





这篇文章是王杰组发表在 ACL 2021 的论文,非常有启发性。
论文地址:Deep Cognitive Reasoning Network for Multi-hop Question Answering over Knowledge Graphs
论文代码:未提供
0. 摘要
知识图 (KG) 提供人类知识,其中节点和边分别是实体和它们之间的关系。 KGs上的多跳问答——旨在通过KGs中的推理路径找到给定问题的答案实体——最近引起了学术界和工业界的极大关注。然而,这项任务仍然具有挑战性,因为它需要在大型候选实体集中准确识别答案,其大小随着推理跳数的数量呈指数增长。为了解决这个问题,我们提出了一种新颖的深度认知推理网络(DCRN),其灵感来自认知科学中的双重过程理论。具体来说,DCRN 由两个阶段组成——无意识阶段和有意识阶段。无意识阶段首先通过利用其语义信息从候选实体中检索信息证据。然后,有意识阶段通过根据检索到的证据的图结构执行顺序推理来准确识别答案。实验表明,DCRN 在基准数据集上明显优于最先进的方法。
1. 引言
知识图 (KG) 存储结构化的人类知识,其中节点表示实体,边表示实体对之间的关系。 KG 上的多跳问答 (KGQA) 旨在通过推理 KG 中的路径来找到答案实体。我们用图 1 中的一个例子来说明这个任务。最近,KG 上的多跳问答引起了学术界和工业界的极大关注。然而,这个任务仍然具有挑战性,因为候选实体的数量随着推理跳数的数量呈指数增长,因此难以准确识别答案。
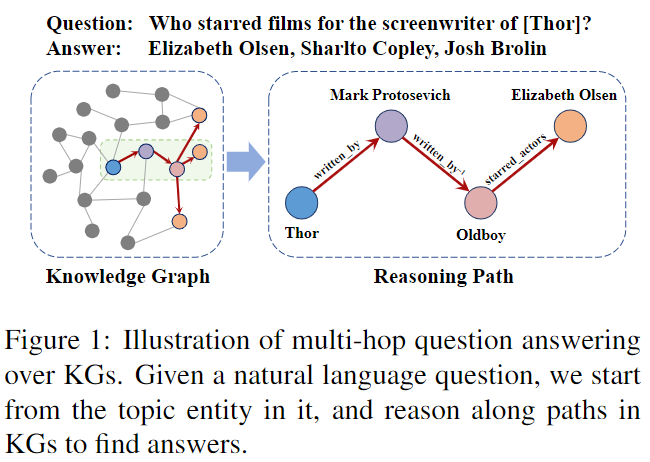
- 图:基于 KG 的多跳问答的图解。给定一个自然语言问题,我们从其中的主题实体开始,沿着 KG 中的路径推理以找到答案
以前的工作通过减少候选实体集的大小来缓解这个问题,但他们经常牺牲答案的召回。这些方法包括 GRAFT-Net 和 PullNet,首先提取特定问题的子图,然后通过图神经网络对提取的子图进行多跳推理(GNN) 来寻找答案。然而,这些方法通常会牺牲对答案的召回来换取小的候选实体集。也就是说,提取的子图可能根本不包含答案。答案实体的召回和候选实体集的大小之间的这种权衡限制了它们的实际使用。因此,仍然希望找到一种能够在不牺牲召回率的情况下准确识别答案的方法。
为了解决这个问题,我们从认知科学中的双重过程理论中汲取灵感,提出了一种新颖的深度认知推理网络 (DCRN)。在认知科学中,研究人员发现人类可以通过大容量记忆推理来找到答案。具体来说,双过程理论认为人类完成认知任务的方式是首先利用快速直觉通过无意识过程检索与任务相关的证据,然后根据上述证据进行顺序推理以得出答案通过一个有意识的过程。同样,提出的 DCRN 由两个阶段组成。第一个是无意识阶段,它可以通过选择最有可能是正确答案的候选实体来检索信息证据。第二个是有意识阶段,它可以通过基于从第一阶段检索到的证据使用贝叶斯网络执行顺序推理来准确识别答案。实验表明,DCRN 在基准数据集上明显优于最先进的方法。
2. 背景
多跳 KGQA:给定一个知识图 G = {E, R, T} 和一个自然语言问题 q,其主题实体 etopic ∈ E,KGQA 的任务是通过 e∗ argmax ei∈E f(ei) 预测问题 q 的答案,其中 f(ei) 是衡量 ei 作为正确答案的合理性的得分函数。在多跳 KGQA 中,不能保证答案是给定问题中主题实体的直接邻居。因此,通常需要对 KG 进行多跳推理才能找到答案。
贝叶斯网络:是一种概率图形模型,它通过有向无环图 (DAG) 表示一组变量及其条件依赖关系。在贝叶斯网络中,节点代表随机变量,有向边代表随机变量之间的条件依赖。
3. 相关工作
3.1 多跳 KGQA
多跳 KGQA 最近的工作可以分为两类:语义解析方法和信息检索方法。语义解析方法首先将给定问题解析为可执行查询,然后执行查询以找到答案。信息检索方法将问题和知识图嵌入到低维空间中,然后根据问答语义相似度找到答案。我们提出的 DCRN 属于信息检索方法。
Key-Value Memory Network (KV-Mem) 2016:是 Memory Network 2015 的一种变体,它基于一个记忆组件进行推理,即一个存储知识图谱三元组的数组。 KV-Mem 迭代地从内存中读取来更新问题嵌入,用于匹配正确答案。
Variational Reasoning Networ 变分推理网络 (VRN) 2018:为多跳 KGQA 提出了一个变分框架。为了识别答案,它计算问题类型和每个候选者的推理图之间的兼容性分数。然而,由于候选答案数量呈指数增长,它在长距离推理时性能较差。
GRAFT-Net 2018:首先基于个性化页面排名 (PPR) 提取特定问题的子图,然后使用图神经网络 (GNN) 对子图进行编码以识别答案。然而,提取的子图不仅很大,而且对答案实体的召回率很低。
PullNet 2019:通过可训练的子图扩展策略缓解了 GraftNet 的问题。它从问题中提到的实体列表开始构造问题特定的子图,然后迭代地“拉”相关实体以扩展子图。然而,它不可避免地牺牲了答案实体的召回以换取小的候选实体集,这限制了它在实际使用中的性能。
EmbedKGQA 2020:将多跳 KGQA 建模为链路预测任务。它首先将给定问题嵌入到潜在关系嵌入中,然后利用知识图谱嵌入技术来识别答案。
3.2 KGQA 中的 KGE
知识图嵌入(KGE)方法旨在将知识图谱内的实体和关系映射到分布式表示(向量)中,矩阵等)。这些嵌入通常由链接预测任务训练,其中需要模型来预测三元组中缺失的头部或尾部实体。 EmbedKGQA(2020)使用 ComplEx(2016)来训练知识图嵌入,它将实体和关系嵌入表示为复杂空间中的向量。为了与包括 GRAFT-Net(2018)和 PullNet(2019)在内的先前工作进行公平比较,我们使用 Canonical Polyadic (CP) 分解(1927)来训练我们提出的 DCRN 的知识图谱嵌入,它将实体和关系嵌入表示为真实空间中的向量。
4. 方法
4.1 动机
对于多跳问题,从大量候选集中准确识别答案具有挑战性,其规模随着推理步骤的数量呈指数增长。现有方法旨在通过提取特定问题的子图来减小候选实体集的大小。然而,这些方法通常会牺牲对答案的召回来换取小的候选集,这限制了它们在实际使用中的表现。我们从认知科学中的双重过程理论中获得灵感。具体来说,该理论认为,人类完成认知任务的方式是首先利用快速直觉通过无意识过程(系统 1)检索与任务相关的证据,然后根据上述证据执行顺序推理,通过以下方式得出答案。一个有意识的过程(系统 2)。受认知科学中的双重过程理论的启发,我们提出了用于多跳 KGQA 的深度认知推理网络(DCRN)。DCRN 由两个阶段组成。第一个是无意识阶段,它可以通过利用候选实体的语义信息从候选实体中检索信息证据。第二个是有意识阶段,它可以根据第一阶段检索到的证据的图结构进行顺序推理,准确识别答案。 DCRN的整体架构如图2所示。在DCRN中,基本模块是路径解码模块,基于它是两个阶段——无意识阶段和有意识阶段。
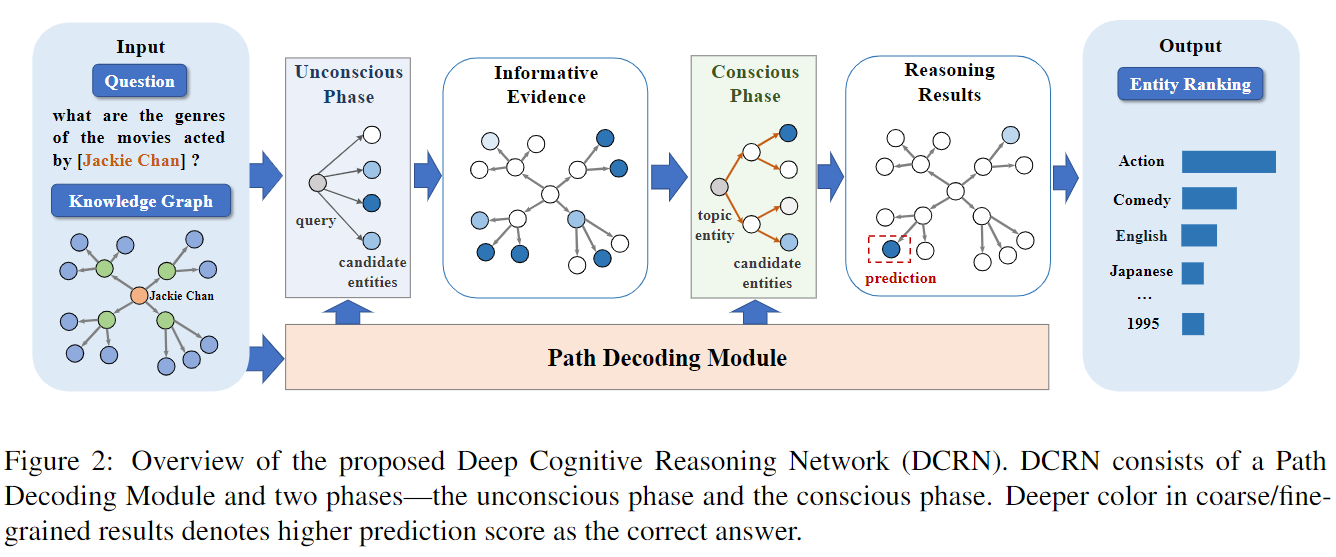
- 图 2:拟议的深度认知推理网络 (DCRN) 概述。 DCRN 由路径解码模块和两个阶段组成——无意识阶段和有意识阶段。粗/细粒度结果中颜色越深表示正确答案的预测分数越高。
4.2 路径解码模块
路径解码模块是 DCRN 的基本组件。由于多跳 KGQA 需要多跳推理才能到达答案实体,因此我们在本模块中从问题中解码推理路径信息。具体来说,我们采用基于 RNN 的编码器-解码器结构,首先将问题编码为隐藏表示,然后对该表示进行解码以获得推理路径信息,即每个推理步骤中每个关系的分数。这些分数将用于无意识和有意识阶段。首先,我们使用 RNN 对给定问题 q 进行编码,以获得其潜在表示 q ∈ Rd。
然后,我们解码这个表示 q 以获得推理路径信息。我们在图 3 中说明了这个过程。在解码的每个步骤中,解码器都会预测每个关系的分数。步骤 t 的预测是解码器在步骤 t + 1 的输入。
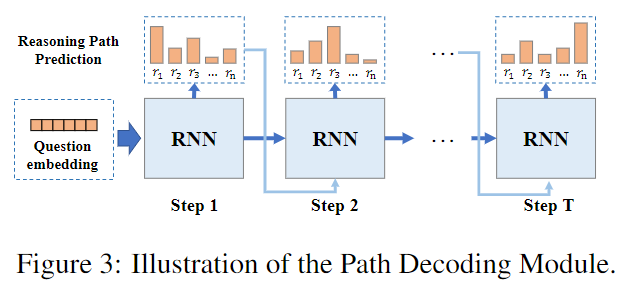
- 图3:路径解码模块图示。
在步骤 t,给定前一次迭代的隐藏状态 h(t-1) 和输入 i(t),RNN 解码器通过以下方式输出更新的隐藏状态 h(t)。
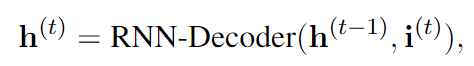
其中初始隐藏状态 h(0) 被初始化为问题嵌入 q,初始输入 i(0) 是零向量。然后,我们计算步骤 t 的输出:
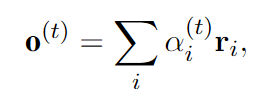
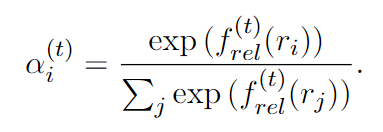
请注意,f (t) rel (ri) 表示每个关系在步骤 t 的分数,计算公式为:
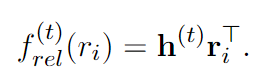
随后,步骤 t 的输出将是步骤 t + 1 的输入。即 i(t+1) = o(t)。
4.3 无意识阶段
无意识阶段对应于认知科学的双重过程理论中的无意识过程(系统1)。在这个阶段,我们通过利用它们的语义信息从候选实体中检索信息证据。证据是指预测哪些候选人最有可能是正确答案的结果。我们期望检索到的证据能够有效地过滤掉那些与给定问题无关的候选实体。为了实现这一点,我们在给定问题和每个候选实体之间执行语义匹配。候选实体 e 的语义匹配分数 fs(e) 为:
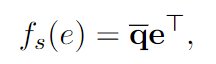
其中 q ∈ R1×d 是基于给定问题获得的查询嵌入,e ∈ R1×d 是实体 e 的嵌入。在我们的模型中,实体嵌入 e ∈ Rd 由 C(1927)模型预训练。因此,无意识阶段的关键是设计信息查询表示 q ∈ Rd。为了设计信息丰富的查询表示,我们从 PTransE(2015)中获得灵感,它将知识图嵌入扩展到关系路径。在 PTransE 中,如果关系路径 e1 r1 −→ e2 r2 −→ ... rn−1 −−−→ en 成立,则 PTransE 优化以下目标:
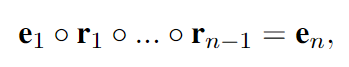
其中 ◦ 是合成操作,可以是加法、逐元素乘法、RNN 等。这个目标可以被认为是查询 e1 ◦ r1 ◦ ... ◦ rn-1 与其目标 en 之间的语义匹配。
类似地,我们对查询表示 q 进行如下编码。首先,推理路径的起始实体是给定问题中的主题词 etopic。其次,回想一下我们在路径解码模块中解码推理路径信息,其中步骤 t 的输出(即 o(t))表示关系嵌入的加权和。因此,我们将查询嵌入表示为:
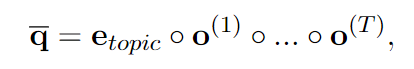 、
、
其中 ◦ 表示该公式中的元素乘法,T 表示路径解码模块中的步骤数(即推理步骤数)。
4.4 有意识阶段
有意识阶段对应于认知科学的双重过程理论中的有意识过程(系统2)。在这个阶段,我们通过根据从无意识阶段检索到的证据的图结构执行顺序推理来准确识别答案。为了对顺序推理进行建模,我们从意识先验中获得灵感(2017)。它表明,有意识的过程一次只涉及几个变量,可以建模为因子图,这是一种知识表示形式,一次分解为涉及几个变量的片段。在这项工作中,我们基于贝叶斯网络执行顺序推理,可以将其视为一种因子图。首先,我们从给定的 KG 构建特定问题的贝叶斯网络,其中我们将实体的预测视为随机变量,将关系视为它们之间的关系依赖关系。其次,我们对贝叶斯网络进行边际推理,以预测每个候选实体作为正确答案的概率。
4.4.1 贝叶斯网络构建
我们通过以下两个步骤从给定的 KG 构建特定问题的贝叶斯网络。首先,我们对 KG 进行图修剪以获得有向无环图(DAG)。其次,我们将 DAG 转换为贝叶斯网络。
给定一个知识图 G = {E, R, T} 和一个主题实体 etopic ∈ E 的问题 q,我们通过应用广度优先搜索 (BFS) 算法实现知识图谱修剪,并获得一个有向无环图。具体来说,我们只在搜索过程中保留访问过的边,并删除未访问过的边。我们在图 4 中说明了这个过程,其中我们从主题实体开始执行两步 BFS,并修剪未访问的边缘。请注意,在之前的工作之后,我们为 KG 中的每个关系 r 添加了逆关系 r-1。也就是说,如果 (ei, rj , ek) 是一个有效的三元组,那么 (ek, r−1 j , ei) 也是有效的。执行图修剪的原因有两个。首先,从 etopic 到 KG 中任意候选实体 e 的潜在推理路径的数量可能非常大。因此,我们应用图剪枝来减少搜索空间,并且只保留最短路径。其次,要求贝叶斯网络是有向无环图(DAG)。因此,图剪枝过程只去除冗余边,并保证答案实体在候选集中。
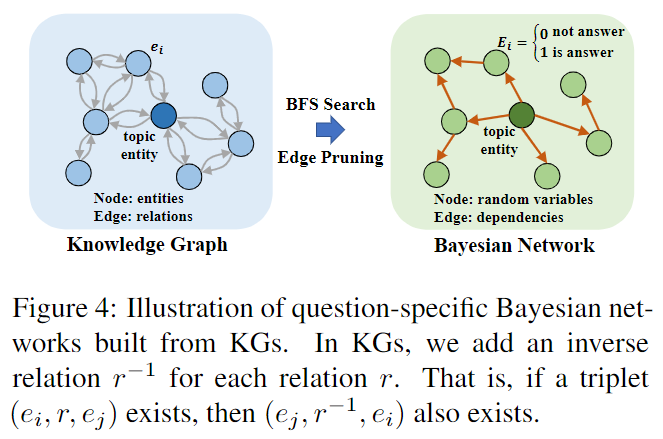
- 图 4:由 KG 构建的特定问题贝叶斯网络示意图。在 KGs 中,我们为每个关系 r 添加一个逆关系 r-1。也就是说,如果三元组 (ei, r, ej ) 存在,那么 (ej , r−1, ei) 也存在。
我们使用 ^G(etopic) 来表示给定主题实体 etopic 的修剪图。那么,我们有以下命题。命题 1. 剪枝图 G(etopic) 是一个有向无环图 (DAG)。根据 BFS 的性质,如果 G 是连通的,那么在剪枝后的图 G(etopic) 中存在一条从 etopic 开始到 e 结束的路径。此外,这条路径必须是 G 中连接 etopic 和 e 的所有路径中最短的一条。然后我们介绍这个 DAG 如何将 G(etopic) 对应到贝叶斯网络。转换后的贝叶斯网络 B(topic) 与 G(topic) 共享相同的图结构,但对节点和边的定义不同。在表 1 中,我们说明了DAG 和相应的贝叶斯网络之间的关系。 G(etopic) 中的每个实体 e 对应于 B(etopic) 中的随机变量 Xe = {0, 1},其中 Xe = {0, 1} 表示候选实体 e 的预测。给定一个问题 q,Xe = 0 表示 e 是错误答案,Xe = 1 表示 e 是正确答案。在 G(topic) 中,连接实体 ei 和 ej 的每个关系 r 对应于连接 B(topic) 中 Xei 和 Xej 的有向边,表示它们之间的依赖关系。

- 表1:DAG与对应贝叶斯网络的关系。
4.4.2 贝叶斯推理
基于贝叶斯网络 B(topic),我们可以进行边际推断来预测实体 e 是否是正确答案,可以用概率的方式表示:
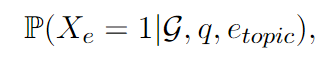
其中 G 是 KG,q 是给定问题,etopic 是主题实体。为了计算这个边际概率,我们有以下命题。
命题 2. 预测候选实体 e 的边际概率 P(Xe = 1|G, q, etopic) 可以通过变量消去(variable elimination,这种方法是概率图模型中常用的方法)计算:
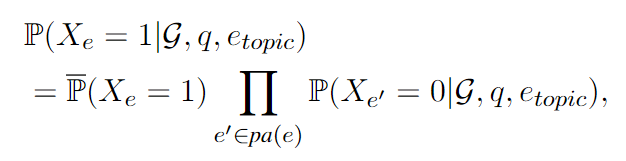
其中 pa(e) 表示 e 的父节点集合,即具有指向 e 的边的节点。第一个分量 P(Xe = 1) 是:

详细证明见附件。边际概率 P(Xe = 1|G, q, etopic) 是两个分量的乘积。第一个分量表示在所有 e 的父实体 pa(e) 都不正确的情况下实体 e 是答案的概率。第二个分量∏ e′∈pa(Xe) P(Xe′ = 0|G, q, etopic) 表示 Xe 的父节点预测的乘积。请注意,为了方便计算,在我们的实现中计算 P(Xe = 1|G, q, etopic) 时,我们假设 P(Xe′ = 0|G, q, etopic) = 1。我们对第一个组件进行如下建模:
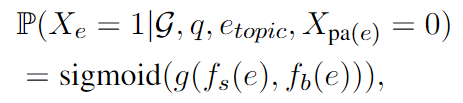
其中 fs(e) 是无意识阶段提供的证据,fb(e) 表示在贝叶斯网络中计算的分数。 g(·,·) 是结合两个分数的函数,我们在这项工作中选择 g(x, y) = x + y。分数 fb(e) 定义如下:
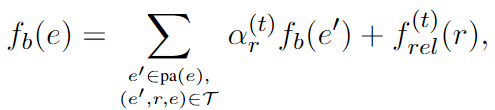
其中 f (t) rel (r) 表示关系 r 在路径解码模块中推理步骤 t 的预测分数。请注意,t 还表示 etopic 和 e 之间的拓扑距离,即从 etopic 到 e 所需的推理步骤。我们将主题实体的分数初始化为零。也就是说,fb(etopic) = 0。有意识阶段与之前的多跳推理方法在以下两个方面有所不同。首先,我们使用贝叶斯网络从概率的角度对推理过程进行建模,而之前的工作通常将 GNN 用于推理。其次,有意识阶段沿路径传播标量分数以进行多跳推理,而以前的工作通常使用 GNN 传播嵌入。
4.5 损失函数
我们使用二元交叉熵损失进行训练:
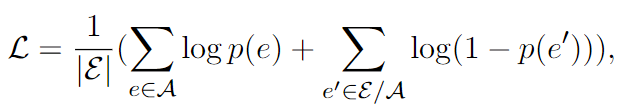
其中 E 是实体集,A 是正确答案集,p(e) = P(Xe = 1|G, q, etopic)。
5. 实验
5.1 实验设置
WebQuestionSP(2015)和 MetaQA(2018)。
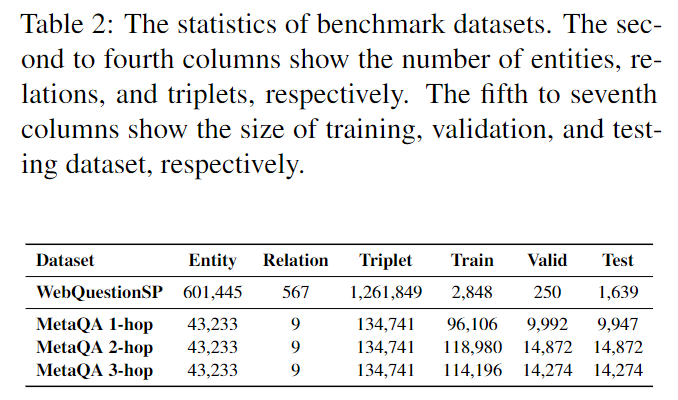
WebQuestionSP注意:小数据集,可以用 Freebase 知识图谱回答1、2跳问题。主要是1跳数据集,只有0.5%的数据是2跳的。
MetaQA:电影领域1、2、3跳问答数据集。可以采用完整版本和随机丢弃三元组版本。
5.2 主要结果
在表 3 中,我们展示了我们提出的 DCRN 在 WebQuestionSP 和 MetaQA 数据集上的结果。总体而言,我们的模型在基准数据集上明显优于最先进的模型。 WebQuestionSP 是一个小数据集,但它使用了一个大规模的 KG,它是 Freebase 的一个子集。这个数据集遵循一个归纳设置——测试集中的一些实体没有出现在训练集中。实验表明,我们的 DCRN 在 H@1 上达到了 67.8,其性能优于 GraftNet 和 KV-Mem,并且与之前最先进的 PullNet 相比表现相对较好。 MetaQA 是一个包含 1 到 3 跳问题的大型数据集。总的来说,我们的 DCRN 在所有三个子数据集上都达到了最先进的水平。在 MetaQA 1-hop 和 2-hop 上,虽然以前的一些方法表现出令人满意的性能,但它们未能达到在两个数据集上表现一致。例如,PullNet 在 MetaQA 1-hop 上仅达到 97.0,而 EmbedKGQA 在 MetaQA 2-hop 上仅达到 98.8。与以前的方法不同,我们的 DCRN 在 MetaQA 1-hop 和 2-hop 上都达到了最先进的水平。与 MetaQA 1-hop 和 2-hop 中的问题相比,MetaQA 3-hop 数据集中的问题更难回答,因为它们需要更长的推理路径才能找到答案。然而,实验表明我们的模型在 H@1 上达到了 99.3,显着优于以前的最新技术。具体来说,它对 PullNet 和 EmbedKGQA 分别获得 7.9 和 4.5。 MetaQA 3-hop 的结果说明了我们的模型在回答需要长推理路径的问题方面的有效性。
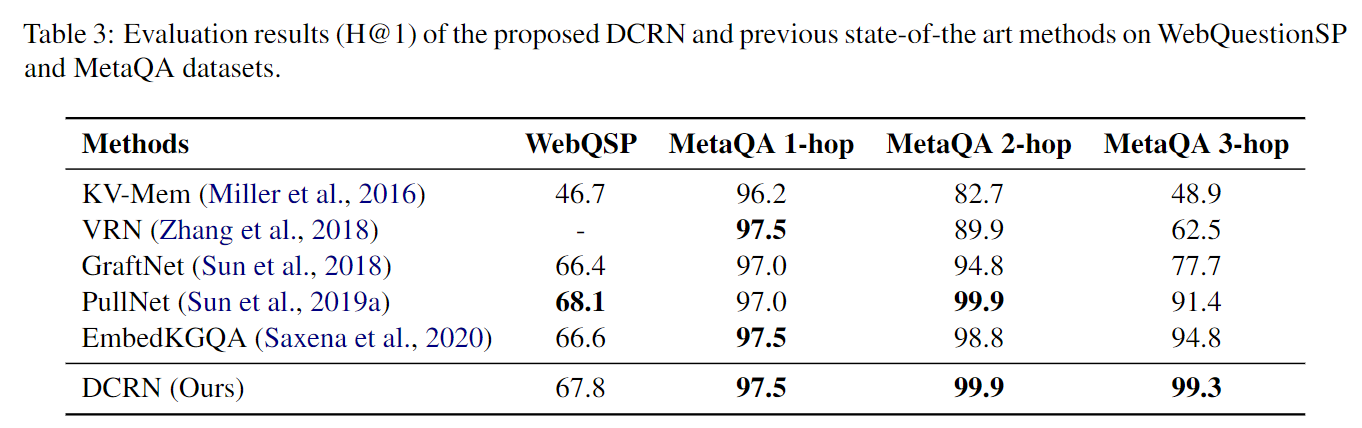
- 表3:提议的 DCRN 和之前在 WebQuestionSP 和 MetaQA 数据集上的最先进方法的评估结果 (H@1)。
我们还在“一半”设置中进行实验。在这种情况下,50% 的三元组被丢弃,这使得准确识别答案变得更具挑战性。结果如表 4 所示。实验表明我们的模型在 MetaQA 的所有子集上都达到了最先进的水平。
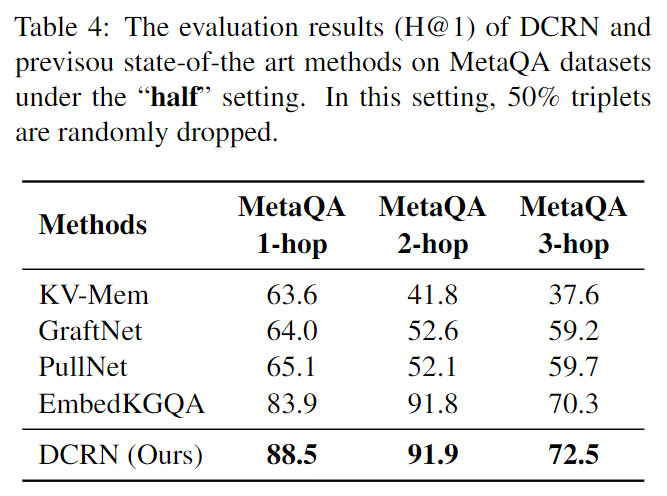
- 表4:DCRN 和 previsou state-of-the-art 方法在“half”设置下对 MetaQA 数据集的评估结果(H@1)。在此设置中,随机丢弃 50% 三元组。
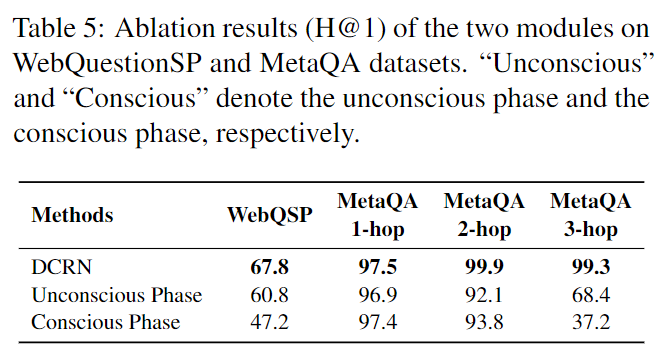
- 表5:WebQuestionSP 和 MetaQA 数据集上两个模块的消融结果(H@1)。 “无意识”和“有意识”分别表示无意识阶段和有意识阶段。
5.3 分析
总的来说,实验表明这两个阶段在我们的模型中都是不可或缺的。原因是无意识和有意识阶段旨在分别更好地利用节点级和路径级特征。这两个级别的特征对于准确的答案识别都是至关重要的。因此,两个阶段的合作带来了性能的显着提升,如表 5 所示。在 MetaQA 1-hop 和 2-hop 上,两个阶段都取得了令人满意的性能,因为候选实体的数量相对较少。此外,有意识阶段的表现优于无意识阶段。这是因为无意识阶段利用实体的粗粒度语义,而有意识阶段考虑实体之间的细粒度关系依赖。因此,在小的候选实体集上,有意识的阶段可以做出更准确的预测。在 MetaQA 3-hop 上,无意识阶段胜过有意识阶段。这是因为 3 跳问题通常具有较大的候选实体集,并且错误可以沿着推理路径传播。因此,为了做出准确的预测,DCRN 需要无意识阶段软过滤掉 227 个不相关的候选者。实验表明,通过考虑这两个阶段,DCRN 在 H@1 上达到了 99.3。我们进一步比较了 DCRN 的无意识阶段和 EmbedKGQA。 EmbedKGQA 由知识图嵌入和关系匹配两部分组成。前一部分使用问题表示作为潜在关系嵌入。与 Embed-KGQA 不同,DCRN 中的无意识阶段将问题解码为关系路径。为了说明无意识阶段的有效性,我们将其与 EmbedKGQA(无关系匹配)进行了比较,结果如表 6 所示。
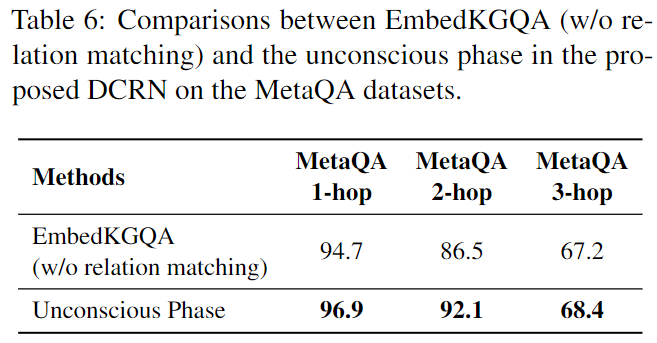
- 表 6:EmbedKGQA(无关系匹配)与 MetaQA 数据集上提出的 DCRN 中的无意识阶段之间的比较。
请注意,EmbedKGQA 使用 RoBERTa 进行词嵌入,使用 ComplEx 进行实体嵌入。为了与之前的工作进行公平比较,包括 GRAFT-Net 和 PullNet,我们使用 GloVe 进行词嵌入和 CP 用于实体嵌入,我们在我们的设置下重新实现了 EmbedKGQA(无关系匹配)。实验表明,无意识阶段在 MetaQA 的所有三个数据集上都优于 EmbedKGQA(无关系匹配),说明了我们设计在无意识阶段查询表示的有效性。
在这一部分中,我们进行了一个案例研究来说明 DCRN 中两阶段策略的有效性。在图 5 中,我们展示了 DCRN 对 2 跳问题的预测,该问题为 who is listed as screenwriter of John Derek acted films? 本题取自 MetaQA 2-hop 的测试集。左图显示了无意识阶段的预测。它表明无意识阶段成功地过滤掉了不太可能是正确答案的候选者。无意识阶段的预测为随后的有意识阶段提供了信息证据。右图显示了有意识阶段的预测。根据检索到的证据,有意识阶段成功地将正确答案排在首位。
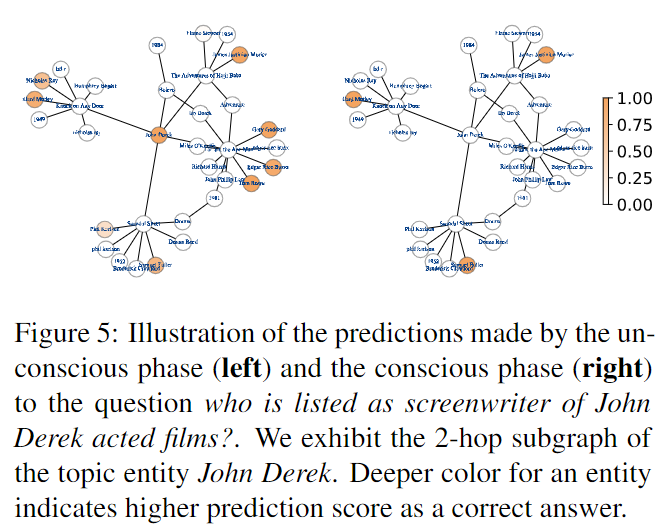
- 图 5:无意识阶段(左)和有意识阶段(右)对谁被列为约翰·德里克表演电影的编剧?我们展示了主题实体 John Derek 的 2 跳子图。实体的颜色越深表示正确答案的预测分数越高。
6. 结论
基于知识图的多跳问答旨在通过在知识图上进行多跳推理以找到答案来回答问题。在这项工作中,我们提出了一种新颖的深度认知推理网络(DCRN),其灵感来自认知科学中的双重过程理论。 DCRN 可以通过两个阶段准确识别答案——无意识阶段和有意识阶段。实验表明,我们的模型在基准数据集上优于最先进的方法。
Comments | 2 条评论
好棒的博客
(`・ω・´)博主太酷了!