






论文地址:AnswerQuest: A System for Generating Question-Answer Items from Multi-Paragraph Documents
发表在 EACL 2021 的一篇论文,主要涉及问答和问题生成内容。
0. Abstract
文章研究的内容是自动阅读理解,也就是将问答 QA 和问题生成 QG 进行结合,进而自动生成阅读理解问答列表。
1. Introduction
自动阅读理解需要两个子任务:问答 QA 和问题生成 QG。文章提出了一个端到端在线 demo,通过结合 QA 和 QG 实现给定段落自动构建问答对。demo GitHub地址:demo。
文章研究了多段文档问答,以及数据增强对问题生成的效果。
2. Question Answering
2.1 Model Overview
文档级问答系统,本文研究的是检索器-阅读器方法。一个主要问题是,段落的候选答案评分可能无法直接相比较,因为候选答案评分对每个段落的得分都是独立计算的,没有考虑到其他段落的相关性。
对此,目前比较成功的模型:BiDAF shared-norm 方法,仍然独立计算段落得分,但将所有段落进行标准化处理。首先通过 TF-IDF 获取 Top-k 段落,随后将问题和段落编码采用 GRU 和 BiDAF(双向注意流)构成的神经结构进行编码,最后通过一个线性层,预测段落答案的开始和结束标记索引,并使用一个 softmax 函数对 Top-k 段落进行归一化。
另一个方法 RE3 QA 采用了 BERT 进行编码,取得了更好的效果。
本文将 BERT 和 BiDAF shared-norm 结合,用 BERT 编码器替换 GRU BiDAF 编码器,其他部分采用 BiDAF shared-norm 结构,构建了 BERT shared-norm 模型。
模型的 k 设置为 4,softmax 预测开始和结束标记索引,并在训练期间采用共享标准化目标函数。模型可以通过末端标记是否为 0 来判断是否不能回答。
2.2 Dataset
数据集采用 SQuAD 和 NewsQA。这两个都是跨度预测阅读理解模型。
因为 SQuAD 是单段落数据集,所以按照文件对 SQuAD 段落进行组合,构建文件级问答数据。每个文件平均有 43 个段落。
因为 NewsQA 的段落边界不明确,所以设 300 标记为一个段落。每个文件平均有 2.55 个段落。
2.3 Evaluation
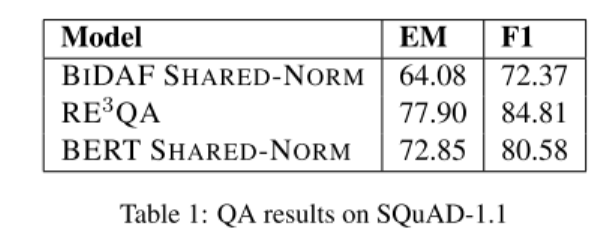
- 表1:SQuAD v1.1 上的问答系统实验结果。模型打不过 RE3QA 模型,但是这仅仅是一个数据集上的表现。由于模型是在多个数据集上训练的,所以泛化性上会更好。
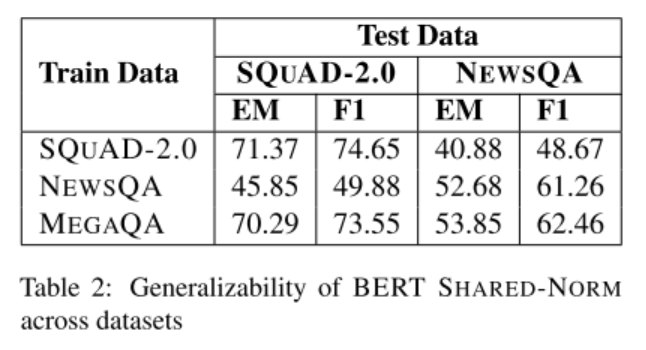
- 表2:BERT shared-norm 的泛化性评估。
3. Question Generation
3.1 Model Overview
文章研究的问题生成模型主要是编码器-解码器模型,编码器输入一个句子,解码器输出是一个问题,其对应答案在输入的句子中。文章采用问题生成模型常用的 Transformer 结构,并通过复制机制增强解码器。使用交叉熵损失函数,beam-search 设置为5。
3.2 Dataset
数据集依旧采用 SQuAD 和 NewsQA 数据集。由于要生成带有答案的问题,所以只采用了 SQuAD v1.1 和筛选的含有答案的 NewsQA 数据集。
模型输入是用 <ANSWER> </ANSWER> 注释标记的答案句子。对齐的问题是答案输出。使用 Byte-Pair-Encoding (BPE) 标记应用于输入和目标。文档和段落拆分和问答采用一样的。
3.3 Data Augmentation Experiments
为了增强问题生成模型的效果,文章采用了数据增强。这里设置了三中配置:
- STANDARD:不使用数据增强。
- RULEMIMIC:只使用数据增强。采用了一种基于语言规则的问题生成系统,包含从句简化、动词分解、主语-宾语反转和疑问词移动。
- AUGMENTED:两阶段微调。第一阶段用 RULEMIMIC 数据,第二阶段用 STANDARD 数据。
3.4 Evaluation
评估问题生成的效果采用两种方法:自动化评估和人类评估。
自动化评估采用 F1 值。人类评估采用人类打分,给出 1-4 分,由低到高是问题没有语法、语法存在问题、问题措辞问题、问题非常清晰易懂。
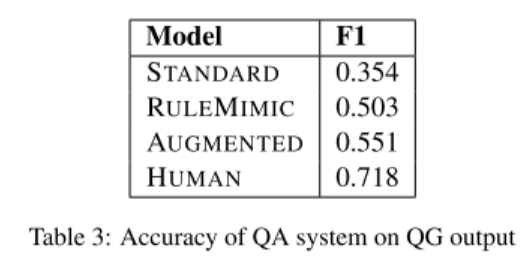
- 表3:采用 F1 值作为自动化评估的结果。
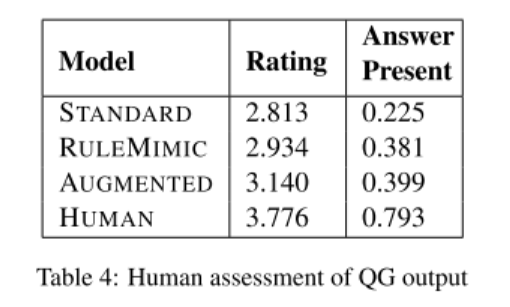
- 表4:人类评估的结果。
4. Generating Q&A Pairs
文章将试验得出的性能最好的问题生成和问答模型结合到一个系统中,该系统将上下文文本作为输入,并返回问答对列表。
4.1 Human Evaluation
为了测试生成的问答对是否覆盖了原文,进行了测试。
首先,仅给出 SQuAD 提供的人类撰写的问题,以及文本标题,要求人类给出答案。
随后,给出由 SQuAD 文本生成的问答对(问答对数量与原问题数量的比例在 1.0 到 2.4 之间),要求人类再次回答 SQuAD 提供的问题。结果当比例达到 1.7 时,效果即可达到 50% 的水平。之后再提高比例,效果基本不变。
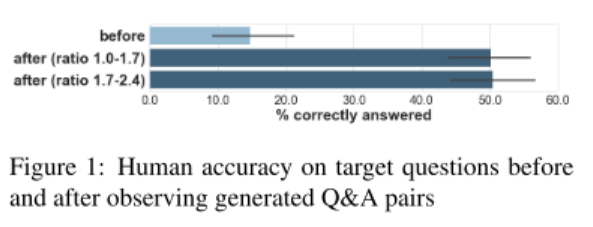
- 图1:生成问答对与原问题的比值对人类能否回答原问题的影响。
5. Conclusion and Future Work
文章提出了一种自动阅读理解的方法,将问题生成和问答结合起来,实现了很好的效果。
虽然文章基本没有进行特别大的方法创新,各个子模型的效果也不算特别优秀,但这种思路是很好的。后续可以持续关注自动阅读理解领域的进展。
Comments | NOTHING