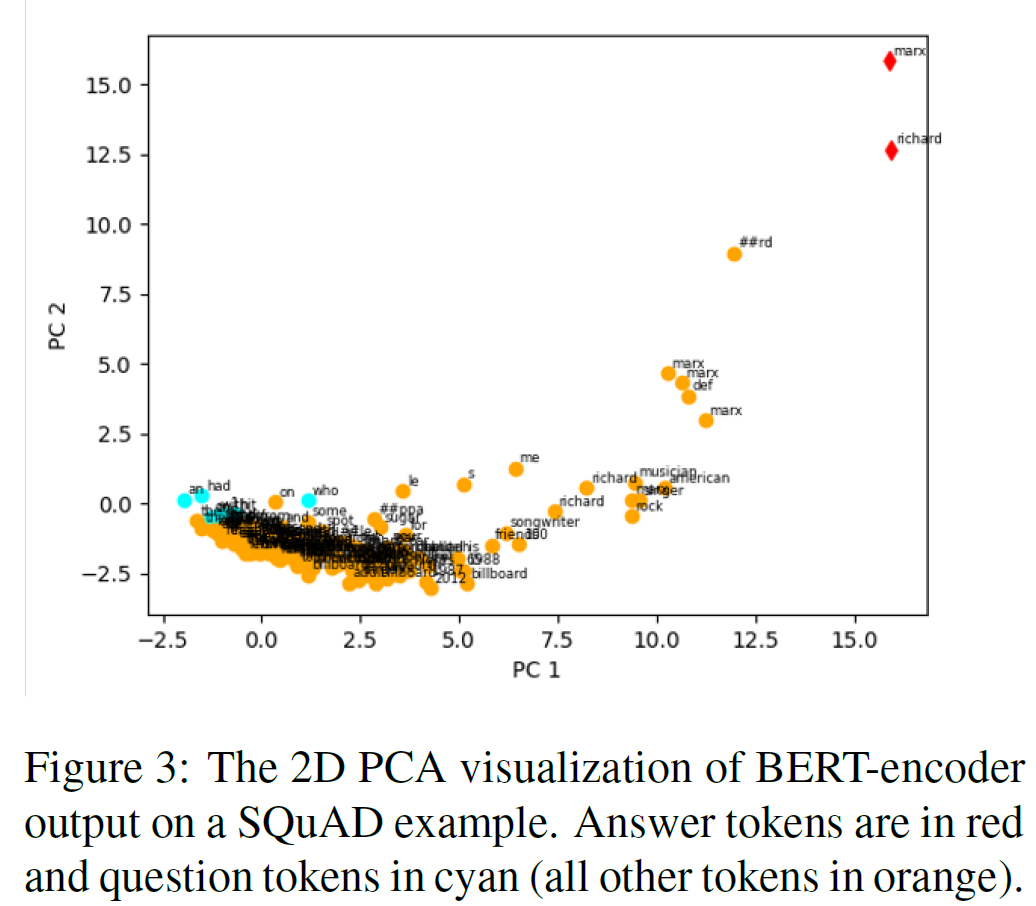
问答模型用了 BERT 模型。
对比自适应损失模块(我认为是这篇论文的核心)。


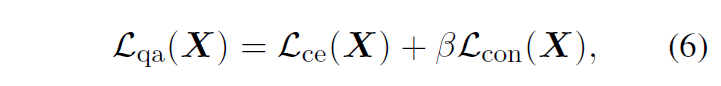
2. 实验
Pairwise Supervised Contrastive Learning of Sentence Representations —— 论文阅读笔记
0. 摘要
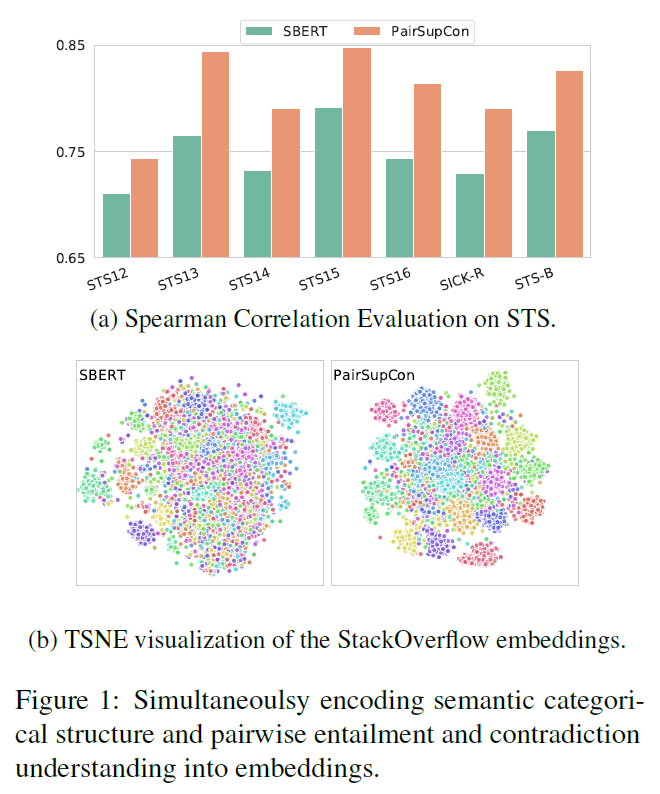
本文将模型与对比学习方法结合,将语义上的蕴含和矛盾关系和语义分类编码到一起。
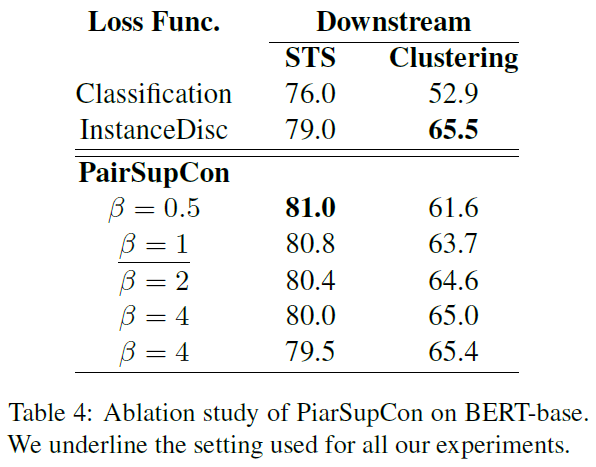
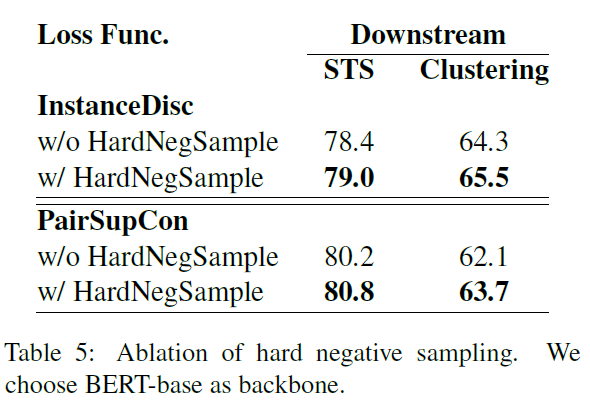
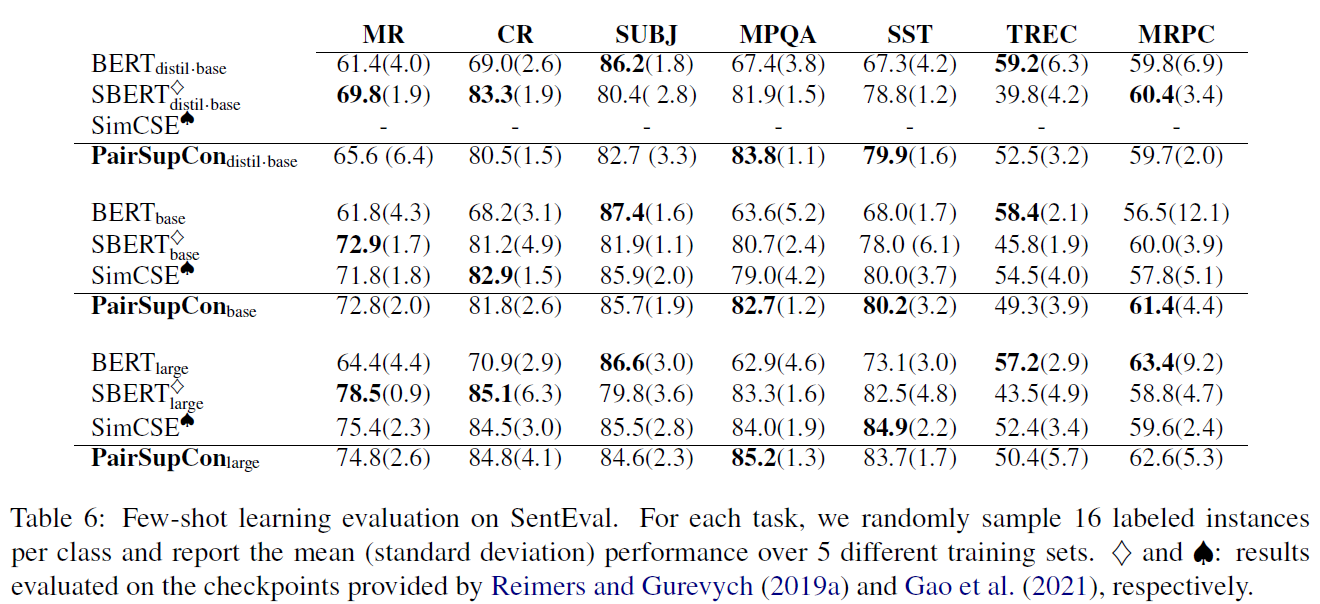
文章的实验比较多,比较充分。
1. 方法
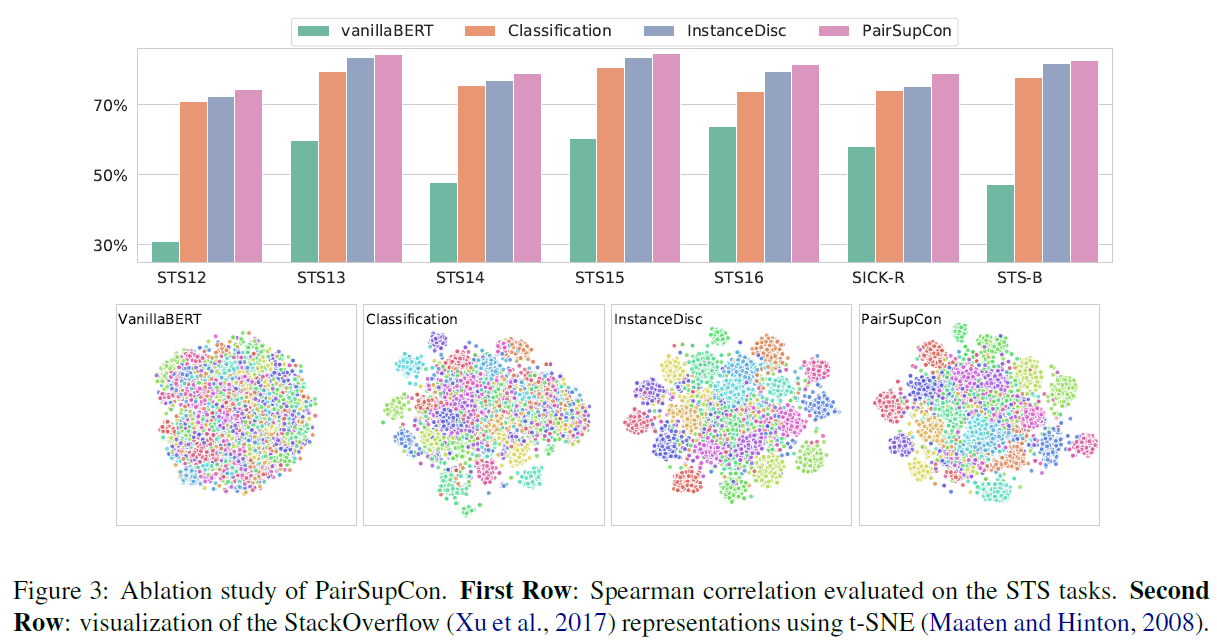
这个可视化的图不错,将分类和语义关系编码到一起。
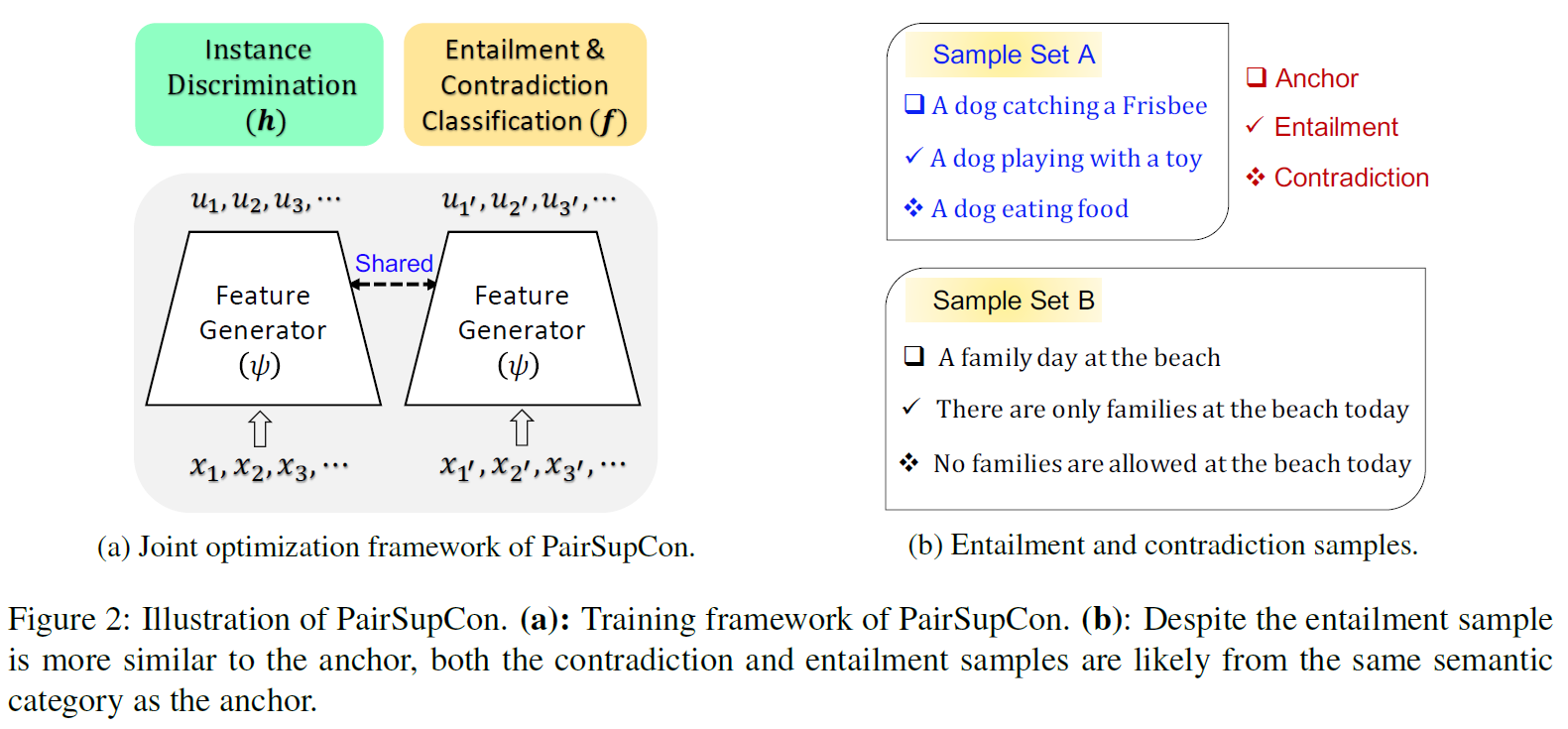
对比学习:
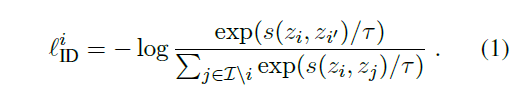
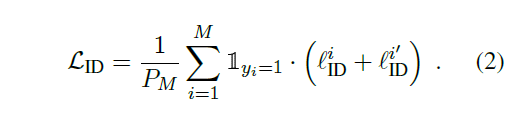
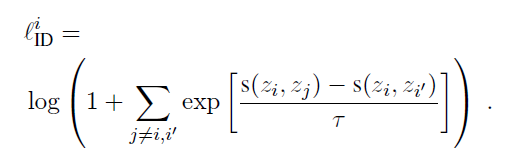

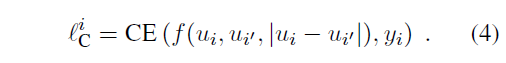
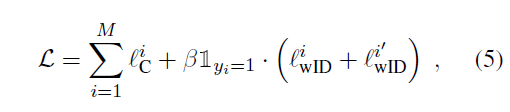
2. 实验
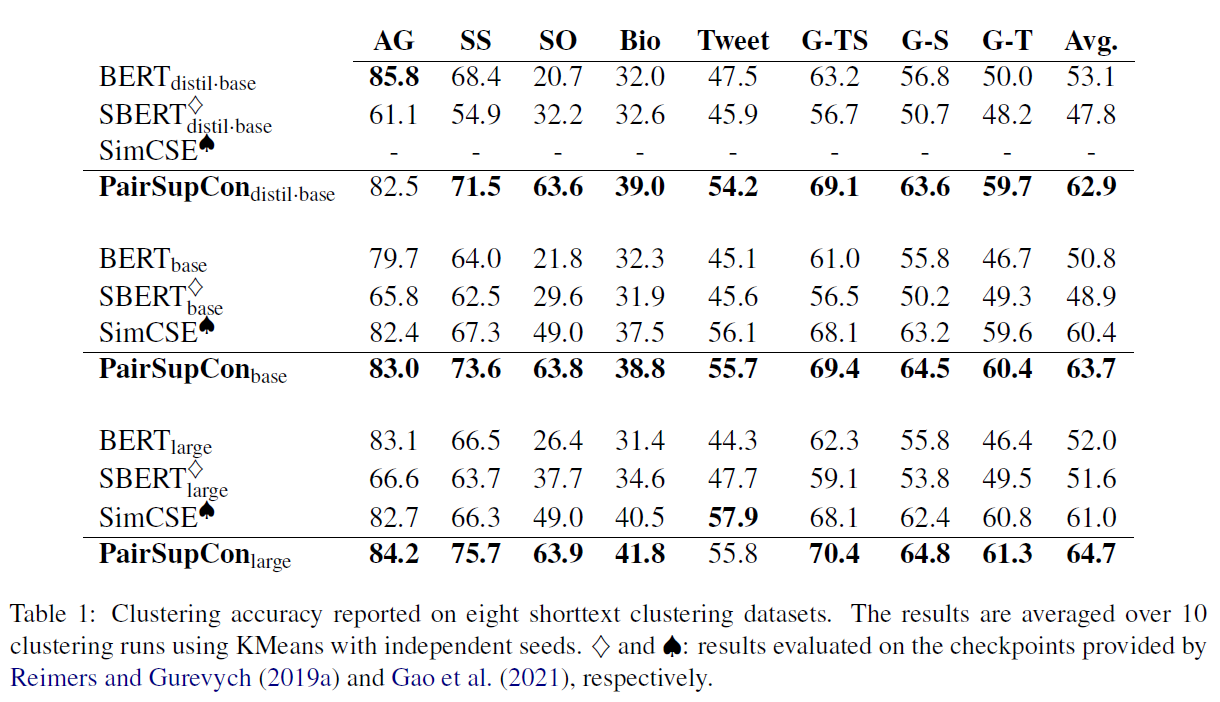
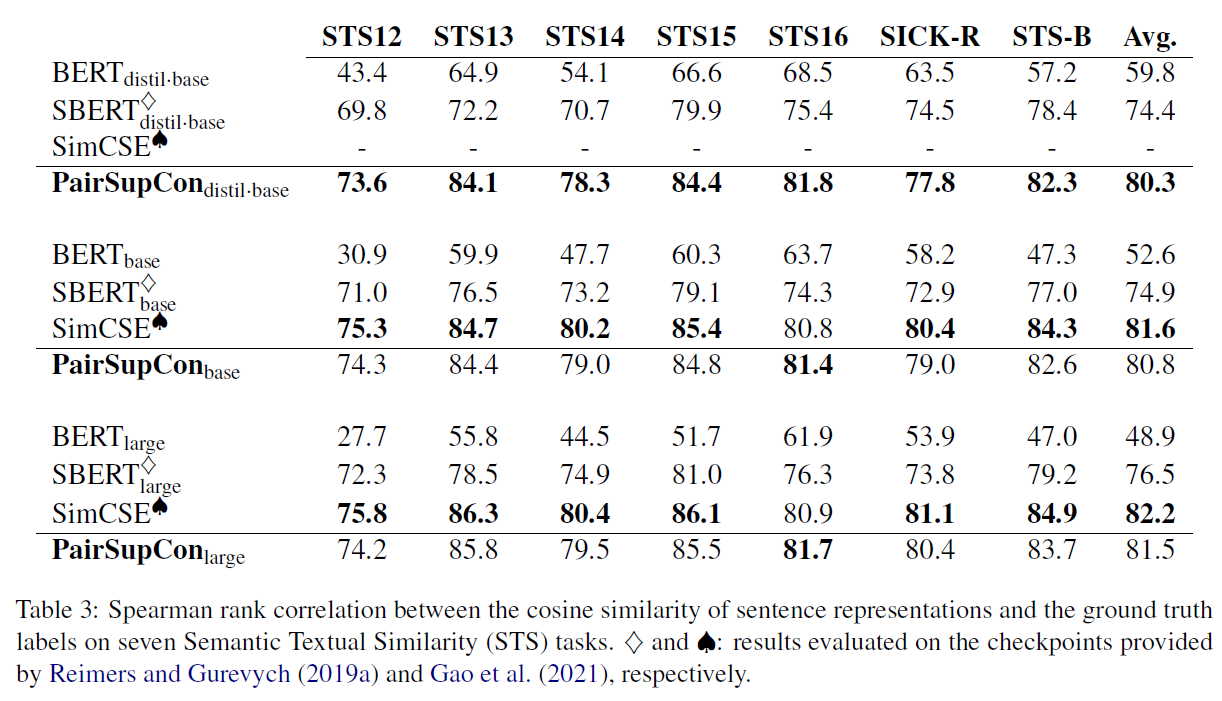
实验比较充分。图画的很好,值得学习。
SimCSE: Simple Contrastive Learning of Sentence Embeddings —— 论文阅读笔记
0. 摘要
本文首先提出一个无监督方法,输入一个句子,并在对比学习过程中预测自己,仅采用 dropout 作为噪声。结果可以与监督学习相比。其中 dropout 有很重要的作用。
文章是在标准语义文本相似性 STS 任务上评估模型,Spearman 相关性改善较多。
1. 方法
方法框架图:
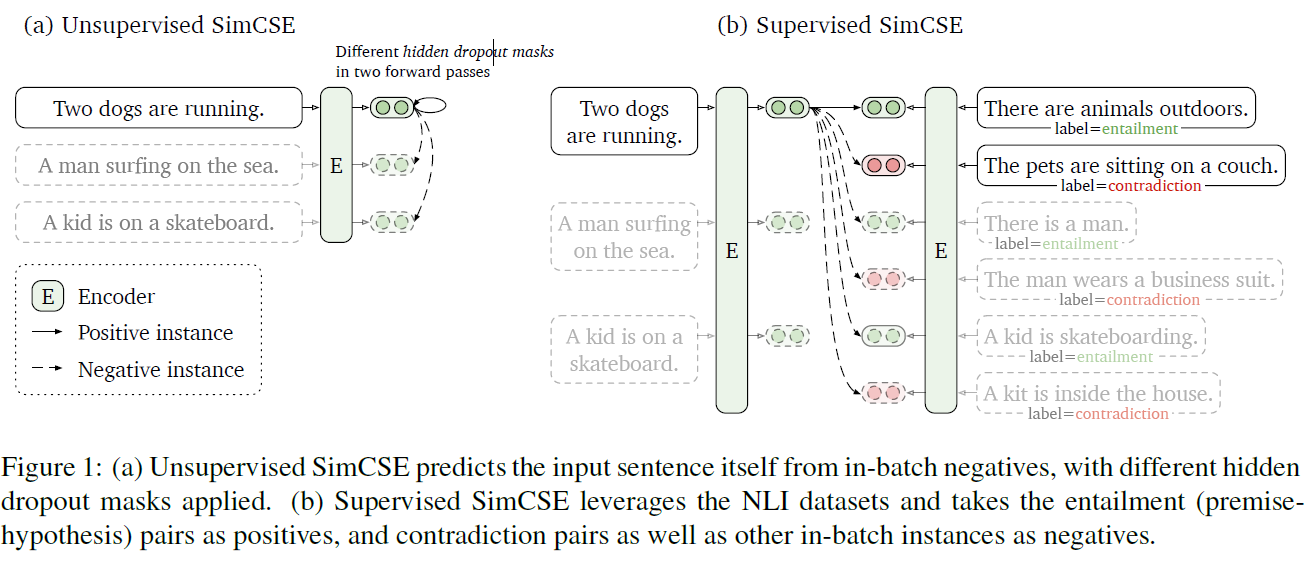
对比学习首先需要构建语义相关实体对,也就是一种聚类。本文通过 BERT 和 RoBERTa 获取实体嵌入。
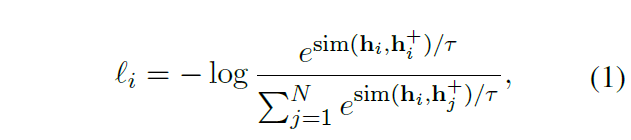
模型引入了 alignment 和 uniform 两个关键特性,以提高对比学习的质量。
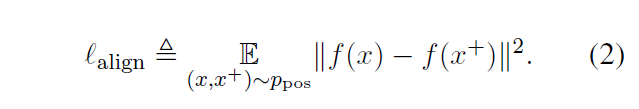
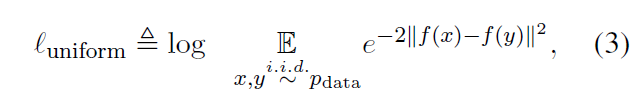
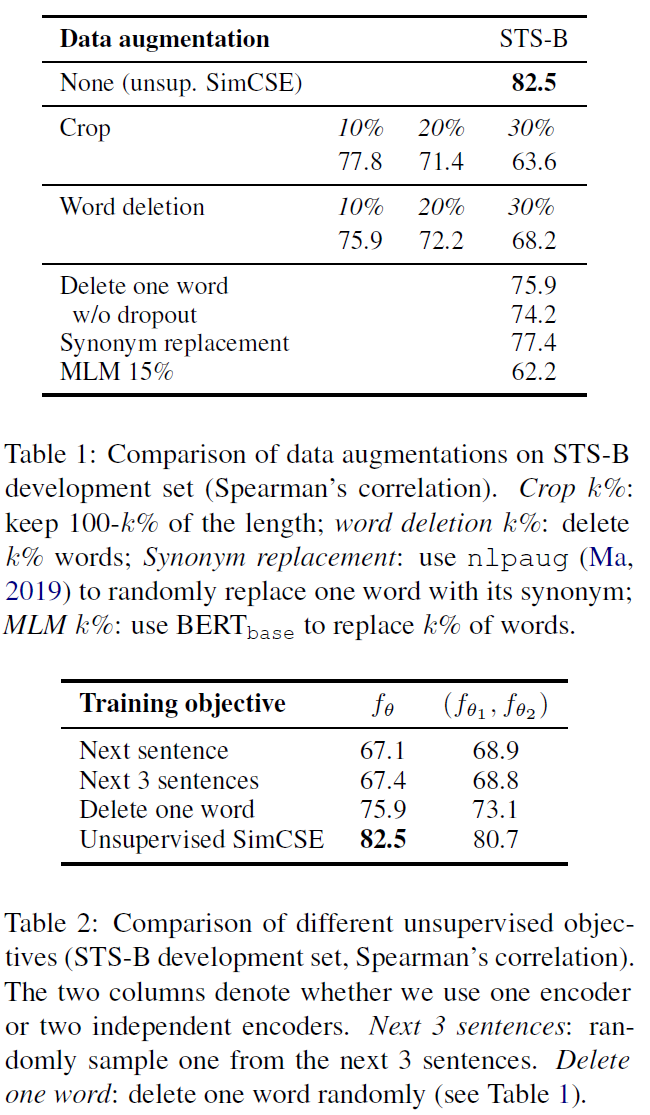
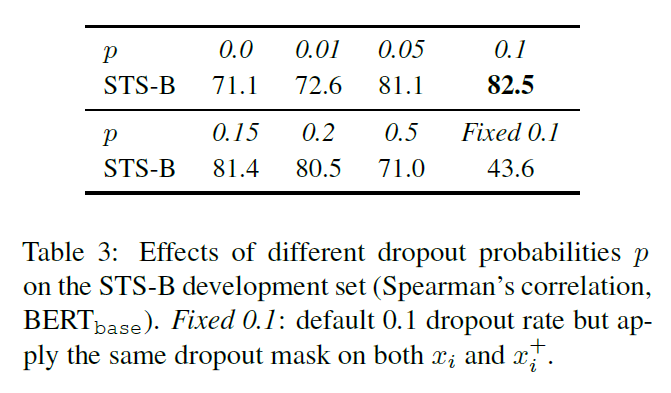
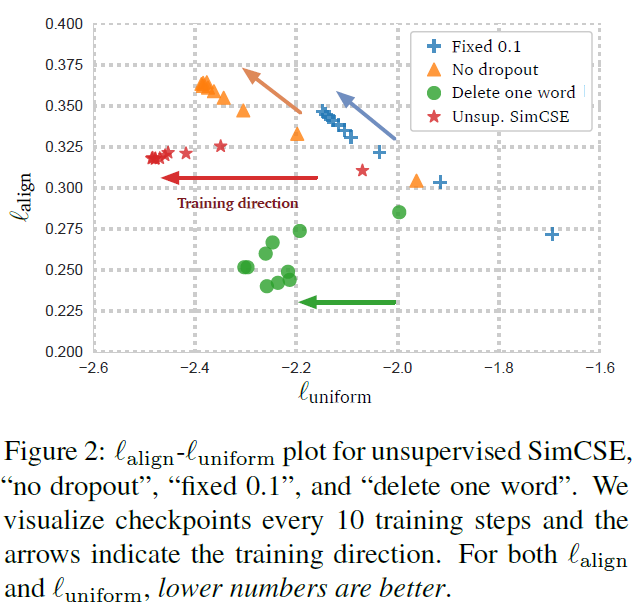
1.1 无监督学习
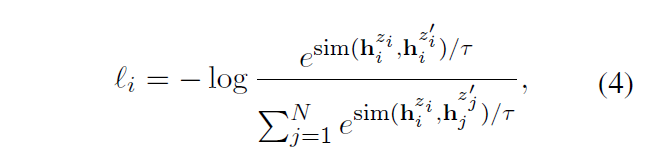
1.2 有监督学习
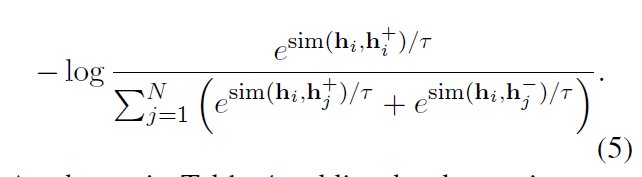

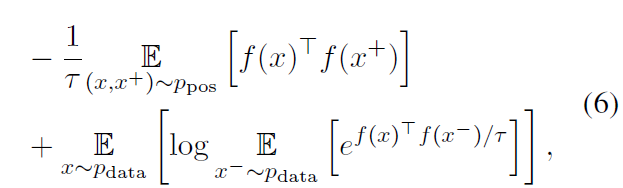
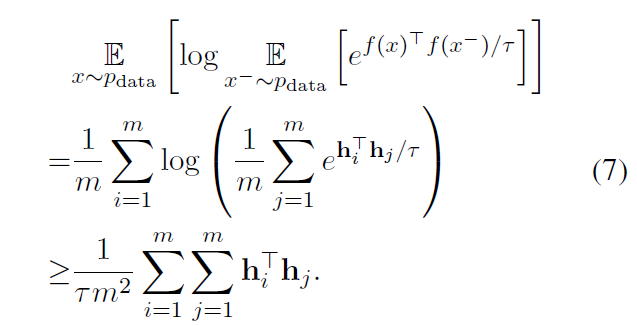
2. 实验
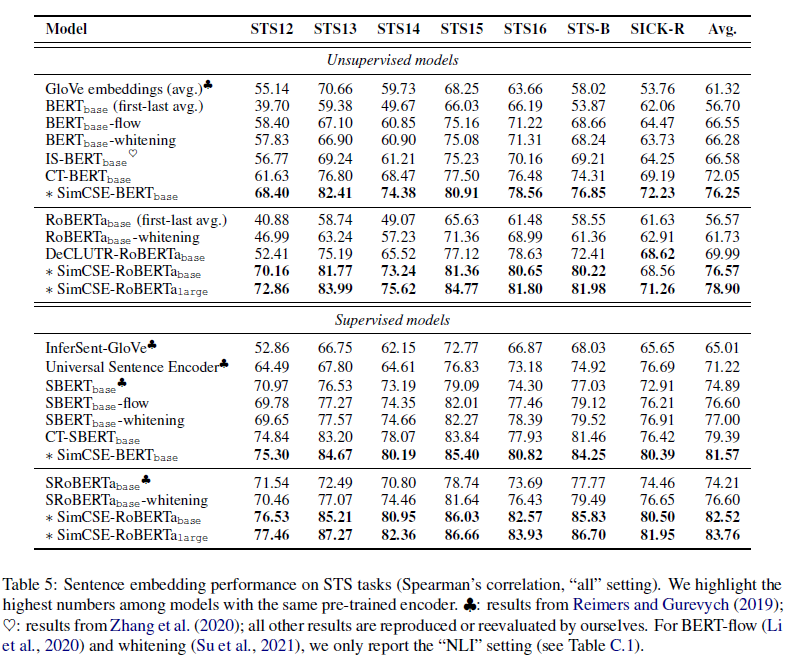

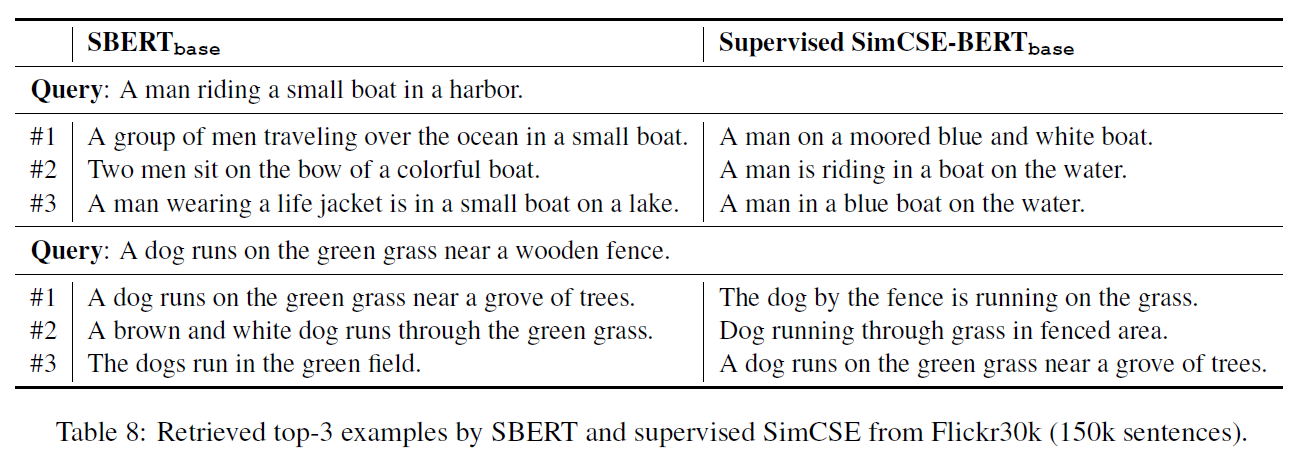
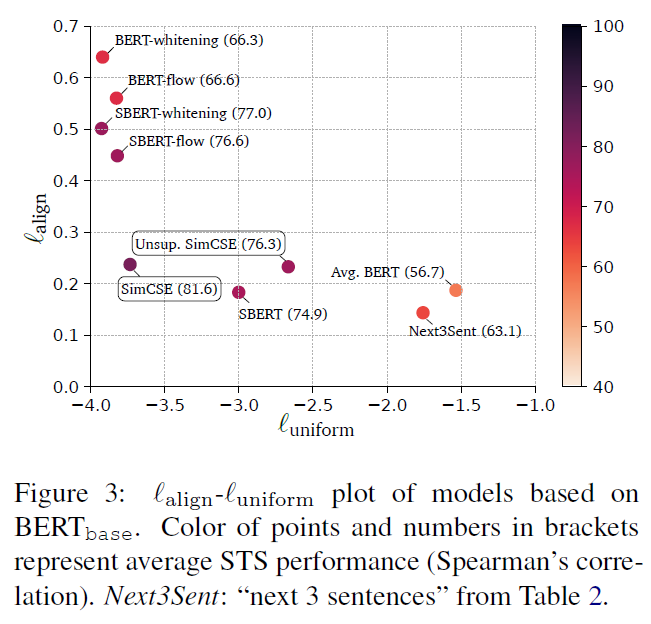
3. 思考
这篇文章的介绍很详细,同时实验内容也很充分。提出的无监督学习方法优于监督学习方法,很神奇,可以多分析分析。
Comments | 3 条评论
不得不说这个个人博客做的很不错。赞一个。
@紫喵 哎嘿,感谢支持~
点赞,学习了